AIOps nella piattaforma Cato SASE: ricorso alla rete predittiva basata sull’IA per passare da un approccio IT reattivo a uno proattivo


- 1. Che cos'è AIOps?
- 2. Perché le operazioni IT hanno bisogno di AIOps: Le principali sfide che è in grado di risolvere
- 3. Ricerca AIOps: rilevamento e networking predittivo basato sull'IA nella piattaforma Cato SASE
- 4. AIOps e networking predittivo basato sull'intelligenza artificiale nella piattaforma Cato SASE Cloud
È un tranquillo lunedì mattina, finché John, responsabile IT, apre il suo portatile e nota 424 nuovi ticket di supporto. Gli utenti in ufficio segnalano problemi come “le app non si caricano” e “internet non funziona”. Dopo ore di indagini che si protraggono fino al giorno seguente, il team riconduce il problema a un router di filiale sovraccarico di query DNS errate provenienti da un dispositivo IoT malfunzionante. La CPU del router, al massimo delle sue capacità, ritarda la risoluzione DNS e interrompe la connettività per tutti gli utenti. Proprio mentre sono alle prese con questo problema, arrivano altri 45 ticket dal team vendite. I computer di questo reparto stanno subendo dei blocchi a causa di un’app beta installata dopo una raccomandazione CRM, che causa perdite di memoria e un alto utilizzo della CPU su tutti i dispositivi, richiedendo ancora più tempo per una diagnosi completa.
Questi esempi immaginari ma realistici mostrano come azioni quotidiane, benché non mosse da intenzioni malevole, possano causare gravi interruzioni. Con AIOps, i picchi di larghezza di banda avrebbero potuto attivare avvisi tempestivi e i problemi della CPU avrebbero potuto essere rapidamente attribuiti all’app o al dispositivo difettoso. Anziché intervenire sotto pressione, il team IT avrebbe potuto prevenire completamente l’impatto. Questa è la potenza di AIOps e della rete predittiva basata sull’IA: trasforma il caos in informazioni utili e permettere di prendere il controllo della situazione prima che i problemi si aggravino.
Che cos’è AIOps?
AIOps, o Intelligenza artificiale per le operazioni IT, ricorre all’apprendimento automatico, all’automazione e all’analisi dei dati per aiutare i team IT a monitorare e gestire le infrastrutture moderne in modo più efficace. Analizzando in tempo reale i segnali complessi del sistema, AIOps può rilevare schemi ricorrenti, prevedere problemi quali sovraccarichi della CPU, congestione della larghezza di banda, degrado delle prestazioni delle applicazioni e intraprendere azioni prima che gli utenti siano colpiti. Oltre al rilevamento precoce, AIOps aiuta anche a valutare la portata e il potenziale impatto dei problemi e a risalire alle loro cause profonde, nonché a identificare quali applicazioni o sistemi centrali sono interessati e a prevedere l’evolversi della situazione. Questo cambiamento consente ai team IT di passare dalla risoluzione reattiva alla prevenzione proattiva (e basata sui dati) dei problemi. Vari studi di settore e analisi di esperti suggeriscono che le soluzioni AIOps più efficaci possono rilevare e risolvere problemi operativi prima che vengano formalmente identificati dai team IT.
Perché le operazioni IT hanno bisogno di AIOps: Le principali sfide che è in grado di risolvere
- Gestisce la complessità: accorpa ambienti cloud, legacy e ibridi.
- Riduce il rumore: filtra gli avvisi e mette in evidenza ciò che è rilevante.
- Automatizza le attività di routine: rende obsoleto il lavoro manuale lento e soggetto a errori.
- Previene i problemi: rileva in anticipo picchi della CPU, rallentamenti delle app e sovraccarichi di banda.
- Accelera la risoluzione: combina la rapida individuazione delle anomalie con la previsione basata sulle tendenze e l’analisi delle cause profonde per ridurre il MTTR e affrontare i problemi prima che attecchiscano completamente.
- Garantisce la conformità: supporta NIS2, DORA, ISO 22301 e ITIL 4, identificando trend, come l’uso crescente di app non autorizzate, che potrebbero portare nel tempo a violazioni della conformità.
- Protegge gli SLA: prevede i rischi e aiuta i team a intervenire prima che le soglie vengano superate.
Ricerca AIOps: rilevamento e networking predittivo basato sull’IA nella piattaforma Cato SASE
Informazioni predittive basate sulla visibilità unificata nell’architettura di Cato
La nostra ricerca AIOps era profondamente radicata in un vantaggio infrastrutturale chiave: la visibilità completa. Attraverso la nostra architettura Cato SPACE (Single Pass Cloud Engine), manteniamo un contesto unificato su tutti i dispositivi e i flussi di rete all’interno della piattaforma Cato SASE. Questa visione coesa ci consente di monitorare continuamente e su larga scala l’uso della CPU, il carico di memoria, il consumo di larghezza di banda, il comportamento a livello di applicazione e altro ancora.
Questo ricco set di dati alimenta il nostro lavoro continuo nell’individuazione delle anomalie e nell’analisi predittiva. Identificando trend insoliti nell’uso delle risorse, come aumenti improvvisi o prolungati della CPU o della larghezza di banda, abbiamo la possibilità di prevedere potenziali problemi prima che si trasformino in vere e proprie interruzioni. I nostri modelli non si concentrano solo sui valori grezzi, ma sul modo in cui l’uso futuro possa superare le soglie di criticità, permettendo così di intervenire anzitempo.
Ad esempio, nel grafico sottostante (Figura 1), illustriamo come il networking predittivo basato sull’IA rilevi che l’uso della CPU previsto su un sistema monitorato dovrebbe superare una soglia predefinita del 90% entro due giorni. Questa previsione non si basa solo sui dati osservati, ma è anche contestualizzata rispetto ai limiti che contano sotto il profilo operativo. Ciò fa sì che l’allerta sia esplicita e attuabile.
Un picco previsto nell’utilizzo della CPU mostra valori stimati che superano una soglia predefinita (linea rossa tratteggiata). La linea blu rappresenta l’uso orario grezzo della CPU, mentre la linea verde definisce questi dati per evidenziare i trend sottostanti. Unitamente alla modellazione predittiva (linea viola), questo approccio rende possibile la ricezione di avvisi tempestivi e contestualizzati che contribuiscono a prevenire la riduzione delle prestazioni.
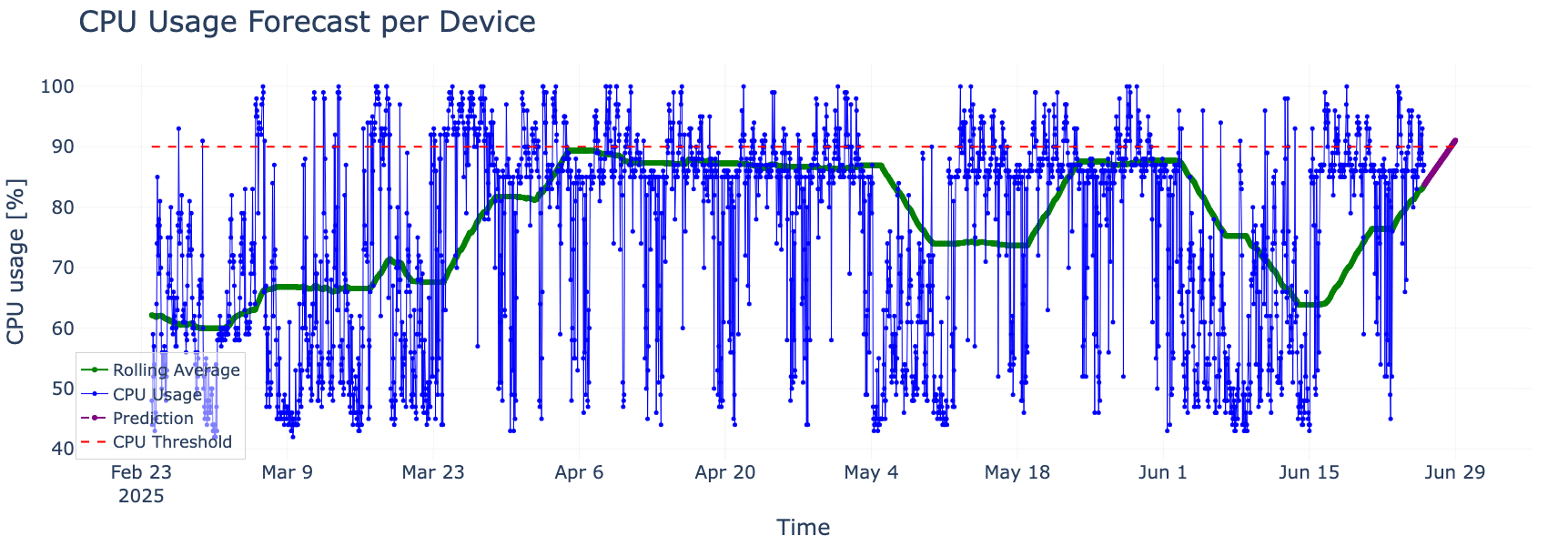
Figura 1. Previsione dell’uso della CPU per dispositivo
Correlazione del traffico delle applicazioni con il carico della CPU lato dispositivo
Nell’analisi delle cause profonde, durante l’analisi di un dispositivo specifico, esploriamo la relazione tra il traffico delle applicazioni e le prestazioni del sistema. Esaminando le correlazioni tra il throughput a monte e a valle e l’uso della CPU, scopriamo preziose intuizioni su quali applicazioni potrebbero contribuire maggiormente al carico delle risorse. Sono svariati i fattori operativi che possono influenzare questa relazione.
Sul lato a valle, alcuni tipi di traffico possono generare un alto utilizzo della CPU sul dispositivo. Esempi includono lo streaming video ad alta risoluzione, dashboard in tempo reale e traffico cloud crittografato che richiede un’ispezione locale. Download di file di grandi dimensioni, aggiornamenti software e streaming di asset attivano anche un’intensa elaborazione post-download come decrittazione, scansione o rendering. Queste attività trasformano il consumo passivo di dati in un carico di lavoro significativo a livello di dispositivo.
Sul lato a monte, il traffico outbound sostenuto, come il caricamento di log nei sistemi di monitoraggio, i flussi di videoconferenza, la sincronizzazione dei file con l’archiviazione cloud o le trasmissioni di dati dei sensori IoT possono pesare e non poco sulla CPU. Questi flussi spesso comportano crittografia, applicazione di policy, gestione delle sessioni e ispezione approfondita, ovvero attività che consumano risorse di elaborazione.
Come mostrato nella Figura 2, questo tipo di analisi di correlazione aiuta a orientare l’indagine sulle cause profonde e la pianificazione della capacità senza la necessità di intervenire manualmente. Una matrice di correlazione rivela una forte relazione statistica (superiore a 0,7 su una scala da -1 (correlazione lineare negativa perfetta) a 1 (correlazione lineare positiva perfetta) tra il throughput dei dati di un’applicazione e il carico della CPU del sistema, suggerendo che l’app potrebbe aumentare l’uso delle risorse.

Figure 2. Correlazione tra rete e CPU
A volte, il tempismo racconta l’intera storia. La Figura 3 ci permette di comprendere che quando l’attività di upload di un’applicazione cliente diminuisce, la stessa sorte tocca all’utilizzo della CPU. Anche se i dati della CPU possono risultare distorti a causa di molti processi eseguiti simultaneamente, emergono trend decisamente evidenti. Queste osservazioni ci aiutano a individuare quali app condizionano maggiormente le prestazioni.
Un calo visibile sia nel traffico upstream che nell’utilizzo della CPU nel medesimo intervallo di tempo evidenzia l’influenza dell’applicazione sul carico del sistema, offrendo indizi essenziali per l’ottimizzazione.
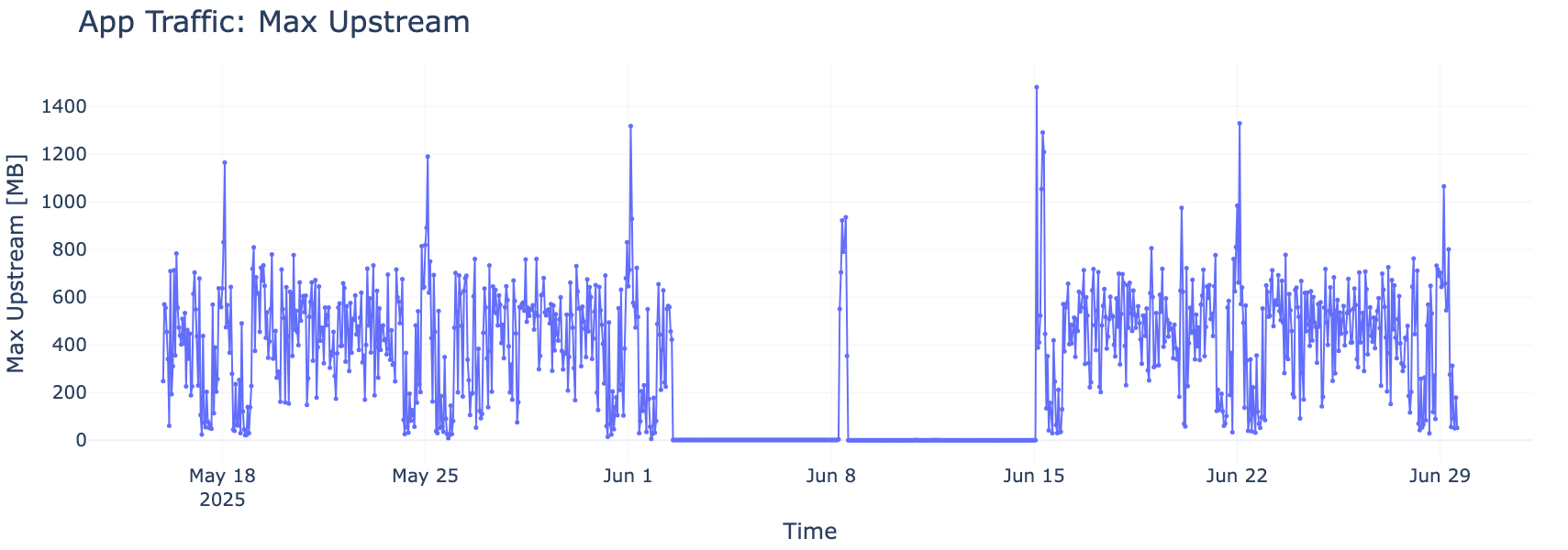
Figura 3. Attività dell’applicazione e carico della CPU (megabyte)
Oltre al traffico: identificazione di altri fattori di carico della CPU
In aggiunta alla direzione del traffico, esistono ulteriori fattori che contribuiscono al carico della CPU. I picchi nel numero di host connessi o flussi contestuali, come avviene ad esempio durante gli accessi o gli aggiornamenti software di massa, possono sovraccaricare i motori di tracciamento delle sessioni e di applicazione delle regole. Anche le applicazioni ad alto volume o ad alta intensità di calcolo, come la scansione di malware o i trasferimenti di file di grandi dimensioni, consumano una notevole porzione di potenza di elaborazione. In alcuni casi, le nuove versioni di software possono portare a regressioni delle prestazioni o a registrazioni eccessive. Inoltre, modifiche alla configurazione come l’abilitazione dell’ispezione approfondita dei pacchetti, policy di zero trust o funzionalità di prevenzione delle intrusioni aumentano le richieste di elaborazione per pacchetto.
Modellazione predittiva della larghezza di banda per una gestione proattiva delle risorse
La nostra ricerca non si ferma alla CPU: l’uso della larghezza di banda rappresenta un’altra area cruciale in cui le informazioni predittive sono vitali. Nella Figura 4, esaminiamo come i modelli giornalieri di larghezza di banda possano aiutare a prevedere potenziali violazioni della soglia di capacità. Combinando i trend di utilizzo osservati con i modelli di previsione, possiamo emettere avvisi anticipati per prevenire sorprese in termini di costi o interruzioni del servizio prima che si verifichino.
Un modello di rete basato sull’intelligenza artificiale predittiva identifica una violazione imminente della capacità in base alle tendenze di utilizzo nei giorni feriali. L’individuazione tempestiva dà ai team IT il tempo per adattare le policy o l’utilizzo prima che vengano raggiunte soglie critiche.

Figura 4. Previsione delle violazioni della soglia di larghezza di banda
AIOps e networking predittivo basato sull’intelligenza artificiale nella piattaforma Cato SASE Cloud
Le informazioni che otteniamo grazie alla nostra ricerca continua su AIOps migliorano il monitoraggio in tempo reale, il rilevamento delle anomalie e l’allerta proattiva della piattaforma Cato SASE Cloud. Integrando funzionalità predittive nella nostra piattaforma, offriamo ai team IT e di sicurezza la possibilità di rilevare e risolvere problemi come la saturazione della CPU o l’esaurimento della larghezza di banda prima che interrompano l’attività. Se da un lato AIOps eccelle nell’individuazione di anomalie e nella previsione dei trend, dall’altro l’analisi delle cause profonde svolge un ruolo complementare, poiché contribuisce a identificare la vera fonte di un problema.
In sintesi, tutto ciò consente ai team di concentrarsi su ciò che conta di più: gestire l’attività aziendale con sicurezza ed efficienza.
26 acronimi e abbreviazioni di CyberSecurity che dovresti conoscere



Ricerca sulle minacce Cato CTRL™: Il generatore di Immagini di ChatGPT di OpenAI permette la creazione di passaporti falsi





