Demystifying GenAI security, and how Cato helps you secure your organizations access to ChatGPT



Table of Contents
|
Listen to post:
🔊 This audio player requires that "Preferences" cookies be accepted
|
Over the past year, countless articles, predictions, prophecies and premonitions have been written about the risks of AI, with GenAI (Generative AI) and ChatGPT being in the center. Ranging from its ethics to far reaching societal and workforce implications (“No Mom, The Terminator isn’t becoming a reality… for now”).
Cato security research and engineering was so fascinated about the prognostications and worries that we decided to examine the risks to business posed by ChatGPT. What we found can be summarized into several key conclusions:
- There is presently more scaremongering than actual risk to organizations using ChatGPT and the likes.
- The benefits to productivity far outweigh the risks.
- Organizations should nonetheless be deploying security controls to keep their sensitive and proprietary information from being used in tools such as ChatGPT since the threat landscape can shift rapidly.
Concerns explored
A good deal of said scaremongering is around the privacy aspect of ChatGPT and the underlying GenAI technology. The concern — what exactly happens to the data being shared in ChatGPT; how is it used (or not used) to train the model in the background; how it is stored (if it is stored) and so on.
The issue is the risk of data breaches and data leaks of company’s intellectual property when users interact with ChatGPT. Some typical scenarios being:
- Employees using ChatGPT – A user uploads proprietary or sensitive information to ChatGPT, such as a software engineer uploading a block of code to have it reviewed by the AI. Could this code later be leaked through replies (inadvertently or maliciously) in other accounts if the model uses that data to further train itself?
Spoiler: Unlikely and no actual demonstration of systematic exploitation has been published. - Data breaches of the service itself – What exposure does an organization using ChatGPT have if OpenAI is breached, or if user data is exposed through bugs in ChatGPT? Could sensitive information leak this way?
Spoiler: Possibly, at least one public incident was reported by OpenAI in which some users saw chat titles of other users in their account due to a bug in OpenAI’s infrastructure. - Proprietary GenAI implementations – AI already has its own dedicated MITRE framework of attacks, ATLAS, with techniques ranging from input manipulation to data exfiltration, data poisoning, inference attacks and so on. Could an organization’s sensitive data be stolen though these methods?
Spoiler: Yes, methods range from harmless, to theoretical all the way to practical, as showcased in a recent Cato Research post on the subject, in any case securing proprietary implementation of GenAI is outside the scope of this article.
There’s always a risk in everything we do. Go onto the internet and there’s also a risk, but that doesn’t stop billions of users from doing it every day. One just needs to take the appropriate precautions. The same is true with ChatGPT. While some scenarios are more likely than others, by looking at the problem from a practical point of view one can implement straightforward security controls for peace of mind.
Everything You Wanted To Know About AI Security But Were Afraid To Ask | Watch the WebinarGenAI security controls
In a modern SASE architecture, which includes CASB & DLP as part of the platform, these use-cases are easily addressable. Cato’s platform being exactly that, it offers a layered approach to securing usage of ChatGPT and similar applications inside the organization:
- Control which applications are allowed, and which users/groups are allowed to use those applications
- Control what text/data is allowed to be sent
- Enforcing application-specific options, e.g. opting-out of data retention, tenant control, etc.
The initial approach is defining what AI applications are allowed and which user groups are allowed to use them, this can be done by a combination of using the “Generative AI Tools” application category with the specific tools to allow, e.g., blocking all GenAI tools and only allowing “OpenAI”.
A cornerstone of an advanced DLP solution is its ability to reliably classify data, and the legacy approaches of exact data matches, static rules and regular expressions are now all but obsolete when used on their own. For example, blocking a credit card number would be simple using a regular expression but in real-life scenarios involving financial documents there are many other means by which sensitive information can leak. It would be nearly pointless to try and keep up with changing data and fine-tuning policies without a more advanced solution that just works.
Luckily, that is exactly where Cato’s ML (Machine Learning) Data Classifiers come in. This is the latest addition to Cato’s already expansive array of AI/ML capabilities integrated into the platform throughout the years. Our in-house LLM (Large Language Model), trained on millions of documents and data types, can natively identify documents in real-time, serving as the perfect tool for such policies.
Let’s look at the scenario of blocking specific text input with ChatGPT, for example uploading confidential or sensitive data through the prompt. Say an employee from the legal department is drafting an NDA (non-disclosure agreement) document and before finalizing it gives it to ChatGPT to go over it and suggest improvement or even just go over the grammar. This could obviously be a violation of the company’s privacy policies, especially if the document contains PII.
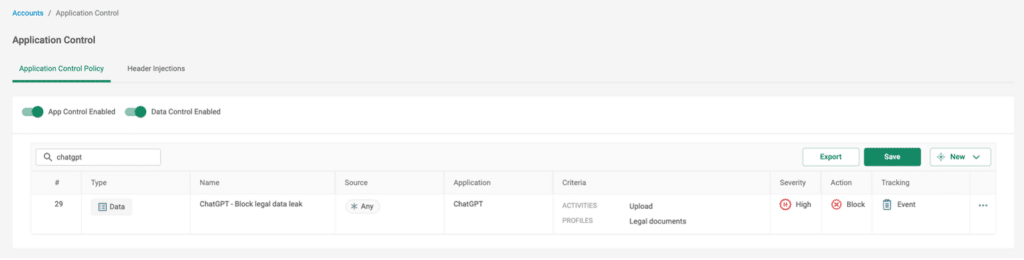
Figure 1 – Example rule to block upload of Legal documents, using ML Classifiers
We can go deeper
To further demonstrate the power and flexibility of a comprehensive CASB solution, let us examine an additional aspect of ChatGPT’s privacy controls. In ChatGPT, one may choose to have a temporary chat, where, according to ChatGPT, won’t appear in the user’s history, won’t be used for updating ChatGPT’s memory and won’t be used for training their models.
This important privacy control is disabled by default, that is by default all chats ARE saved by OpenAI, aka users are opted-in, something an organization may want to avoid in any work-related activity with ChatGPT.
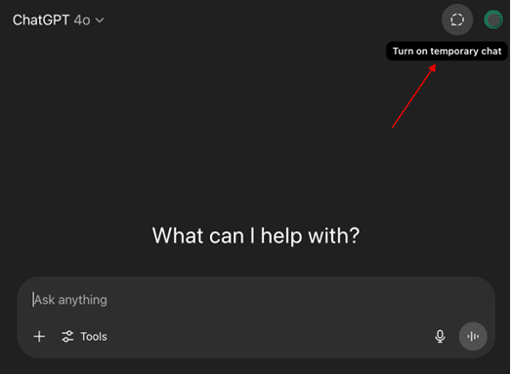
Figure 2 – ChatGPT’s data control configuration
A good way to strike a balance between allowing users the flexibility to use ChatGPT but under stricter controls is only allowing temporary chats in ChatGPT. Cato’s CASB granular ChatGPT application allows for this flexibility by being able to distinguish in real-time if a user is in a temporary chat and block the connection before data is sent.
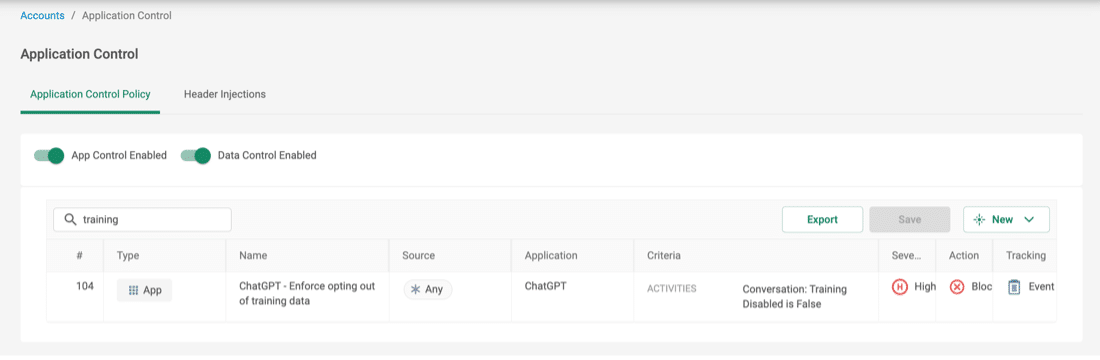
Figure 3 – Example rule for “training opt-out” enforcement, allowing only temporary chats in ChatGPT
Lastly, as an alternative (or complementary) approach to the above, it is possible to configure Tenant Control for ChatGPT access, i.e., enforce which accounts are allowed when accessing the application. In a possible scenario an organization has corporate accounts in ChatGPT, where they have default security and data control policies enforced for all employees, and they would like to make sure employees do not access ChatGPT with their personal accounts on the free tier.
Tenant control can be achieved per activity. For this use case, Cato recommends to control the tenant for all the granular activities in ChatGPT, as well as for the OpenAI Login:


Figure 4 – Example rules for tenant control: ChatGPT activities + OpenAI Login
To learn more about Cato’s CASB and DLP visit:
Related Articles
Savanti: How Agentic AI Supercharge Cato’s R&D Efficiency


OpenClaw: Cato Governance Controls and Sector Exposure Insights from the Cato SASE Platform

Cato CTRL™ Threat Research: Two Vulnerabilities in Anthropic’s MCP SDK Enable OAuth Token Theft and Supply Chain Attacks




