
Catoが生成系AIセキュリティの謎を解き明かし、ChatGPTへの組織からのアクセスを保護する方法


この1年、生成系AI(Generative AI)やChatGPTを中心に、AIのリスクについて無数の記事、予測、予言、予知が語られてきました。その範囲は、倫理から広範囲にわたる社会や労働力への影響まで多岐にわたります(今のところ、ターミネーターが現実のものになることはないと思いますが…)。
Catoのセキュリティ研究とエンジニアリングが、この予測と懸念に高い興味を示していたことから、ChatGPT によってもたらされるビジネスへのリスクを調査することを決めました。私たちの発見は、いくつかの重要な結論に要約することができます。
- ChatGPT などを使用している組織では現在、実際のリスク以上に恐怖心を煽るような行為が散見されます。
- 生産性におけるメリットは、リスクをはるかに上回っています。
- とはいえ、脅威の状況は急速に変化する可能性があるため、組織はChatGPTなどのツールで機密情報や所有権を持つ情報が使用されないよう、セキュリティ管理を導入する必要があります。
懸念事項
前述の、恐怖心を煽るような行為の多くは、ChatGPTとその基盤となる生成系AI技術の「プライバシー」という側面に関するものです。 主な懸念事項は、ChatGPTで共有されているデータは具体的にどうなるのかという点です(モデルをトレーニングするためにバックグラウンドでどのように使用されるのか、または使用されないのか、保管されている場合はその保管方法など)。
問題は、ユーザーが ChatGPT を操作する際のデータ侵害や企業の知的財産のデータ漏洩のリスクです。いくつかの典型的なシナリオを見てみましょう:
- ChatGPTを使用する従業員 – ソフトウェアエンジニアがAIにレビューしてもらうためにコードのブロックをアップロードするなど、ユーザーが所有権を持つ情報や機密情報をChatGPTにアップロードする。もしモデルがそのデータを使ってさらに自己学習した場合、後で該当のコードが不注意か悪意かによる他のアカウントへの返信を通じて漏れてしまう可能性はないのでしょうか?
現実には、その可能性は低く、実際に組織的な搾取を証明するものは発表されていません。 - サービス自体のデータ漏洩 – OpenAIが侵害されたり、ChatGPTのバグによってユーザーデータが漏洩した場合、ChatGPTを使用している組織はどのようなリスクにさらされるのでしょうか?機密情報がこのような形で漏れる可能性はあるのでしょうか?
現実の可能性としては、OpenAIのインフラストラクチャのバグが原因で、一部のユーザーが自分のアカウントで他のユーザーのチャットタイトルを見ることができたという、少なくとも1つの公開インシデントがOpenAIによって報告されている程度です。 - 独自の生成系AI実装 – AI はすでに、独自の専用 MITRE攻撃フレームワークである ATLAS を持っており、入力操作からデータ抽出、データポイズニング、推論攻撃などに至るまでの手法を備えています。こうした手法で、組織の機密データが盗まれる可能性はあるのでしょうか?
答えはイエスです。このテーマに関する最近の Cato リサーチポスト の投稿で紹介されているように、手法は無害なものから理論的なもの、実践的なものまで多岐にわたりますが、いずれ生成系 AIの独自実装のセキュリティ保護についてはこの記事に含まれていません。
常に私たちが行うことにはリスクが伴います。インターネット接続にはリスクがあるにも関わらず、毎日何十億人ものユーザーがインターネットを利用しています。ただ、適切な予防策を講じる必要があるだけです。ChatGPTにも同じことが言えます。 いくつかのシナリオは他のシナリオよりも可能性が高いですが、現実的な観点から問題を分析することで、簡単なセキュリティ対策を実施して安心することができます。
Everything You Wanted To Know About AI Security But Were Afraid To Ask | Watch the Webinar生成系AIのセキュリティ管理
最新のSASEアーキテクチャは、CASBとDLPをプラットフォームの一部として含んでおり、これらのユースケースに簡単に対応できます。Catoのプラットフォームはまさにそのように設計されており、ChatGPTや同様のアプリケーションを組織内で安全に使用するためのレイヤーアプローチを提供します。
- どのアプリケーションを許可し、どのユーザー/グループにそのアプリケーションの使用を許可するかを制御
- 送信を許可するテキスト/データを制御
- アプリケーション固有のオプション(データ保持のオプトアウト、テナント制御など)の実施
最初のアプローチは、どのAIアプリケーションの使用が許可され、どのユーザーグループに使用が許可されるかを定義すること。これは、「Generative AI Tools」アプリケーション・カテゴリーと、許可する特定のツール、例えば、すべての生成系AIツールをブロックし、「OpenAI」のみを許可するという組み合わせを指定して行うことができます。
高度なDLPソリューションの基礎となるのは、データを確実に分類する能力であり、データの完全一致、静的ルール、正規表現といった従来のアプローチは、単独で使用する場合、もはや時代遅れとなっています。例えば、クレジットカード番号は正規表現を使えば簡単にブロックできますが、金融文書を含む現実のシナリオでは、機密情報が漏れる可能性のある手法は他にもたくさんあります。ただ機能するより、高度なソリューションがなければ、データの変化やポリシーの微調整に追従しようとしてもほとんど意味をなしません。
ここで、CatoのML(機械学習)データ分類器の出番です。これは、Catoが長年にわたってプラットフォームに統合してきたAI/ML機能の広範な配列に、すでに追加された最新バージョンです。何百万もの文書とデータタイプでトレーニングされた当社のLLM(大規模言語モデル)は、ネイティブでリアルタイムに文書を識別することができ、このようなポリシーに最適なツールとして機能します。
ChatGPTで特定のテキスト入力をブロックするシナリオを見てみましょう。例えば、プロンプトを通して機密データや機密データをアップロードする場合です。たとえば、法務部門の従業員が NDA (機密保持契約) 文書の草案を作成し、最終的に完成する前にChatGPT に文書を渡して、内容を確認して改善を提案したり、文法を確認したりするとします。特に文書に PII が含まれている場合、これは明らかに会社のプライバシーポリシーに違反する可能性があります。
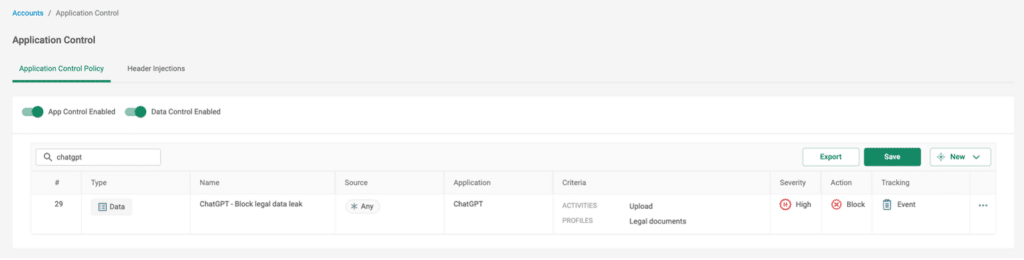
図1 – ML 分類子を使用して法的文書のアップロードをブロックするルールの例
もっと深く知る
包括的なCASBソリューションの実力と柔軟性をさらに実証するために、ChatGPTのプライバシーコントロールのもう一つの側面を見てみましょう。設定には「チャット履歴とトレーニング」を無効にするオプションがあり、基本的にユーザーは自分のデータがモデルのトレーニングに使用され、OpenAIのサーバーに保持されないように決めることができます。
この重要なプライバシー制御はデフォルトで無効になっています。つまり、デフォルトではすべてのチャットが OpenAI によって保存されます。これはユーザーがオプトインされていることを意味し、組織が ChatGPT を使用するビジネス関連の活動においては避けるべきでしょう。
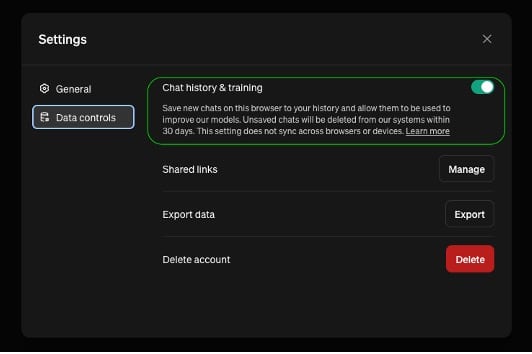
図2 – ChatGPTのデータ制御構成
ChatGPTをユーザーが柔軟に使用できるようにする一方、より厳格な制御を適用することとのバランスを取るための良案として、チャット履歴が無効になっている ChatGPT でのチャットのみを許可することが挙げられます。CatoのCASBグラニュラーChatGPTアプリケーションは、ユーザーがチャット履歴にオプトインしているかどうかをリアルタイムで区別し、データが送信される前に接続をブロックすることができるため、このような柔軟性が可能になります。
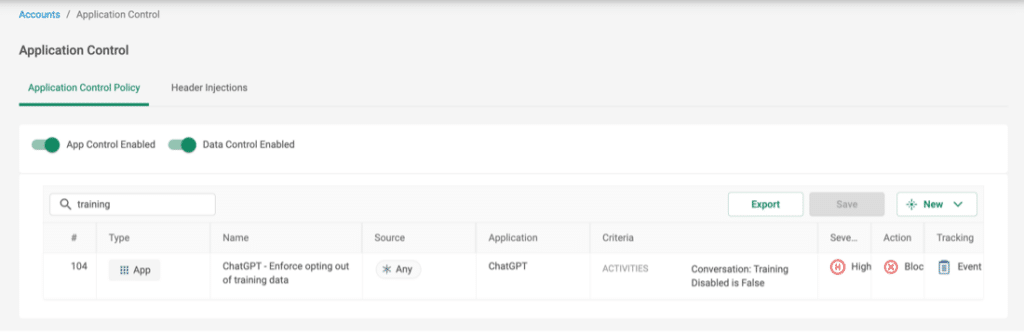
図3 – 「トレーニング・オプトアウト」実施ルールの例
最後に、上記の代替 (または補完) アプローチとして、ChatGPT アクセス用のテナント コントロールを構成することができます。つまり、アプリケーションへのアクセス時にどのアカウントが許可されるかを強制することができます。考えられるシナリオは次の通りです。組織は ChatGPT に企業アカウントを持っており、デフォルトのセキュリティおよびデータ制御ポリシーが全従業員に適用されており、従業員が無料枠の個人アカウントで ChatGPT にアクセスしないようにしたいと考えています。

図4 – テナント・コントロールのルール例
CatoのCASBとDLPについての詳細はこちらをご覧ください:
ブラックフライデーの緊急対応はもう不要:Elkjøp社がCatoで小売ITを変革した方法


Savanti:エージェント型AIがCatoの研究開発効率をどう高めたか


再びリーダーに:Cato Networks、2025年Gartner® Magic Quadrant™のSASEプラットフォーム部門で評価される





