Cato SASE Platform におけるAIOps:予測型AIネットワーキングによる、事後対応からプロアクティブなIT運用への転換


その月曜の朝は、静かに始まりました。IT部門責任者のジョンがノートPCを開くと、424件もの新しいサポートチケットが表示されていました。オフィス全体から「アプリが開かない」「インターネットが使えない」といった問い合わせが一斉に寄せられていたのです。調査は数時間に及び、翌日まで持ち越されました。最終的にチームが突き止めた原因は、ある拠点のルーターでした。正常に動作していないIoTデバイスが不正なDNSクエリを大量に送信し、ルーターに過剰な負荷をかけていたのです。CPU使用率は限界に達し、DNSの名前解決が遅延。その影響で、拠点全体の通信が不安定になっていました。この問題をようやく解消した直後、今度は営業チームから45件の新たなチケットが届きます。CRMのレコメンドをきっかけにインストールされたベータ版アプリが原因で、PCがフリーズしていたのです。このアプリはメモリリークと高いCPU使用率を引き起こし、複数の端末に影響を及ぼしていました。原因の特定から完全な復旧までには、さらに多くの時間を要しました。
これらは架空のエピソードではありますが、現実でも十分に起こり得る状況です。悪意のない日常的な行動であっても、結果として大きな障害につながることがあります。もしAIOpsが導入されていれば、帯域の急激な増加は早期にアラートとして検知され、CPUの異常も問題のあるアプリやデバイスに即座に紐づけられていたはずです。プレッシャーの中で後追いの対応に追われるのではなく、影響が出る前に未然に防ぐことができたでしょう。それこそが、AIOpsと予測型AIネットワーキングがもたらす価値です。混乱を「気づき」へと変え、問題が深刻化する前にコントロールする力をITチームにもたらすのです。
AIOpsとは?
AIOps(Artificial Intelligence for IT Operations)とは、機械学習、自動化、データ分析を活用し、ITチームが現代の複雑なITインフラをより的確かつ効率的に監視・運用できるようにする取り組みです。AIOpsは、システムから発せられる多種多様で複雑なシグナルをリアルタイムに分析し、CPUの過負荷、帯域の輻輳、アプリケーション性能の劣化といった兆候を早期に捉え、ユーザーへの影響が顕在化する前に対処することを可能にします。AIOpsの価値は、単なる早期検知にとどまりません。発生しつつある問題の影響範囲や深刻度を評価し、原因を遡って特定することができます。どのシステムや重要なアプリケーションが影響を受けているのかを明確にし、状況が今後どのように展開していくのかを予測することも可能です。こうしたアプローチにより、ITチームは障害が発生してから対応する「事後対応型のトラブルシューティング」から、問題を未然に防ぐ「プロアクティブな予防型運用」、さらにはデータに基づいた意思決定へと移行できます。業界調査や専門家の分析によれば、ITチームが問題を正式に把握する前の段階で、最も効果的なAIOpsソリューションは、運用上の課題を検知し、解決に導くことができるとされています。
IT運用になぜAIOpsが必要なのか:解決する主な課題
- 複雑性の管理:クラウド、レガシー、ハイブリッドといった異なる環境を横断的に統合し、分断された運用を一元化します。
- ノイズの削減:大量のアラートを取捨選択し、本当に対応が必要な事象を浮き彫りにします。
- 定型作業の自動化:時間がかかり、ミスが発生しやすい手作業を自動化し、運用負荷を軽減します。
- 問題の未然防止:CPUスパイク、アプリケーションの遅延、帯域の逼迫といった兆候を早期に検知します。
- 復旧の迅速化:高速な異常検知に加え、トレンドに基づく予測や根本原因分析を組み合わせることで、MTTR(平均復旧時間)を短縮し、問題が深刻化する前に対処します。
- コンプライアンスの確保:NIS2、DORA、ISO 22301、ITIL 4といった要件への対応を支援するとともに、未承認アプリの利用増加など、将来的にコンプライアンス違反につながりかねない傾向も把握できます。
- SLAの保護:リスクを事前に予測し、しきい値を超える前に対応することで、SLAの維持を支援します。
Cato SASE Platform におけるAIOpsリサーチ:検知と予測型AIネットワーキング
Catoアーキテクチャが実現する、統合可視性に基づく予測インサイト
私たちのAIOpsリサーチは、アーキテクチャ上の明確な強みに支えられています。それが「全体を見渡す可視性」です。Cato SPACE(Single Pass Cloud Engine)アーキテクチャにより、Cato SASE Platform内のすべてのデバイスおよびネットワークフローを横断して、統一されたコンテキストを維持しています。この一貫した視点によって、CPU使用率、メモリ負荷、帯域消費、アプリケーションレベルの挙動などを、大規模かつ継続的に把握することが可能になります
こうして得られる豊富なデータセットは、異常検知や予測分析に関する継続的な取り組みを支える基盤となっています。CPUや帯域使用率が急激に、あるいは継続的に増加するといったリソース利用の異常な兆候を捉えることで、実際の障害へと発展する前に潜在的な問題を予測できます。また、私たちのモデルは単純な現在値の変動を見るのではなく、将来的な利用状況が重要なしきい値を超える可能性に着目しています。これにより、影響が顕在化する前の段階で、先回りした対処を可能にしています。
例えば、以下のグラフ(図1)は、予測型AIネットワーキングが、監視対象システムのCPU使用率が2日以内に、あらかじめ設定された90%のしきい値を超えると見込まれる状況を、どのように捉えるかを示しています。この予測は、単に過去や現在の観測データだけに基づくものではありません。運用上の観点から重要となる制限値を踏まえたコンテキストの中で行われており、その結果、アラートは意味があり、かつ実際の対応につながるものとなります。
CPU使用率の上昇が予測される場合、その推移は、将来的な値が事前に定義されたしきい値(赤の破線)を超えていく形で表されます。青い線は1時間ごとのCPU使用率の生データを示し、緑の線はそれを平滑化することで、背後にある傾向を浮かび上がらせています。さらに、予測モデルによる推定値(紫の線)を重ね合わせることで、文脈を踏まえた早期アラートが可能となり、パフォーマンス低下を未然に防ぐことができます。
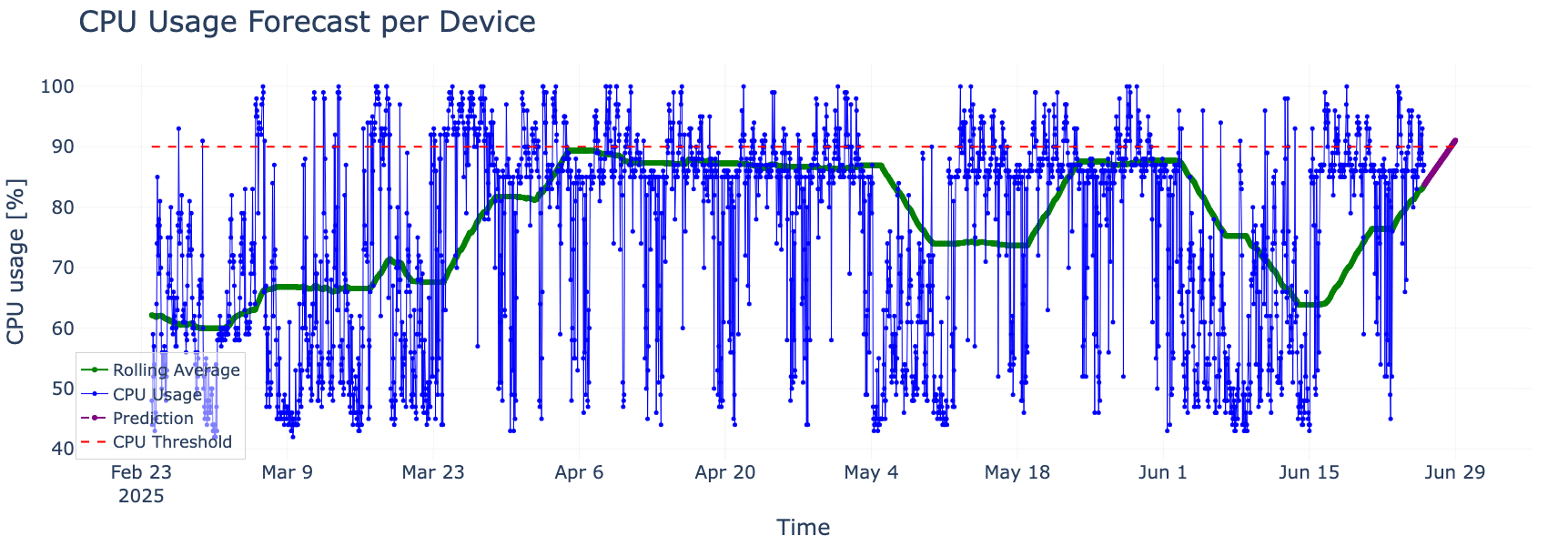
図1:デバイス別CPU使用率の予測
アプリケーショントラフィックとデバイスレベルのCPU負荷の相関
根本原因分析で特定のデバイスを詳しく確認する際には、アプリケーショントラフィックとシステム性能との関係性を丁寧に見ていきます。上り・下りそれぞれのスループットとCPU使用率の相関を分析することで、どのアプリケーションがリソース負荷に最も大きく影響しているのかを把握するための重要な手がかりが得られます。この相関関係には、複数の運用上の要因が関与しています。
下りトラフィックの観点では、特定の通信タイプがデバイス上で高いCPU使用率を引き起こすことがあります。たとえば、高解像度の動画ストリーミング、リアルタイムダッシュボード、ローカルでの検査が必要となる暗号化クラウドトラフィックなどがその代表例です。さらに、大容量ファイルのダウンロード、ソフトウェアアップデート、各種アセットのストリーミングでは、ダウンロード後に復号、スキャン、レンダリングといった処理が発生し、CPUに大きな負荷がかかります。こうした処理によって、本来は受動的なデータ消費である通信が、デバイスレベルでは無視できない処理負荷へと変わっていきます。
上りトラフィックの側面では、監視システムへのログ送信、ビデオ会議のストリーミング、クラウドストレージとのファイル同期、あるいはIoTセンサーからのデータ送信といった、継続的なアウトバウンド通信がCPUに大きな負荷をかけることがあります。これらの通信フローでは、暗号化処理、ポリシー適用、セッション管理、ディープインスペクションなどが伴うケースが多く、いずれも処理リソースを消費します。
図2に示すように、こうした相関分析を行うことで、手作業による当て推量に頼ることなく、根本原因の特定やキャパシティプランニングを的確に進めることができます。相関行列において、アプリケーションのデータスループットとシステムのCPU負荷との間に、−1(完全な負の線形相関)から1(完全な正の線形相関)のスケールで0.7を超える強い統計的相関が確認された場合、そのアプリケーションがリソース使用量の増加を主に引き起こしている可能性が高いことを示しています。

図2:ネットワークトラフィックとCPU使用率の相関
ときには、「時間の流れ」そのものが重要な手がかりになります。図3では、ある顧客アプリケーションのアップロード通信量が低下すると、それに連動する形でCPU使用率も下がっている様子が確認できます。CPUの利用状況は、同時に多数のプロセスが動作しているためノイズが多くなりがちですが、それでもはっきりとした傾向が見て取れます。このような時系列での観察は、どのアプリケーションがシステムパフォーマンスに最も大きな影響を及ぼしているのかを見極めるうえで有効です。
同一の時間帯に、上りトラフィックとCPU使用率の双方が明確に低下していることは、そのアプリケーションがシステム負荷に与える影響の大きさを示しており、最適化に向けた重要な手がかりとなります。
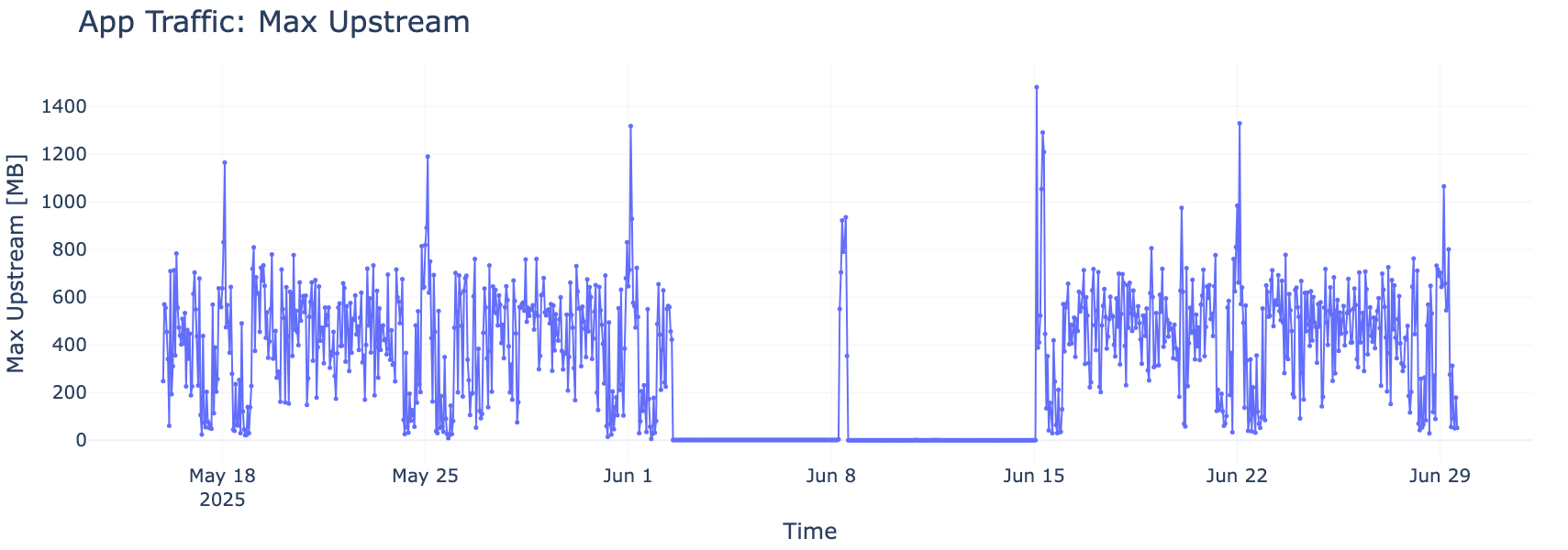
図3:アプリケーションのアクティビティとCPU負荷(メガバイト)
トラフィック以外にCPU負荷を左右する要因
CPU負荷の増大は、トラフィックの送受信方向だけで説明できるものではありません。たとえば、ログインが集中するタイミングや大規模なソフトウェアアップデートの実施時には、接続ホスト数や同時フロー数が急増し、セッション管理やポリシー適用エンジンが処理しきれなくなることがあります。また、マルウェアスキャンや大容量ファイル転送のように、処理量や計算負荷の高いアプリケーションは、それ自体がCPUリソースを大きく消費します。場合によっては、新たに展開されたソフトウェアバージョンがパフォーマンスの劣化を招いたり、過剰なログ出力によって想定以上の負荷を発生させたりすることもあります。さらに、ディープパケットインスペクション、ゼロトラストポリシー、侵入防止機能といった設定を有効化することで、パケット単位での処理が増加し、その結果としてCPU負荷が高まるケースも少なくありません。
プロアクティブなリソース管理に向けた、帯域使用量の予測モデリング
私たちのリサーチは、CPUに限ったものではありません。帯域使用量もまた、予測に基づくインサイトが特に重要となる領域です。図4では、日々の帯域利用パターンを分析することで、将来的にキャパシティのしきい値を超える可能性をどのように予測できるかを示しています。実際の利用トレンドと予測モデルを組み合わせることで、想定外のコスト増加やサービスの中断といった事態が発生する前に、早期に警告を発することが可能になります。
予測型AIネットワーキングのモデルは、平日における利用傾向をもとに、近い将来に発生し得るキャパシティ超過を捉えます。こうした兆候を早期に検知することで、ITチームは、重要なしきい値に到達する前の段階で、ポリシーや利用状況を見直すための十分な時間を確保できます。

図4:帯域使用量のしきい値超過の予測
Cato SASE PlatformにおけるAIOpsと予測型AIネットワーキング
私たちが継続的に進めているAIOpsリサーチから得られる知見は、Cato SASE Platformのリアルタイム監視、異常検知、そしてプロアクティブなアラート機能の強化に直接反映されています。予測機能をプラットフォームに組み込むことで、CPUの飽和や帯域の枯渇といった課題を、ビジネスに影響が及ぶ前の段階で検知し、ITチームやセキュリティチームが速やかに対処できるようになります。AIOpsは、異常の検知やトレンドの予測において高い効果を発揮しますが、根本原因分析はそれを補完する重要な要素です。問題の表層ではなく、その背後にある真の原因を明らかにすることで、より的確で持続的な解決につなげることができます。
その結果、チームは運用上の細かなトラブル対応に追われることなく、本来注力すべきこと―ビジネスを安心して、かつ効率的に運営すること―に集中できるようになるのです。






