
Savanti:エージェント型AIがCatoの研究開発効率をどう高めたか


TL;DR:
Savanti は、Slack、Confluence、Git、Jira に蓄積された情報を横断的に統合し、文脈を踏まえた回答を即座に提示する、Cato Networks の社内向けエージェント型AIアシスタントです。問い合わせの内容に応じて、単純な応答、より深い考察、あるいは複数ステップにわたる推論を使い分ける柔軟な思考プロセスにより、各クエリを処理します。すべての回答は、実際の社内情報に基づいて生成され、出典とともに提示されると同時に、信頼度の評価を経て提供されます。これは単なる RAG ではなく、Agentic RAGと呼ぶべきものです。すなわち、環境の中で思考し、計画し、実行するAIです。本稿では、この仕組みをどのように構築したのか、なぜ有効に機能しているのか、そして実際にエンジニアの生産性向上につながるAIを導入した経験から得られた知見が、エージェント型AIのコミュニティに何を示唆するのかを紹介します。
なぜこれを構築したのか
質問が生まれる場所に、答えもあるべき
エンジニアは、日々のやり取りの中で Slack 上で質問を投げかけます。Savanti はその流れに直接組み込まれ、Slack のスレッド内で回答を提示することで、ツール間の行き来をなくし、知識をその場で可視化・共有できる状態を実現しました。こうして蓄積される一つひとつの回答は、そのまま チームの共有ドキュメントの一部として機能します。
企業における「知識の現実」
実際の企業環境では、ドキュメントは一箇所にまとまっているわけではありません。設計書、チケット、プルリクエスト、さらには Slack 上でのやり取りといった形で、複数の場所に分散して存在しています。Savanti は、こうした分断された情報を横断的に結びつけます。たとえば「なぜ pgvector を採用したのか?」という問いに対しては、Confluence の設計書、Git のプルリクエスト、意思決定の背景が議論された Slack のスレッドまで含めて、判断に至るまでの文脈全体を引き出しますこれこそが、本来あるべき「文脈を伴った情報の取得」です。
なぜ単なる検索ではなく、エージェント型AIなのか
Savanti は、単に情報を検索して提示するだけではありません。問いの内容に応じて、適切に考えます。すべての質問に同じ処理を行うのではなく、内容に応じて 最小限かつ最適な思考プロセスを選択し、十分な根拠と信頼性を備えた回答を導き出します。さらに、状況に応じて • その場で回答すべきか • 複数の情報源を組み合わせるべきか • 人に判断を委ねるべきか を、計画と検証のプロセスを通じて判断します。その結果、Savanti は単なる検索ツールにとどまらず、自律的に考え、判断し、行動する「チームの一員」として機能する存在となっています。
エージェント層:従来のRAGを超えて
一般的なRAGの仕組みは、「情報を取得して回答する」という段階で完結します。Savanti はそこに、エージェントとしての思考ループを加えています。
- 計画:問いの意図を読み取り、検索・統合・人への引き継ぎのいずれが適切かを判断する
- 取得:Slack、Confluence、Git、Jira など複数のシステムを横断し、意味ベースで情報を検索する
- 推論:得られた情報を突き合わせ、内容を統合しながら整合性を確認する
- 実行:出典を明示して回答する、または信頼度が低い場合は適切な担当者を案内する
従来の直線的なRAGとは異なり、Savanti は、信頼度が不十分な場合や情報に食い違いがある場合に、再検索や推論方法の切り替え、さらにはより深い分析へと処理を進めることができます。この評価のループこそが、「それなりに良い回答」を「安心して使える回答」へと引き上げる鍵となっています。
この思考の循環によって、アシスタントは単なるQ&Aツールにとどまらず、主体的に動く共同作業者のような存在として機能します。図1では、Savanti の全体構成を簡略化して示しています。
アーキテクチャ
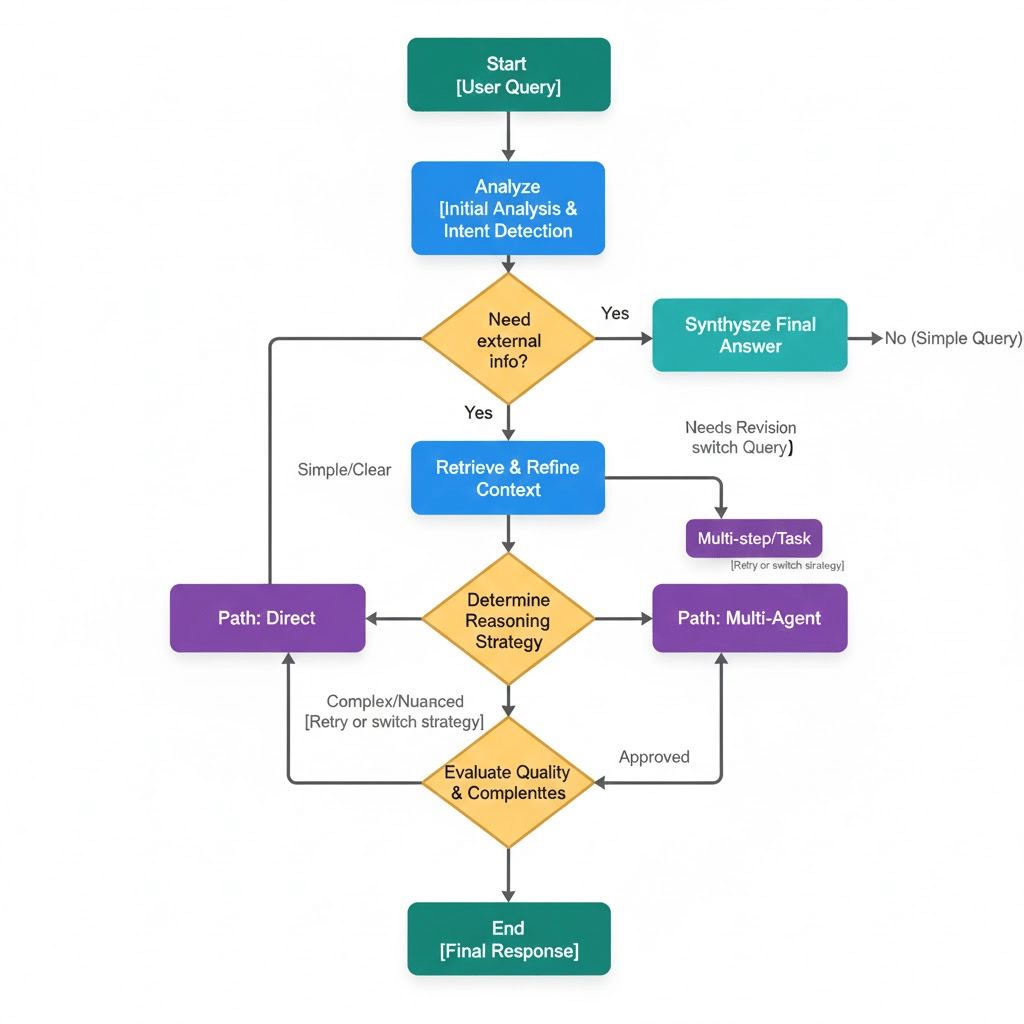
図1: Savanti のアーキテクチャ
設計において重視したポイント
- 文脈を踏まえた入出力(Context-in / Context-out):Slack のスレッドに流れる文脈をそのまま取り込み、会話の流れに自然に寄り添う形で回答できるようにしています。
- 統合された知識基盤:Slack、ドキュメント、コード、チケットなど、構造化・非構造化の情報を横断的に扱うため、複数のベクトル検索とRRFを組み合わせた統合インデックスを構築しています。
- 過度な複雑さを排した永続化:Postgres と pgvector を用いることで、信頼性の高い更新処理と、大量データの効率的な検索を、無理のない構成で実現しています。
- 出典を前提とした設計:すべての回答に情報源を明示し、信頼性の担保と知識の追跡可能性を確保しています。
- 状況に応じた処理の振り分け:クエリの内容に応じて分類を行い、単純な処理・深い検討・複数ステップの処理のいずれが適切かを判断し、最適な経路に振り分けます。
- 更新を踏まえた推論:情報に食い違いがある場合や内容の更新が示唆される場合には、根拠を突き合わせて整理し、現時点で最も妥当な結論を導き出します。
開発者の生産性への実際の効果
わずかな文脈の欠落であっても、作業効率には確実に影響します。Savanti は、その隙間を即座に補います。
- 新しく加わったメンバーも、いわゆる暗黙知を探し回ることなく、スムーズに立ち上がることができます。
- エンジニアは、これまで数時間かかっていた問題の解決を、数分で終えられるようになります。
- チーム横断の障害対応もより円滑になります。当番対応の場面では、必要な文脈をすばやくスレッドに提示し、やり取りの手戻りを減らしながら原因特定を加速します。
こうした効果は、現場の実感としても表れています。不要な呼びかけが減り、解決までの時間が短縮されるだけでなく、人が見落としていた情報同士を結びつけることで、新たな気づきが生まれる場面も増えています。さらに、こうした定性的な手応えに加え、導入状況や出典の質、クエリごとの時間削減効果を把握するための社内モニタリングも整備し、効果の可視化を進めています。
Savanti 活用の具体例
設定内容の把握
まず、設定に関する問い合わせに対する活用例です。Savanti は、関連するドキュメントや過去のやり取り、設定ガイドラインを横断的に結びつけ、必要な情報を一つの文脈として整理して提示します。(図2)

図2: 関連ドキュメントとチーム内の議論を結びつけ、設定情報を提示する Savanti
担当者の特定
Savanti は、名前が明示されていない場合でも、Confluence のメタデータや Slack 上の文脈を手がかりに、適切な担当者を導き出します。(図3)
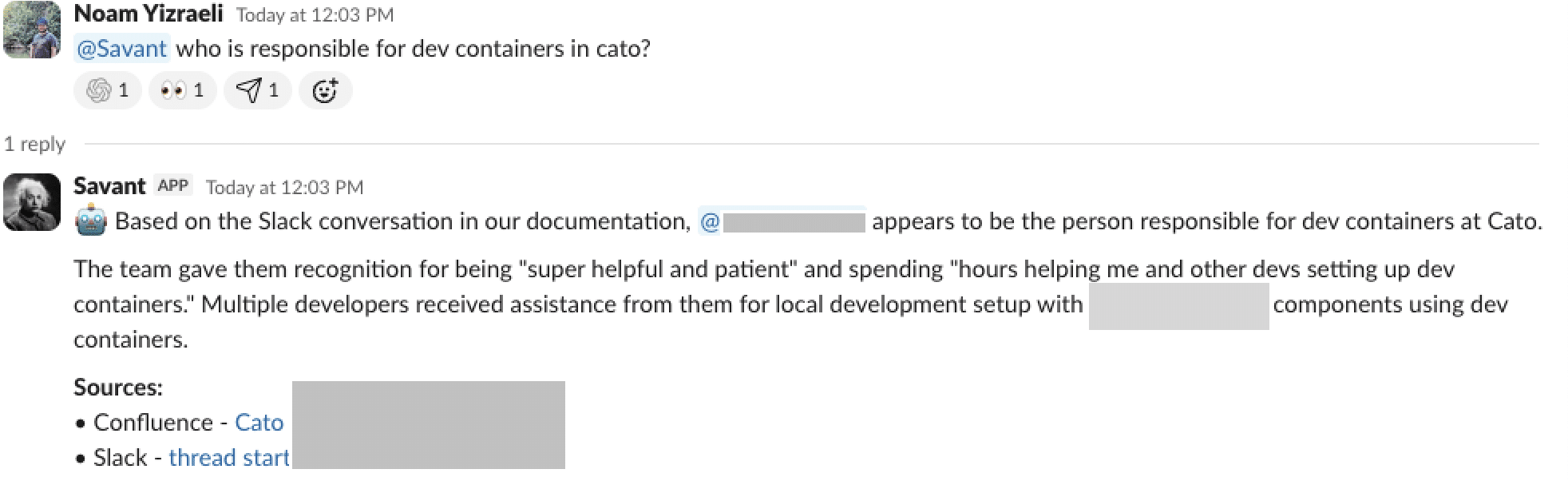
図3: Confluence のメタデータと Slack の会話をもとに、担当者を特定する Savanti
技術判断の再構成
過去の技術的な意思決定についての問いや、類似ケースに対する判断を求められた場合、Savanti は当時の検討プロセス全体を再構成します。設計書、Slack 上の議論、プルリクエスト、関連プロジェクトの履歴を横断的に参照しながら文脈を整理し、必要に応じて追加の問いを投げかけることで(図4)、より精度の高い示唆へと導きます(図5)。
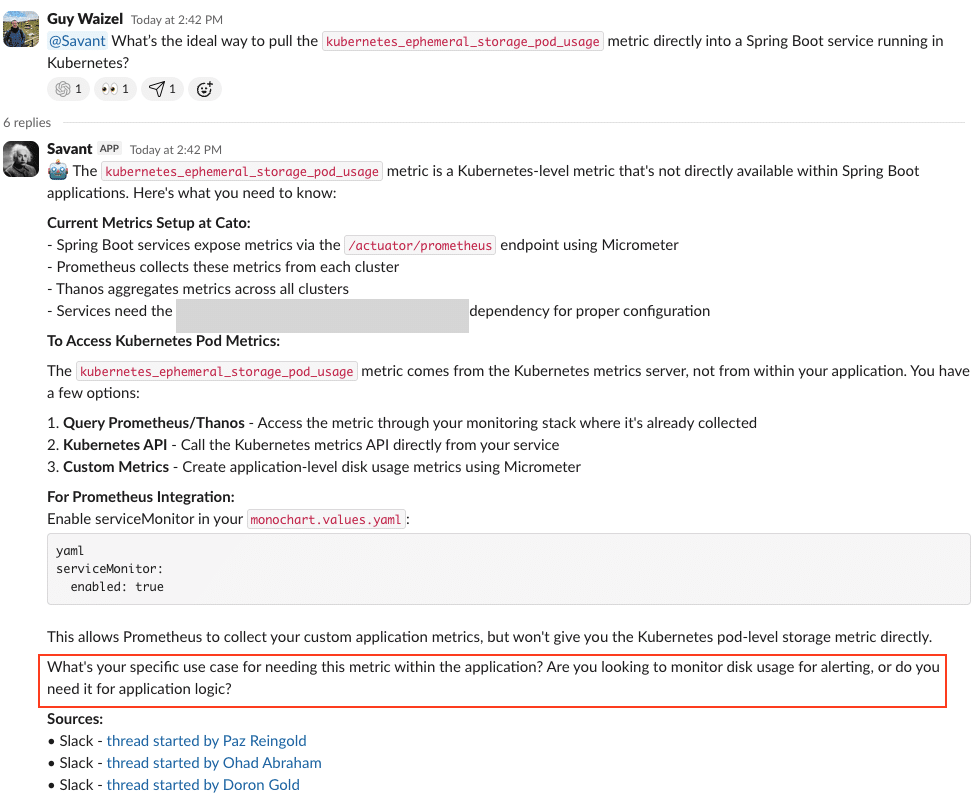
図4: 過去の意思決定を再構成し、新たな技術判断を支援する Savanti

図5: 問いを深めながら、構造的な推論によって回答を磨き上げる Savanti
これらの事例が示しているのは、単なる検索時間の短縮にとどまりません。それ以上に、組織の知識が継続的に蓄積され、活用されていく「生きた知識基盤」へと変わることに価値があります。
モニタリングと指標:Savanti の効果をどう測るか
Savanti の価値は、単なる実感にとどまりません。定量的にも裏付けられています。私たちは、利用状況や効率、知識活用への影響を継続的に可視化するため、社内に専用のダッシュボードを構築しています。
何を測っているのか
- 利用状況:Savanti を日常的に活用しているエンジニア、研究者、プロダクト担当者の数を把握しています。
- 時間削減効果:1つの問い合わせごとに、検索や資料確認、関係者との調整にかかる手間を、平均で約15分削減できていると見積もっています。
- 出典提示率:回答のうち、Slack、Confluence、Git、Jira などの情報源に基づいた裏付けが明示されている割合を追跡しています。
- 知識の波及効果:従来であれば誰かに確認していた内容を自己解決できるようになることで、他のメンバーの作業を中断させない効果が生まれます。この間接的な価値は、5倍から10倍規模に広がる可能性があると考えています。
どのように可視化しているか
ダッシュボードでは、直近24時間のアクティブユーザー数、回答ごとの出典提示数、累計の工数削減時間などを一目で把握できます。各バーは、Savanti による自動応答と出典付き回答によって、Cato の研究開発チーム全体でどれだけの時間が生み出されたかを示しています。
これらのデータは、現場での手応えとも一致しています。Savanti は単に1件ごとの対応時間を短縮するだけでなく、専門人材を割り込み対応から解放し、組織全体で知識を活用できる状態をつくることで、効率を連鎖的に高めているのです。(図6)
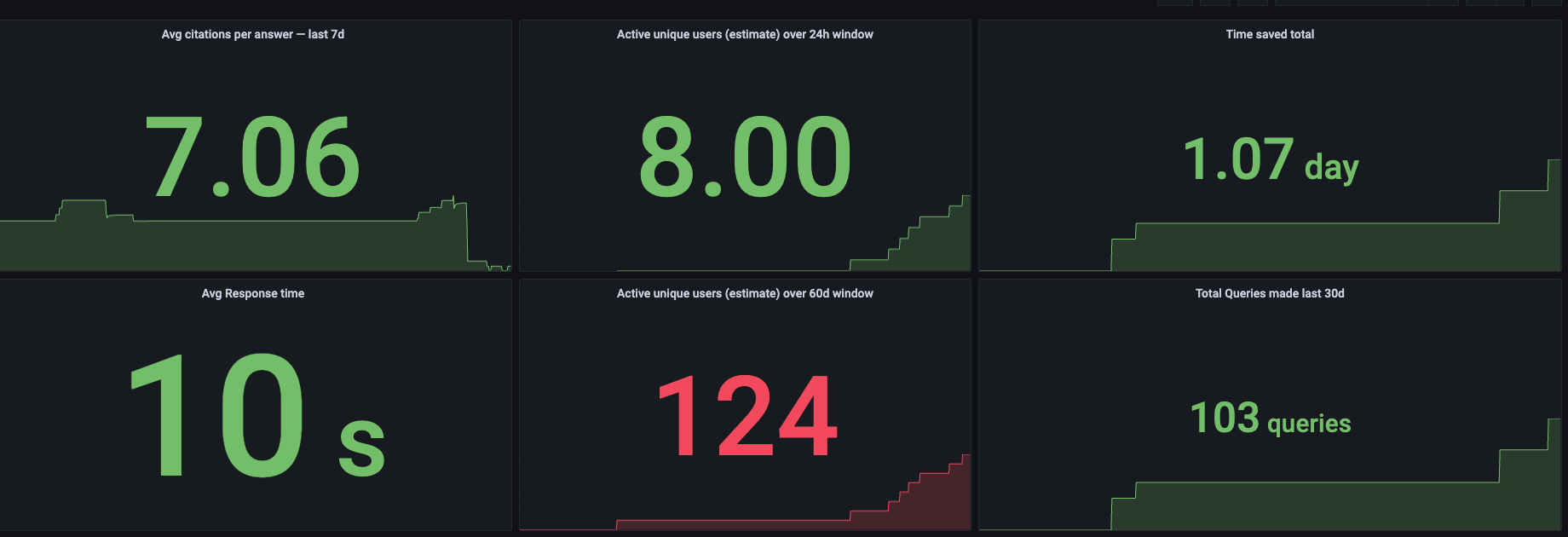
図6: Savanti の効果を可視化したダッシュボード
エージェント型AIコミュニティへの示唆
- エージェント型RAGは確かに機能する:検索と推論を組み合わせることで、成果は明確に向上します。これは単に検索を高度化したものではなく、業務の流れの中で思考し続ける存在です。
- 文脈の中に置いてこそ価値が生まれる:人がやり取りしている場にAIを組み込むことで、その効果は大きく引き出されます。別の入り口を用意するのではなく、日常の流れの中に自然に組み込むことが重要です。
- まずシンプルに、そこから広げる:私たちの初期版は、単一の Postgres と最小限の実装で構築しました。まずは安定して動くことを優先し、その上で段階的に発展させていくことが重要です。
- 見るべきは見栄えの数字ではなく、実際の価値:追っているのは、応答の速さや有用性、信頼度といった指標です。トークン数や理論上のコストではなく、実際に役立っているかどうかに焦点を当てるべきです。
- 振り分けそのものが体験を左右する:すべてを重く処理するのではなく、必要なときにだけ深く考える。このバランスが体験の質を大きく左右します。どう振り分けるか自体が、プロダクトの重要な設計要素になります。
今後の展開
Savanti は、今後さらに機能の拡張を進めていきます。
- Model Control Plane(MCP)を介した IDE や CLI との連携
- ドキュメント理解の高度化と、関連情報をたどる機能の強化
- 複雑な問いに対応するための複数プロンプトによる推論
- 重要な回答に対する、人による確認プロセスの任意導入
私たちが目指しているのは、エンジニア一人ひとりの作業環境そのものを、文脈を理解し、思考し続ける基盤へと進化させることです。日々のやり取りから学び、その知見をチーム全体へと還元していく――そのような循環を生み出す環境の実現を見据えています。
Catoにとどまらない意義
Savanti が示しているのは、単なる生産性向上ではありません。これまで一過性に消えていたチャットのやり取りを、蓄積され、検索可能な知識へと転換することで、組織の知のあり方そのものを変えていくという点にあります。そこから見えてくるのは、現代のエンジニアリング組織であれば広く応用可能な一つの考え方です。すなわち、協働が行われる場に推論するエージェントを組み込み、実際の文脈に根ざした形で機能させながら、組織の知識とともに進化させていくことです。
開発者やAIに携わる人にとっての示唆は明確です。RAG はあくまで基盤に過ぎません。真の価値は、AIエージェントが業務の流れの中で思考し、判断し、行動するようになったときにこそ発揮されるのです。
機密データが「画像」になるとき:DLPにおける機械学習型画像分類の導入
ブラックフライデーの緊急対応はもう不要:Elkjøp社がCatoで小売ITを変革した方法


単一のプラットフォームでOTを完全保護:CatoによるCISA緩和ガイドラインへの対応




