





機密データが「画像」になるとき:DLPにおける機械学習型画像分類の導入


医師のカーター先生は、長い勤務を終えた後、患者のX線画像を通常の画像ファイルとして書き出し、診断を再確認するためにAIアシスタントへドラッグ&ドロップします。その画像には、患者の氏名とIDが含まれていました。街の別の場所では、旅行代理店勤務のジェイソンが複数のパスポートをスキャンし、予約情報を自動入力させるためにその画像をAIツールへアップロードしています。サポートセンターでは、サラがクレジットカードを素早く撮影し、番号を打ち直す手間を省くためにAIサービスへ送信します。彼らはいずれも、自分がデータ侵害を引き起こしているとは思っていません。ただ業務を効率化しようとしているだけです。しかしその裏では、保護対象医療情報(PHI)、決済情報、身分証明書といった機密データが、組織の統制が及ばない外部AIツールへ静かに流出しています。登場人物は架空ですが、このような状況はすでに、AI主導のワークフローや“便利な”アシスタントが日常業務に組み込まれた現代において、現実の一部となっています。
このギャップを解消するため、私たちはCato DLPの一機能として、機械学習(ML)を活用した画像分類機能を新たに導入しました。Catoプラットフォームは、医療画像、クレジットカード、パスポート画像といった機密性の高い視覚コンテンツを検知し、ポリシーに基づいてAIアプリやその他のクラウドサービスへのアップロードをブロックできます。単にテキスト中の機密情報を検査するのではなく、画像そのものを対象に検知と制御を行います。実際の動作を示すため、医療画像をChatGPTにアップロードしようとした際に、リアルタイムで遮断するデモ動画も用意しています。これにより、HIPAA違反が発生する前に未然に防止できる様子を確認できます。同様に、GDPRやPCI DSSといった他の規制への違反リスクの低減にも貢献します。
OCR依存型DLPでは不十分な理由
従来のDLPは、画像に含まれる情報を扱う際、光学文字認識(OCR)によって可読テキストを抽出し、そのテキストをパターンベースの検出ロジックや、機械学習/自然言語処理(ML/NLP)を用いたDLPエンジンで解析するという手法を採ってきました。クレジットカード番号、各種ID、保護対象医療情報(PHI)などに類似する文字列を検出するアプローチです。
しかし、この方法には本質的な限界が二つあります。
- OCRの信頼性の問題:ぼやけた写真、コントラストの低い画像、斜めから撮影された書類、手書き文字、視覚的な重なり要素などは、テキスト抽出を不完全あるいは断片的なものにしてしまいます。抽出されたテキストが不正確であれば、DLPエンジンは一致を検知できず、アラートも発生しません。
- テキストに依存しない機密情報の存在:医療画像、ネットワーク構成図、ホワイトボードの写真、各種の知的財産(IP)など、多くの機密情報は文字情報に依存していません。このようなコンテンツは、そもそもOCRでは識別できません。
その結果として生じるのは、検知漏れの増加と、画像を起点としたデータ流出に対する重大な盲点です。
トランスフォーマーモデル:Catoの画像DLPを支える基盤技術
Catoの新たな画像DLP機能の中核には、トランスフォーマーを基盤としたビジョン・ランゲージモデルがあります。従来のように「このスクリーンショットからOCRでどの文字を抽出できるか」を起点にするのではなく、画像そのものが何を意味しているのかを理解するアプローチを採っています。
私たちは、OpenAIが提唱したCLIPに代表される、CLIP系のマルチモーダルモデルを基盤としています。CLIP(Contrastive Language–Image Pre-training)は、数億規模の画像とテキストのペアを用いて学習され、視覚情報と自然言語概念を結び付ける能力を獲得しています。画素パターンや固定的なルールに依存するのではなく、「MRI画像」「パスポート写真」「テーブルの上のクレジットカード」といった高次の概念を理解できる点が特長です。
技術的には、CLIPは二つのエンコーダーで構成されています:
- 画像エンコーダー:画像をベクトル(埋め込み表現)へ変換する
- テキストエンコーダー:短いフレーズ(例:「公的身分証明書」「MRI画像」など)を、同一のベクトル空間内の埋め込みへ変換する
両エンコーダーは共通の潜在空間に埋め込みを生成します。そのため、画像と説明文のベクトル同士を比較することで、両者の一致度を直接測定できます。埋め込みの距離が近いほど、その画像が該当する概念を表している可能性が高いと判断できます(図1参照)。
Catoの画像分類エンジンの内部構造
私たちは、このCLIPによる埋め込み空間を基盤として、DLPおよび規制対象データ向けに特化した画像分類エンジンを構築しました。
まず、顧客にとって重要性の高い機密カテゴリを厳選したサポートセットを用意します。具体的には、次のようなカテゴリが含まれます。
- 医療画像(MRI、CT、X線画像)
- クレジットカードなどの決済カード
- パスポート、各種公的身分証、社員証
- システム構成図やホワイトボードのスケッチ
そして各カテゴリは、次の要素によって表現されます。
- 複数の代表的なサンプル画像
- 簡潔なテキスト記述
新しい画像を検査する際、処理パイプラインは以下の手順を踏みます。
- 画像エンコーダーを用いて、対象画像の視覚情報から埋め込み(ベクトル表現)を生成する。
- 生成された埋め込みを、サポートセットに含まれる画像埋め込みおよびテキスト埋め込みの双方と比較する。
- コサイン類似度を用いて、新規画像が各機密カテゴリにどの程度近いかを評価する。
類似度スコアを最終的な判定へと変換するために、私たちは固定半径型のk近傍法(fixed-radius nearest neighbors)を応用した手法を採用しています。具体的には、埋め込み空間上であらかじめ定義した「十分に近い」範囲内の近傍のみを考慮し、特定カテゴリの周囲で強い局所的一致が確認された場合にのみ、その画像を機密コンテンツとして分類します。
この固定半径アプローチにより、ノイズによる誤検知や過度に確信的な誤判定を抑制できます。その結果、OCRが機能しない場合や、そもそもテキストを含まない画像であっても、機密性の高いコンテンツを高い信頼性で識別できる堅牢な画像ML分類器を実現しています(図1参照)。
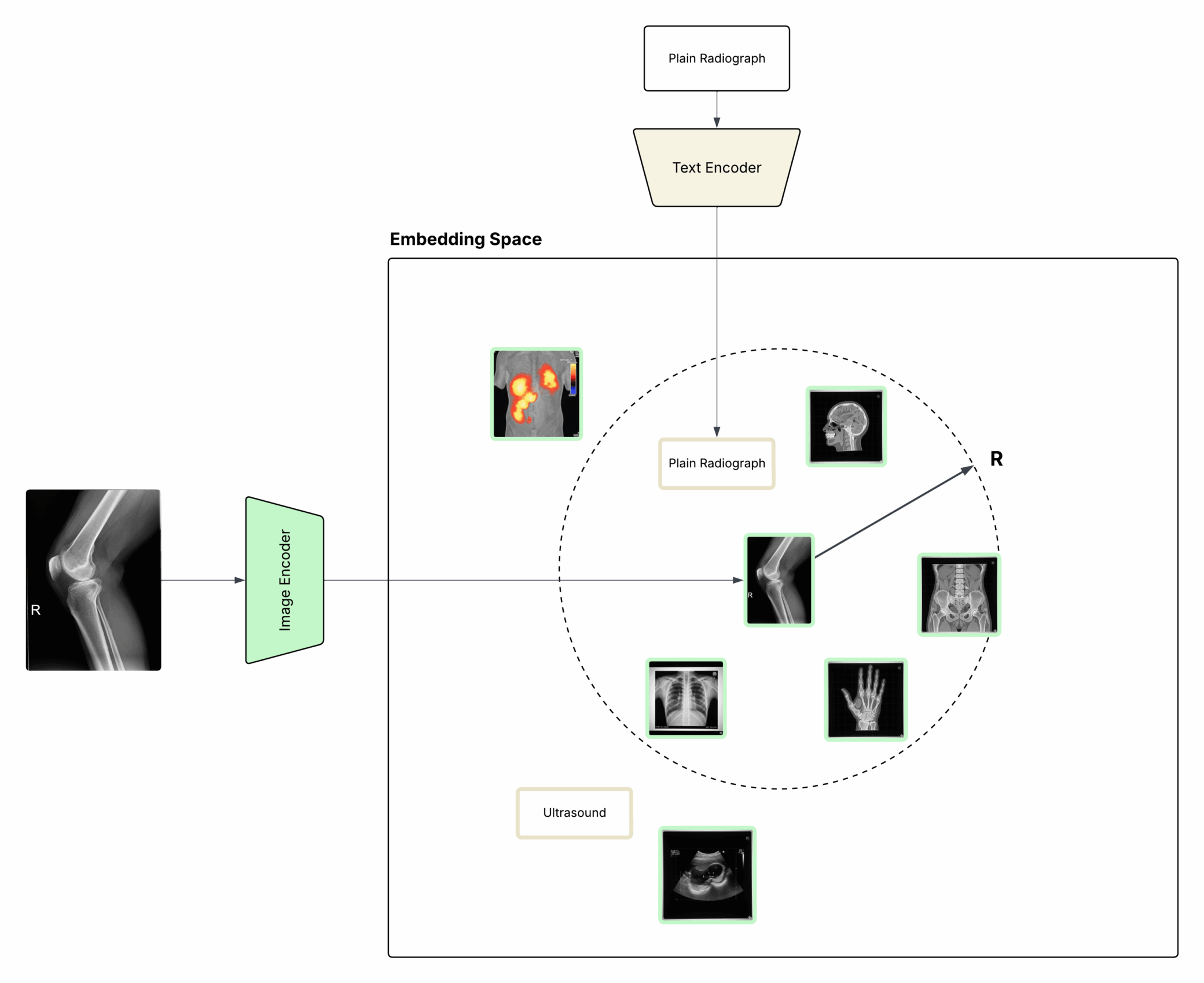
図1:画像とテキストは同一の埋め込み空間に写像され、意味的な一致判定が可能になる
MLによる検知を強制力のあるポリシーへと転換する
図2に示すように、ユーザーは患者のX線画像をAIアプリへ容易にアップロードできます。分析を目的とした行為であっても、その結果として保護対象医療情報(PHI)が、組織の統制外にある第三者サービスへ送信されてしまう可能性があります。
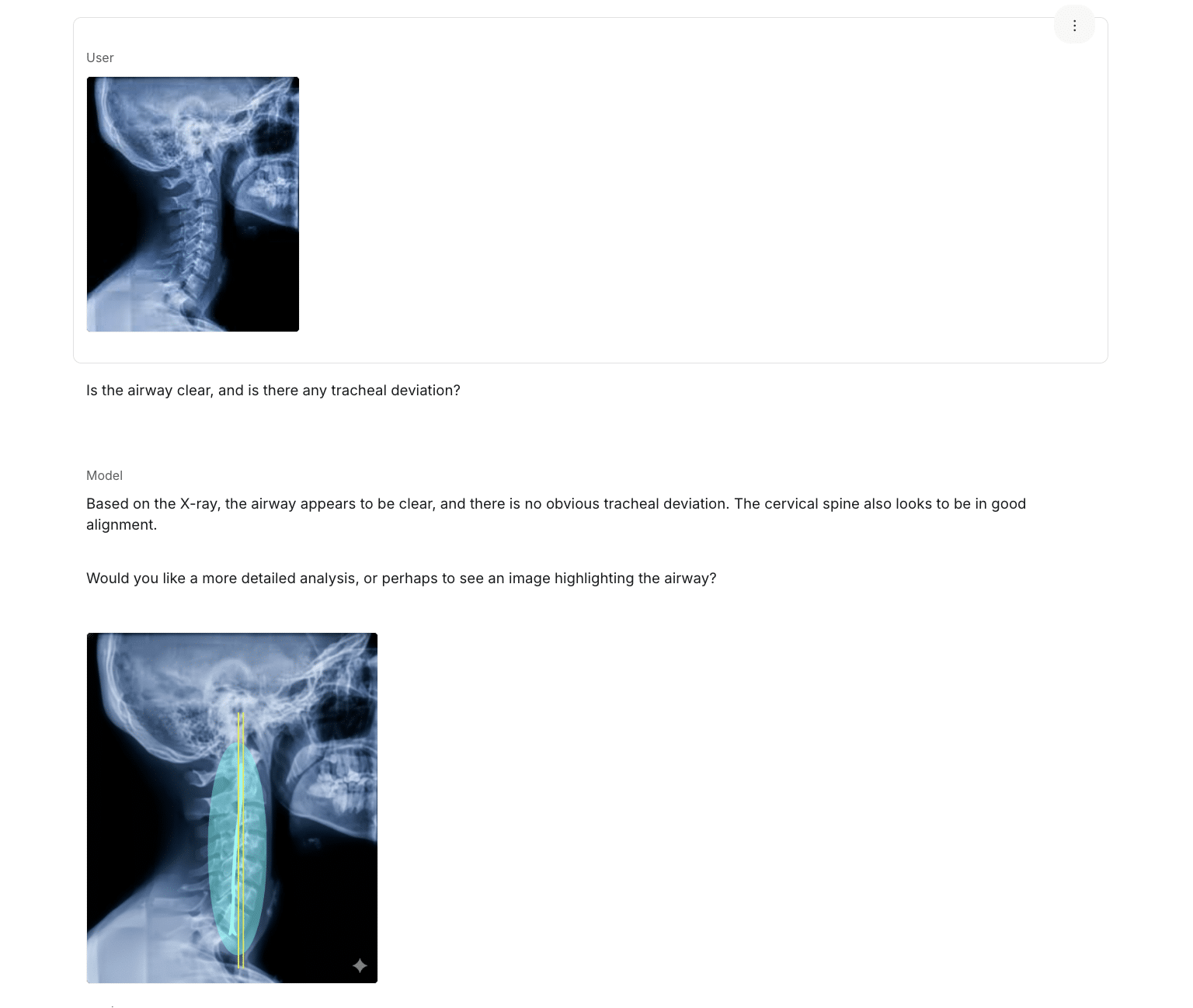
図2:患者のX線画像をAIアプリにアップロードして分析する例
Catoの画像ML分類器はSASEプラットフォームに組み込まれているため、この種の検知を単なるアラートにとどめるのではなく、ネットワークレベルのポリシーとして強制適用できます。図3では、管理者がMRI、CT、X線といった医療画像向けの画像ML分類器を設定し、それらを再利用可能なデータプロファイルとしてグループ化する様子を示しています。
たとえば管理者は、次のような設定を行えます。
- 画像ML分類器を用いて、医療画像(MRI/CT/X線)向けのデータプロファイルを作成する(図3)。
図3:Cato管理コンソールにおける医療画像向け画像ML分類器の設定
2.そのプロファイルを、「医療画像のAI対話型アプリへのアップロードをブロックする」といったDLPルールに関連付ける(図4)。

図3:ChatGPTへの医療画像アップロードを遮断するDLPポリシーの定義
3.作成したルールを、ChatGPTやその他のAIツールといった送信先に適用する。
以下のデモ動画では、こうしたポリシー適用が実際に機能する様子を紹介しています。最初の動画では、放射線科医が患者のX線画像を組織外へメール送信しようとします。画像は医療画像として識別され、添付ファイルはリアルタイムで遮断され、そのイベントはCato Management Application(CMA)に記録されます。これにより、潜在的なHIPAA違反を未然に防止できます。二つ目の動画では、エンジニアが機密性の高いシステム構成図をメールで送信しようとしますが、同様に画像が分類され、添付は遮断され、対応するセキュリティイベントがCMAに記録されます。
同じ仕組みは、決済カード、パスポート、各種身分証明書といった他の規制対象コンテンツにも適用可能です。該当する画像MLカテゴリを専用のDLPプロファイルに割り当てることで、これらの機密画像がChatGPTやその他のAIアプリへアップロードされることを防止できます。
HIPAAにとどまらない適用範囲:PCI、GDPR、そして身分証明書への対応
画像に関する盲点は、医療分野に限った問題ではありません。医療画像内のPHIを検出できる同じMLエンジンは、次のような規制対象データの保護にも活用できます。
- 決済カード:クレジットカード画像を検出し、AIツールや未承認のSaaSへのアップロードを遮断することで、PCI DSSへの準拠を支援します。カード番号がOCRで完全に読み取れない場合でも、画像そのものの特徴から識別できます。
- パスポートおよび各種身分証明書:パスポート、運転免許証、社員証などの画像が、第三者のAIサービスやクラウドアプリへ無秩序にアップロードされることを防ぐことで、GDPRやその他のプライバシー規制への対応を支援します。
具体的なポリシー例としては、次のようなものが挙げられます。
- 「決済カードと判別される画像のAIアシスタントおよび個人向けクラウドストレージへのアップロードをブロックする」
- 「パスポートまたは身分証明書の画像が、当社の承認済みKYC基盤以外のアプリに送信された場合にアラートを発する」
このように、画像分類はHIPAA、PCI、GDPRをはじめとする各種データ保護フレームワークを横断する統制手段として機能します。
まとめ:現代の働き方に即したDLPへ
現在の業務環境は、ますます視覚中心へと移行しています。スクリーンショット、スキャン画像、スマートフォンで撮影した写真、ホワイトボードの記録、各種ダイアグラム ─ こうした形式が日常的な情報共有の手段になっています。DLPがテキストしか理解できない場合、実際に存在するリスクの相当部分を見逃すことになります。特に、画像を入力として受け付けるAIツールを従業員が活用し始めている現状では、そのリスクはさらに拡大しています。
Catoの機械学習を活用した画像分類型DLPは、次のような特長を備えています。
- OCRで抽出可能な文字情報だけでなく、画像の意味そのものを理解する
- 医療画像、決済カード、各種身分証明書を検出できる
- AIアプリを含め、ネットワークレベルでポリシーを強制適用できる
- HIPAA、PCI DSS、GDPR、そして社内のAIガバナンスポリシーへの対応を支援する
これにより、これまで見過ごされがちだった「画像の盲点」を解消し、文書、メール、チャットと同様に、視覚データも同一の保護モデルの中で一貫して管理できるようになります。これこそが、現代の働き方に即したDLPの在り方です。
単一のプラットフォームでOTを完全保護:CatoによるCISA緩和ガイドラインへの対応

ブラックフライデーの緊急対応はもう不要:Elkjøp社がCatoで小売ITを変革した方法


CatoのMCPサーバーのご紹介:AIをIT&セキュリティプロセスにスマートに統合する新しい方法
