




強靭な都市を築く:CatoはいかにPoPの変更を安全に展開するか


低価格な住宅と最先端インフラをうたう新しい都市を想像してみてください。人々は期待を胸に移り住みますが、実際には道路は慢性的に渋滞し、毎晩のように停電が発生し、水圧は予告なく低下します。どこで何が壊れているのかを把握するためのカメラやセンサーもありません。次の「改善」を街に適用する前に安全に検証できる中央の管制室も存在しません。計画上どれほど魅力的に見えても、インフラが不安定で保守が困難な都市に、人は長く留まりません。
グローバルなSASE基盤は、その都市と同じです。ユーザー、拠点、アプリケーションは日々この基盤に依存しており、どんな小さな道路の陥没であっても即座に分かります。
以前のブログ「Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations」では、グローバルプラットフォームにおける単一の変更が、どのように広範な障害へ波及し得るかを取り上げました。本稿ではさらに一段深く踏み込み、運用そのものに焦点を当てます。Catoが自社のPoP(Point of Presence)に対する変更をどのように展開しているのか、その舞台裏を紹介します。クラウド全体を一度にアップグレードするのではなく、段階的かつフェーズごとに展開する方式、事前のステージング検証、展開後の確認プロセス、そして各フェーズを明確な指標と結び付けた高度なモニタリングです。目的は明確です。安定性をあらかじめ設計に組み込み、リスクを制御しながら継続的なイノベーションを実現すること。その結果として、お客様のトラフィックが実験台になることを防ぎます。
Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations | Read the Blogなぜロールアウト戦略が重要なのか
近年、大手クラウドおよびエッジプロバイダーで発生した大規模障害は、単一のグローバル変更がいかに危険であるかを示しています。設定の更新や新しいソフトウェアビルドを全環境へ一斉に展開すると、運用担当者が対応する間もなく、数分で世界規模の障害へ発展する可能性があります。Cloudflare障害の分析でも、単一の設定リフレッシュが短時間でグローバルに伝播した結果、ロールアウト管理や監視に十分なガードレールがなければ、成熟したネットワークであっても安定性を損なうことが示されました。
だからこそ、Cato SASEでは、各段階で堅牢な監視と検証を組み込んだ、段階的かつフェーズ単位のロールアウトを採用しています。新バージョンをすべてのPoPに一度に適用するのではなく、変更はフェーズおよびウェーブ単位で導入されます。
- 各フェーズは、APAC、EMEA、アメリカ、イスラエル、日本など、異なる地域のPoPを組み合わせた構成になっています。
- ロールアウトは数時間単位ではなく、複数週間にわたって実施されます。初期フェーズは意図的に小規模に設定され、当社の主要なサービスおよびインフラの主要な構成パターンをすべて含めます。これは、テスト段階では顕在化しない特定の問題を早期に検知するための安全網として機能します。
- 各フェーズ内でも、同時に再起動されるPoPが過度に増えないよう、さらにサブフェーズへ分割することが可能です。
私たちは都市全体を一度に再構築することはしません。明確な判断基準のもと、地区ごとに近代化を進め、前進すべきか、あるいは一時停止すべきかを見極めながら展開しています。
展開前のガバナンス
変更に対するガバナンスは、安定運用を支える第一の防御層です。PoP向けの新しいソフトウェアバージョンは定期的に作成されますが、「ビルドが存在すること」と「本番トラフィックを処理できること」は明確に区別されています。新しいブランチやパッチは、いずれも次のプロセスを経なければなりません。
- 本番承認前に、手動テストと自動検証の双方を含むバージョン選定
- ネットワークオペレーション部門への正式な引き継ぎ
- 本番PoPに到達する前に、変更管理システム上での正式承認
- 実際の実行に対するリアルタイムの権限付与
現場で確認された問題に対応するためのパッチであっても、同じ規律の下で扱われます。リスクや緊急度に応じて、初期フェーズを再展開することもあれば、後続フェーズのみを進める判断をすることもあります。いずれの場合も、新しいリビジョンをロールアウト計画に組み込む前には、明示的な承認ステップが必須です。
顧客にとって重要なのは次の点です。検証および承認済みのバージョンのみが、本番トラフィックを処理します。
有効化前のステージング
バージョンが承認された後も、直ちに再起動へ進むわけではありません。展開は二つの主要なステップに分けられます。
- ステージング(ウォームアップ):新しいソフトウェアは、事前に管理チャネルを通じて対象PoPへ配布されます。
- ユーザーへの影響はありません。
- 再起動は行われません。
- メンテナンスウィンドウ外でも実施可能です。
展開ウィンドウに入る時点で、PoPにはすでに新しいバイナリがローカルに配置されています。これにより、実際のメンテナンス作業時間が短縮され、リスクも低減されます。
- メンテナンスウィンドウ内での展開:フェーズ単位での実際のロールアウトは、計画されたメンテナンスウィンドウ内で実施されます。この段階では、該当PoPのサービスを再起動し、トンネルを再確立します。
- 同時に更新されるPoPの数を制御するため、フェーズ単位またはサブフェーズ単位で実施可能です。
- 制御されたフェイルオーバーを伴い、新バージョンをアクティブとして稼働させつつ、旧バージョンをバックアップとして保持します。
この「配布」と「有効化」の分離は、重要なレジリエンス設計パターンです。ユーザーが変更を体感するタイミングや、同時に影響を受けるPoPの数をより精緻に制御できます。図1では、展開フェーズの全体像を示す高レベルビューの一例を紹介しています。そこでは、当該フェーズに含まれるすべてのPoPが、現在稼働しているソフトウェアリビジョンごとに色分けされています。Catoのネットワークオペレーターは、すべてのPoPが目標バージョンに到達しているか、旧リビジョンのままのPoPが残っていないか、展開後に応答を返していないPoPが存在しないかを即座に把握できます。
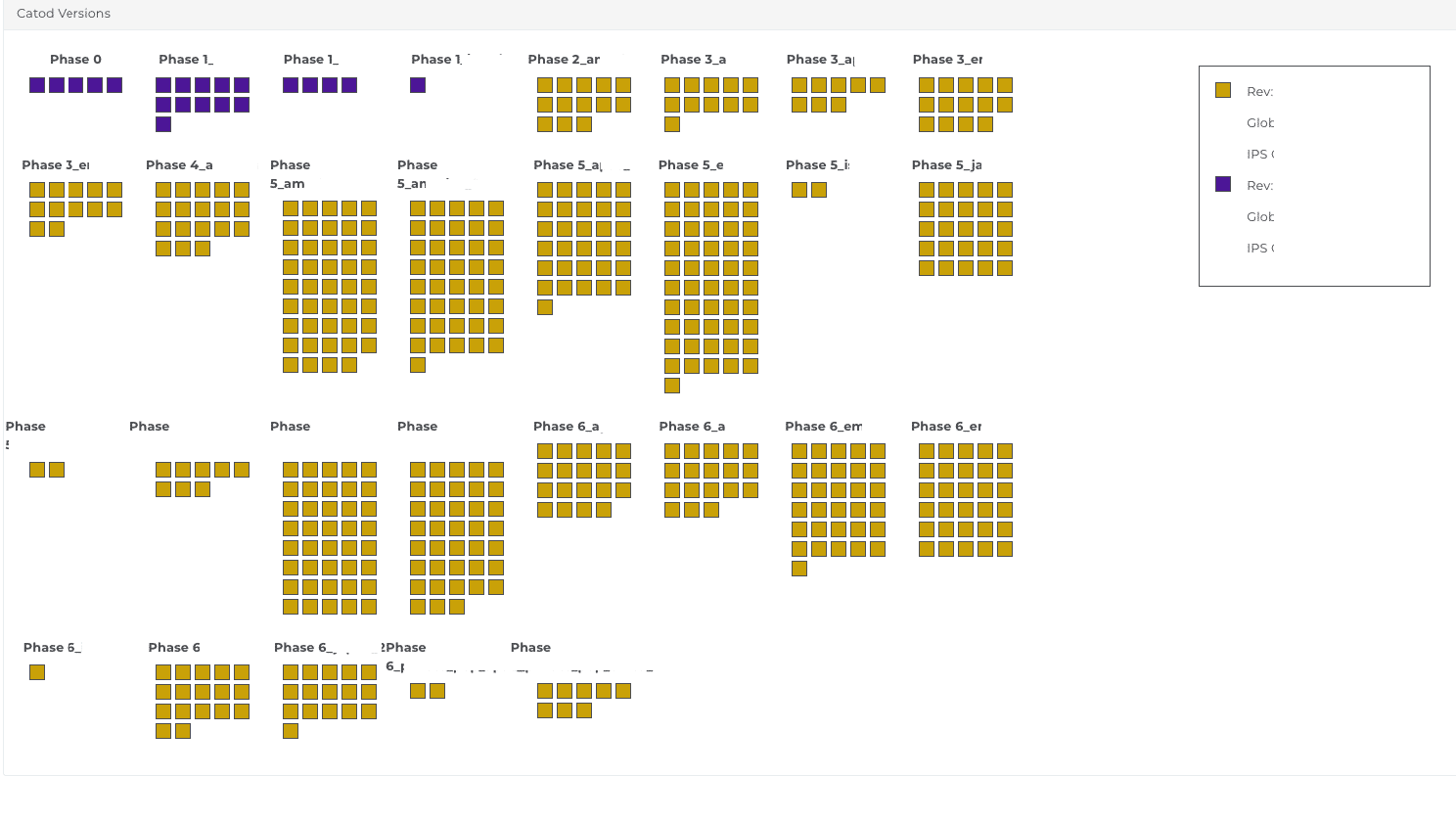
図1:フェーズごとのロールアウト検証ビューの例
各フェーズを影響を限定した小規模な検証として扱う
私たちは、各フェーズを、明確な変更前後を伴う小規模で統制された検証として位置づけています。
フェーズまたはサブフェーズの展開前には、次の確認を行います。
- 当該フェーズに含まれるPoPの現在数を記録する。
- それらのPoPにおける既存のサービスステータスおよびアラート状況を確認する。
- ほかの変更作業のため既にメンテナンス中のPoPを特定し、一時的に対象から除外するかどうかを判断する。
この時点の状態が、展開後の比較基準となるリファレンスポイントになります。
展開後には、次の点を検証します。
- 対象となったすべてのPoPが、意図したソフトウェアリビジョンで稼働していること。
- フェーズ内のPoP数が減少していないこと(正しく復旧できなかったPoPが存在しないことの確認)。
- 展開前のスナップショットには存在しなかった新たなサービス障害が発生していないこと。
これらの確認を支えるため、ダッシュボードとターゲット型アラートの双方を活用しています。
図2では、PoPの健全性および展開後監視ダッシュボードを示しています。稼働時間、トンネルの安定性、レイテンシ、各種サービスステータスといった主要な健全性指標を強調表示したPoP監視ダッシュボードのスナップショットです。このビューにより、CatoのNOC(Network Operations Center)は、展開後のフェーズ全体の健全性を迅速に確認し、同一グループ内で異なる挙動を示すPoPを即座に特定できます。
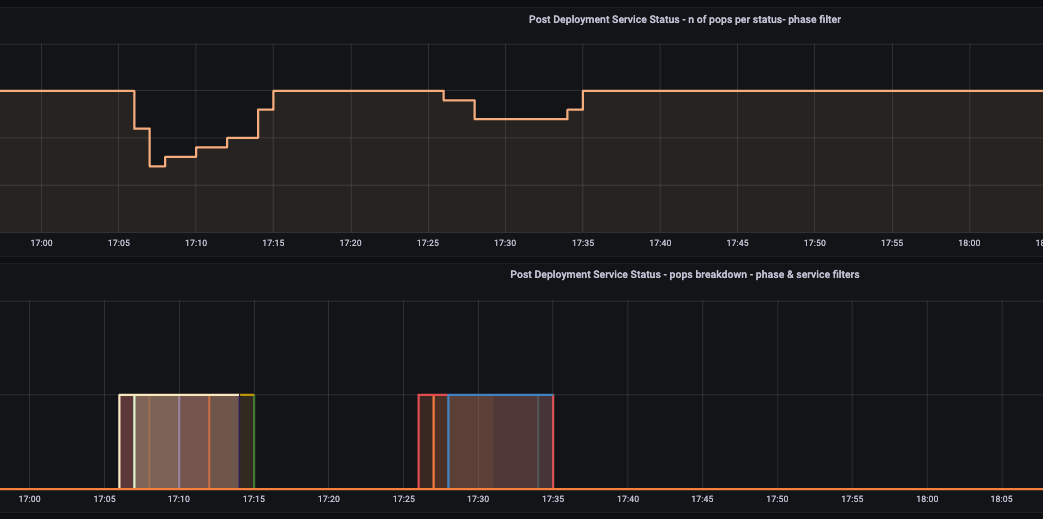
図2:PoP健全性および監視ダッシュボード
変更が頻繁に行われる環境では、人の目だけでは見落としが生じる可能性があります。そのリスクを低減するため、私たちは展開直後の時間帯に特化した専用監視を実施しています。フェーズ更新の直後に、特定のPoPで新たなサービスステータスや異常が発生した場合、そのイベントはアラートとして発報され、当該展開コンテキストと紐づけられます。これにより、極めて重要な問い ―「この問題は新しいコードが引き起こしたものか、それとも既に存在していたものか」― に迅速に答えられます。少しでも疑念がある場合は、チームが原因を調査する間、次のフェーズを一時停止することも可能です。
あらかじめ組み込まれた安定性の仕組み
段階的なロールアウトと監視は重要な要素ですが、それだけがすべてではありません。問題が実際に発生したときに何ができるか、それもまた安定性を左右します。
舞台裏では、次のような仕組みを備えています。
- 障害シナリオに備えたスタンバイアップグレード:場合によっては、代替となる検証済みリビジョンをPoPに事前配置し、有効化せずに待機させることができます。PoPが想定された障害状態やソフトロックアップに陥った場合、自動的にそのスタンバイリビジョンへ切り替えることが可能です。次回の通常展開までに問題が発生しなければ、スタンバイパッケージは削除されます。これにより、動的な状況下でも安定性を守るための追加手段が確保されます。
- 迅速な緩和措置とロールバック機能同一ロケーション内で、あるPoPのみが他と異なる挙動を示した場合、運用担当者は当該PoPに限定してサービス再起動を行い、原因を調査しながら正常状態を回復できます。より重大な問題や、新リビジョンが繰り返し障害を引き起こす場合には、ソフトウェアおよび重要な設定を含む既知の正常スナップショットへロールバックできます。可用性に影響するハードウェア障害についても監視および自動対応が行われ、必要に応じてエンジニアリング部門へ引き継がれます。
私たちの目的は、ソフトウェアに不具合が起こらないと装うことではありません。問題を封じ込め、迅速に復旧し、ネットワーク全体を安全に保つための明確かつ実証済みの手段を備えることです。
セキュリティおよびコンプライアンスフレームワークとの整合性
本稿はシステムの安定性と顧客体験に焦点を当てていますが、ここで紹介した実践は、重要インフラ事業者に求められる現代のセキュリティおよびコンプライアンス要件とも整合しています。
- PCI DSS本番環境に適用する前にバージョンを承認する方法、管理されたメンテナンスウィンドウを用いること、そして各フェーズ後に挙動を検証することは、変更管理の文書化、本番前の変更テスト、対象システムの継続的な監視といったPCI DSSの要件と整合しています。PCI DSS v4.0.1認証の取得について解説した専用ブログでは、Cato SASEを支える統制フレームワークを詳細に説明しています。本稿で取り上げている段階的なロールアウトおよび監視の実践は、その運用面にあたります。すなわち、変更管理や監視に関する文書上の要件を、PoPにおける日々の運用行動へと具体化する取り組みの一部です。
- SOC 2(セキュリティおよび可用性):SOC 2は、正式な変更管理、職務の分離、そしてサービスの可用性を守るための継続的な監視を重視しています。私たちが実施しているステージング、段階的なロールアウト、展開後の監視は、クラウドサービスの運用に求められるまさにその種の運用規律を体現するものです。
- ISO/IEC 27001、27017、27018、27701ISO 27001は、情報システムへの変更を統制された方法で管理し、システムを異常の有無について監視することを求めています。本稿で説明した、承認から段階的なロールアウト、検証、ロールバックに至る多段階のプロセスこそが、Catoがこれらの原則をグローバルなSASEクラウドにおいて具体的に実装している方法です。
- NISTに基づくベストプラクティス:安全な運用および構成管理に関するNISTの指針は、影響範囲の最小化、ロールバック手段の確保、そして変更後のシステムを綿密に監視することを重視しています。私たちの段階的で監視可能かつ可逆性を備えた展開戦略は、まさにその考え方に基づいて設計されています。
顧客にとって重要なのは、Cato SASEの運用が単なる安心感や可用性の確保にとどまらないという点です。そこには、監査人やセキュリティチームがすでに「適切な実務」として認めている運用の型が、確実に組み込まれています。
これが意味すること
以上を踏まえると、このアプローチによって得られる価値は次のとおりです。
- 影響範囲の抑制:単一の変更を一度に全体へ適用することはありません。フェーズおよびサブフェーズで段階的に進めることで、想定外の問題が発生しても影響を限定できます。
- 予測可能な変更タイミング:展開は計画されたメンテナンスウィンドウ内で実施されます。事前にステージングを完了しておくことで、実際の作業時間を最小限に抑えます。
- 高い運用可視性:ダッシュボードと専用アラートにより、各展開フェーズの前後および実行中に何が起きたのかを明確に把握できます。
- 迅速かつ統制の取れた復旧手段:パッチ適用、スタンバイアップグレード、サービス再起動、ロールバックなど、必要に応じて安定性を回復するための複数の選択肢を備えています。
- 継続的な進化と安定性の両立:Catoはプラットフォームを継続的に改善しながら、SASE環境を安定的かつ可視化された状態に保ち、現代の規制要件にも適合させます。
言い換えれば、SASE基盤という「都市」は単に拡大しているのではありません計画的に設計され、可視化され、監視されながら進化しています。新しい道路を敷いても、あなたのトラフィックは滞ることなく流れ続けます。
パートナーの真価:顧客のM&Aに伴う混乱を、成長の機会へ


アラートから実効的なアクションへ: Dynamic Prevention

なぜ独立したセキュリティテストが重要なのか:Cato SASE の有効性評価から得られる教訓