ネットワーク上の悪質なボットを識別するための5つのステップ

企業ネットワークのセキュリティ侵害において、悪意のあるボットが深刻な被害をもたらすことは周知の事実です。ボットは、マルウェアを企業ネットワーク全体に伝播するために多く利用されます。しかし、ソフトウェアのアップデータなど、運用環境におけるルーチンプロセスの多くがボットであるため、悪意のあるボットの特定および削除は複雑になっています。
ごく最近まで、「悪い」ボットと「良い」ボットをセキュリティチームが区別するための効果的な方法は存在しませんでした。ボットを識別するとされるオープンソースのフィードやコミュニティルールはほとんど役に立たず、誤検出が多すぎます。結局セキュリティ・アナリストは、優良ボットによる無関係なセキュリティ・アラートをすべて分析・追跡するため、大変な手間となります。
Catoは、お客様のネットワークを保護する上で同様の問題に直面したため、解決のための新しいアプローチを開発しました。これは、当社のSECaaS (セキュリティ・アズ・ア・サービス)に実装された多次元的な手法で、オープンソースのフィードやコミュニティルールだけでは不可能だった72%以上の悪質なインシデントを特定することができます。
あなたのネットワークにも、同様の戦略導入が可能です。ネットワークへのアクセス、タップセンサーのようなトラフィックをキャプチャする方法、1週間分のパケットを保存できる十分なディスク容量など、ネットワーク・エンジニアにとって必要不可欠なツールが用意されています。これらのパケット・キャプチャを解析して、さらに強固なネットワークの保護方法を解説します。
悪質なボットトラフィック特定のための5つのベクトル
お話したとおり、当社は多次元的アプローチを採用しています。悪意のあるボットを正確に特定できる変数は存在しませんが、複数の方向からの評価による総合的インサイトにより、ボットをピンポイントで特定することができます。人が生成したセッションから、ネットワークに対するリスクの可能性のあるセッションまで、徐々にフィールドを絞り込むことで特定します。
当社のプロセスは次のように単純です:
- ボットと人を区別する
- ブラウザと他のクライアントを区別する
- ブラウザ内のボットを区別する
- 動作内容を分析する
- ターゲットのリスクを判断する
次に、それぞれのステップについて解説します。
通信頻度の測定によりボットと人間を区別する
ほとんどのボットは、コマンドの受信、キープアライブ信号の送信、データの流出などを行う必要があるため、ターゲットと継続的に通信する傾向があります。ボットと人間を区別するための最初のステップは、ターゲットに対して繰り返し通信しているマシンを識別することです。
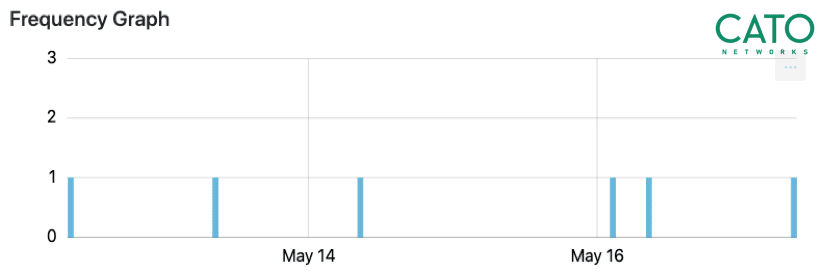
つまり、多くのターゲットと定期的かつ継続的に通信しているホストを見つけることが重要だということです。私たちの経験上、1週間分のトラフィックがあれば、十分にクライアントとターゲットの通信の性質を判断することができます。統計的に、通信が均一な性質をもっていればいるほど、ボットによって生成されている可能性が高くなります(図1参照)。
サイバーセキュリティ・マスタークラスに参加する:虚偽の情報からディープフェイクまで
ブラウザと他のクライアントを区別する
ボットがマシンに存在するという情報だけでは不十分です。お話したように、ほとんどのマシンは何らかのボット・トラフィックを発生させています。そこで、ネットワーク上で通信しているクライアントの種類を確認する必要がある。一般的に、「良い」ボットはブラウザ内に存在し、「悪い」ボットはブラウザ外で動作します。
OSには、トラフィックを生成するクライアントやライブラリの種類があります。例えば、「Chrome」、「WinInet」、「Java Runtime Environment」はすべて異なるクライアント・タイプです。最初は、クライアントのトラフィックは同じに見えるかもしれませんが、クライアントを区別し、コンテキストを強化する方法がいくつかあります。
まず、アプリケーション層のヘッダを見てみましょう。ほとんどのファイアウォールでは、どのアドレスにもHTTPとTLSを許可しているため、多くのボットがこれらのプロトコルを使ってターゲットと通信しています。ブラウザ以外で動作するボットは、クライアントが設定したHTTPとTLSの機能群を識別することで特定できます。
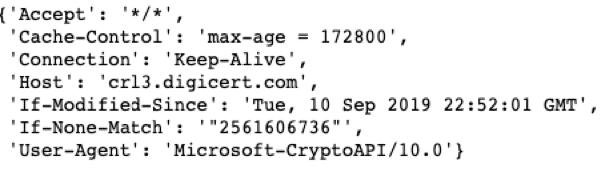
あらゆるHTTPセッションは、リクエストを定義する一連のリクエストヘッダと、どのようにサーバーがそれを処理すべきかの情報を持っています。それらのヘッダー、順番、値は HTTPリクエストの構成の際に設定されます (図 2 参照)。同様に、暗号スイート、拡張リスト、ALPN (Application-Layer Protocol Negotiation)、楕円曲線などのTLSセッション属性は、暗号化されていない最初のTLSパケット、「client hello」パケットで確立されます。HTTPとTLS属性の異なるシーケンスをクラスタリングすると、異なるボットが示されるでしょう。
例として、これにより異なる暗号スイートを使用したTLSトラフィックを発見することができます。これは、トラフィックがブラウザの外部で生成されていることを示すもので、人間離れしたアプローチであるため、ボットトラフィックの良い指標となります
ブラウザ内のボットを区別する
悪意のあるボットを識別するもう一つの方法として、HTTPヘッダーに含まれる特定の情報に注目することが挙げられます。通常インターネットブラウザには、明確かつ標準的なヘッダーイメージがあります。通常のブラウジングセッションでは、ブラウザ内でリンクをクリックすると、そのURLに対する次のリクエストに含まれる「referrer」ヘッダが生成されます。ボットトラフィックは通常、「referrer」ヘッダーを持たないか、最悪の場合、偽造します。すべてのトラフィックフローで似たように見えるボットは、悪意の兆候を示している可能性があります。

「User-agent」は、最もよく知られたリクエストを開始したプログラムを表す文字列です。fingerbank.orgなどのさまざまなソースは、ユーザーエージェントの値を既知のプログラムバージョンと照合します。この情報を利用することで、異常なボットを特定することができます。例えば、最近のブラウザは、ユーザーエージェントの欄に「Mozilla 5.0」という文字列を使用しています。Mozillaのバージョンが低いか、全く存在しない場合は、異常なボットのユーザーエージェント文字列であることを示しています。信頼できるブラウザは、ユーザーエージェントの値なしにトラフィックを生成することはありません。
動作内容を分析する
また、ボットの検索はHTTPとTLSのプロトコル以外を調べることで可能です。例えば、IRCプロトコルは、悪意のあるボットの活動によく使われます。また、既知のポート上で独自の未知のプロトコルを使用する既知のマルウェアサンプルも見つかっており、この場合はアプリケーション識別を使用することでフラグを立てることができます。
さらに、インバウンドまたはアウトバウンドといったトラフィックの方向も重要な意味を持ちます。インターネットに直接接続されているデバイスは、常にスキャン動作にさらされているため、これらのボットはインバウンドスキャナーでしょう。一方、スキャニング活動がアウトバウンドする場合は、スキャニングボットに感染したデバイスであることを示しています。スキャンされるターゲットにとって有害であり、これによって組織のIPアドレスの評価を失墜する可能性があります。以下のグラフは、トラフィックフローが短時間で急増していることを示しており、スキャンボットの活動である可能性があります。これは、フロー/秒の計算式を使用することで分析できます。
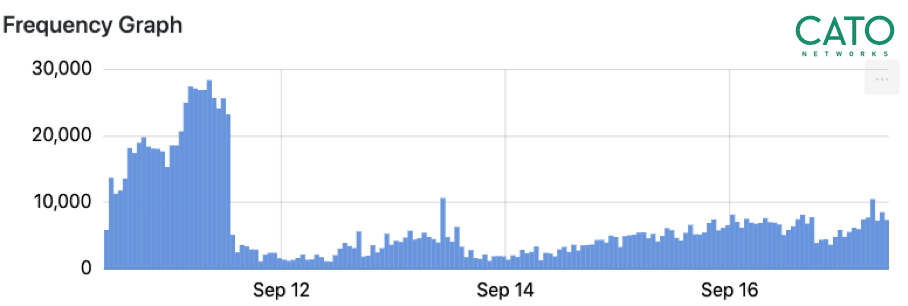
ターゲットの分析:宛先を知る
ここまで、クライアントとサーバーの通信頻度やクライアントの種類からボットの指標を探してきました。ここでは、「宛先」または「ターゲット」についてお話します。悪意のあるターゲットを特定するためには、「ターゲットの評価」と「ターゲットの知名度」の要素を考慮する必要があります。
ターゲットの評価は、多くのフローから収集した履歴に基づき、ドメインが悪意あるものである可能性を計算します。評価は、サードパーティのサービスにより決定されるか、ユーザーがターゲットを悪意あるものとして報告するたびに記録される自己計算によって決定されます。
しかし、ターゲットの評価を決定するためには、URL評価フィードなどの単純なソースだけでは不十分なことが多くあります。毎月、何百万もの新しいドメインが登録されています。そのため、ドメイン評価レピュテーションメカニズムはそれらを適切に分類するための十分なコンテキストを持たず、高い確率で誤検出を引き起こします。
まとめ
以上のことを踏まえると、セッションは次のように大別されます:
- 人間ではなく、機械によって生成されたもの
- ブラウザ以外で生成された、または異常なメタデータを含むブラウザトラフィックでること
- 知名度のないターゲット、特に分類されていない、または悪意があるとマークされているターゲットと通信すると、疑わしく思われる可能性があります。正規のボットや優良ボットは、知名度の低いターゲットと通信すべきではありません
Andromedaマルウェアのネットワーク下における実践
これらの方法を組み合わせることで、ネットワーク上のさまざまな種類の脅威を発見することができます。Andromedaボットの検出を例として見てみましょう。Andromedaは、他の種類のマルウェアのダウンローダーとして頻繁に利用されています。当社では、これまで説明した5つのアプローチのうち、4つのアプローチを用いてデータを分析し、Andromedaを特定しています。
ターゲットの評価
私たちは「disorderstatus[.]ru」が、複数の評価サービスによって悪意あるドメインと見做されていることに気づきました。様々なソースから見たこのサイトのカテゴリーは「既知の感染源、ボットネットワーク」ですが、特定のホストがAndromedaに感染しているかどうかが示されていないため、ユーザーがそのサイトを閲覧しているだけの可能性も捨てきれません。さらに前述の通り、URLは「不明」または「悪意がない」に分類されます。
ターゲットの知名度
1万人のユーザー中、このターゲットと通信しているユーザーのマシンは1台だけで、これは非常に珍しいことです。そのため、このターゲットの知名度は低くなっています。
通信頻度
クライアントとターゲット間において、1週間にわたって3日間の連続したトラフィックが検出されました。このように繰り返し通信が行われていることも、ボットであることを示す指標となっています。
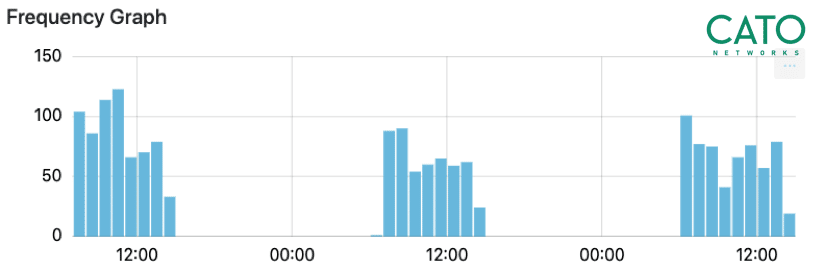
ヘッダーの解析
要求しているユーザーエージェントは「Mozilla/4.0」であり、最新ブラウザではないことから、ユーザーエージェントはボットである可能性が高いことが示されています。

結論
IPネットワーク上のボット検出は容易ではありませんが、ネットワークセキュリティの実践やマルウェア検出が基礎となりつつあります。今回紹介した5つのテクニックを組み合わせることで、悪意のあるボットをより効率的に検出することができます。
セキュリティサービスの詳細についてはこちらをご覧ください。Catoのマネージド脅威検出・対応サービスについてはこちらをご参照ください。