




Gradual by Design: Was der Ausfall von Cloudflare über robuste SASE-Architekturen und -Betriebe verrät

Inhaltsverzeichnis
- 1. Eine sehr kurze Zusammenfassung des Cloudflare-Vorfalls
- 2. Was wir bei Cato tun, um zu verhindern, dass eine schlechte Änderung zu einem Ausfall wird
- 3. Eine für Resilienz ausgelegte SASE-Architektur
- 4. Was wir gesehen haben: Sofortige Sichtbarkeit des Ausfalls
- 5. Vorfälle passieren, aber Sie können trotzdem die Kontrolle behalten
Am 18. November 2025 störte eine einzige Änderung der Konfigurationsdatei bei Cloudflare den Zugriff auf große Teile des Webs.
Um 11:20 UTC begann das Netzwerk von Cloudflare, eine Welle von HTTP 5xx-Fehlern zurückzugeben. Nutzer, die Dienste wie X (ehemals Twitter), ChatGPT/OpenAI, Ikea, Canva und viele andere erreichen wollten, sahen plötzlich Cloudflare-Fehlerseiten anstelle der erwarteten Anwendungen. Cloudflare hat das Problem behoben, den Dienst wiederhergestellt und einen detaillierten öffentlichen Bericht veröffentlicht.
Der Ausfall könnte den allgemeinen Markt betroffen haben, aber er birgt wichtige Lektionen für jeden, der eine SASE-Bereitstellung in Betracht zieht. Netzwerk- und Sicherheitsarchitektur sowie die dahinterstehenden Betriebspraktiken prägen direkt die Servicebereitstellung und -kontinuität. Vorfälle sind unvermeidlich, aber ihre Auswirkungen können und sollten eingegrenzt werden. Und wenn es tatsächlich zu Ausfällen kommt, verdeutlicht der Cloudflare-Ausfall die Notwendigkeit, den Kunden klare Transparenz und Kontrolle zu geben, damit sie schnell verstehen können, was passiert, welche Anwendungen und Benutzer betroffen sind und welche Maßnahmen zu ergreifen sind.
Eine sehr kurze Zusammenfassung des Cloudflare-Vorfalls
Der Blogbeitrag von Cloudflare beschreibt den Vorfall im Detail, kurz gesagt: Eine Änderung der Datenbankberechtigungen führte dazu, dass sich die Abfrage, die eine Bot-Management-„Feature“-Datei generiert, anders verhielt, wodurch die Datei größer als erwartet wurde und ein Limit in der Traffic-Engine von Cloudflare überschritten wurde. Da diese Datei alle paar Minuten aktualisiert und global verteilt wird, löste die fehlerhafte Version schnell weit verbreitete HTTP 5xx-Fehler über die Cloudflare-Frontend-Dienste aus, bis Cloudflare ihre Verbreitung stoppte und auf eine bekannte gute Datei zurückrollte.
Die betriebliche Lektion ist klar: Eine Netzwerkänderung zu schnell über eine globale Plattform zu pushen, birgt das Risiko, die Servicebereitstellung zu stören. Genau aus diesem Grund sind schrittweise Bereitstellung, Sicherheitsvorkehrungen und einfache Rückrollmöglichkeiten grundlegende Designprinzipien für die Cato SASE Platform. In den folgenden Abschnitten werden wir uns darauf konzentrieren, wie diese Prinzipien auf unserer Plattform, PoPs, Sockets, Clients, Funktionen und insbesondere Feeds angewendet werden und warum das im Kontext eines Vorfalls wie dem von Cloudflare wichtig ist.
SASE Champion’s Playbook | Download the eBookWas wir bei Cato tun, um zu verhindern, dass eine schlechte Änderung zu einem Ausfall wird
Im Internet ist der gefährlichste Satz im Betrieb: „Lass es uns überall bereitstellen.“ Unsere Antwort: Jede Änderung ist schrittweise, überwacht und umkehrbar.
Schrittweise Einführung über die Plattform
Unser öffentlicher Artikel Verständnis der Einführung in die Cato Cloud erklärt dieses Modell. Wir führen Änderungen schrittweise in kontrollierten Phasen über unser Netzwerk ein:
- Cato Cloud (PoPs & Management-Ebene): Die PoPs werden alle zwei Wochen aktualisiert, wobei die Inhalte über einen Zeitraum von etwa zwei Wochen PoP für PoP veröffentlicht werden. Die Verwaltungsanwendung wird wöchentlich aktualisiert, aber neue Funktionen und Möglichkeiten werden schrittweise über die Konten aktiviert.
- Sockets & Clients: Neue Versionen werden in phasenweisen Kohorten bereitgestellt, beginnend mit kleinen Gruppen von Standorten oder Benutzern und nur dann erweitert, wenn die Gesundheitsindikatoren gut aussehen.
Das Ergebnis: Keine einzelne Version oder Änderung landet jemals gleichzeitig auf 100 % der PoPs, Standorte oder Endpoints.
Funktionen und Feeds: Schnell, aber dennoch schrittweise
Wir verfahren ähnlich für neue Funktionen (Fähigkeiten) und Sicherheits- und Richtlinienfeeds:
- Funktionen: Neue Möglichkeiten werden mit gestaffelter Aktivierung (interne Tests, ausgewählte Kunden oder Regionen und dann breitere Einführung) aktiviert, mit zentralen Kontrollen, um schnell zu deaktivieren, falls erforderlich.
- Feeds: Sicherheits- und Richtlinienfeeds (Indikatoren, Signaturen, Modelle und Konfigurationsinhalte) müssen zwar schnell aktualisiert werden, aber dennoch in kontrollierten Schritten eingeführt werden, mit zentraler Überwachung auf Fehler und Anomalien sowie Rollback und Einfrieren, falls sich ein Feed unerwartet verhält.
Ob es sich um eine größere Einführung, wie eine neue Funktion, oder um eine kleinere Änderung, wie ein Update eines Sicherheitsfeeds, handelt – alles wird schrittweise eingeführt, zentral überwacht und durch Rollback- und Freeze-Kontrollen abgesichert, um zu verhindern, dass ein fehlerhaftes Update einen großflächigen Ausfall verursacht.
Die Ausbreitung beobachten, nicht nur den Endzustand
Wir schauen uns nicht nur an, ob es jetzt funktioniert. Wir verfolgen, wie jede Änderung über unsere Plattform hinweg wirkt. Änderungen an Funktionen und Feeds werden durch einen gut gestalteten Zyklus der schrittweisen Erhöhung der Exposition bereitgestellt, um die Auswirkungen auf Produktionskunden zu begrenzen. Eine Änderung durchläuft Continuous Integration / Continuous Delivery (CI/CD) und anschließend Early Availability (EA) für eine begrenzte Anzahl von PoPs oder Kunden und geht schließlich in die General Availability (GA) über. Jede Stufe hat spezifische Gesundheitskriterien, die erfüllt sein müssen, bevor man in die nächste Stufe aufsteigen kann. Der Aufstieg wird zudem telemetriegesteuert und nicht künstlich durch einen Kalender geplant. Kurz gesagt, die Verbreitung selbst ist ein Signal, das wir beobachten, um zu entscheiden, ob wir weitermachen, pausieren oder zurücksetzen.
Rollback und Schutzvorrichtungen sind integriert
Rollback ist eingeplant, nicht improvisiert:
- Jede Änderung hat einen definierten Rollback-Pfad.
- PoP-, Socket- und Client-Rollouts können zurückgesetzt werden, wenn Probleme auftreten.
- Zentrale Kontrollen ermöglichen uns, eine problematische Komponente oder einen Feed schnell zu deaktivieren.
Darüber hinaus unterliegen weit verbreitete Artefakte vor der Veröffentlichung Beschränkungen und Validierungen (z. B. Größen- und Strukturprüfungen), wodurch das Risiko verringert wird, dass eine einzelne falsch konfigurierte Datei weitreichende Auswirkungen haben kann.
Eine für Resilienz ausgelegte SASE-Architektur
Cato betreibt einen globalen privaten Backbone von PoPs, das das öffentliche Internet für den Kundenverkehr ersetzt. Jeder PoP betreibt unsere Single Pass Cloud Engine (SPACE), die Netzwerk- und Sicherheitsfunktionen (SWG, CASB, ZTNA, FWaaS mit fortschrittlicher Bedrohungsprävention usw.) in einem einzigen Software-Stack vereint.
Wichtige Resilienzvorteile:
- Ein selbstheilender Backbone, der kontinuierlich Latenz, Verlust und Jitter misst und um Probleme herum leitet
- Skalierung, hohe Verfügbarkeit, damit lokale Probleme nicht zu globalen Ausfällen werden
- Einheitliche Richtlinie und Sichtbarkeit, die den gesamten Weg vom Benutzer zur Anwendung zeigt
Während eines Ereignisses wie dem Cloudflare-Ausfall fungiert diese Architektur als Stoßdämpfer: Sie leitet wo möglich betroffene Regionen um, optimiert nicht betroffene Apps und gibt Ihnen klare, umsetzbare Einblicke in das, was passiert, wo und mit wem.
Was wir gesehen haben: Sofortige Sichtbarkeit des Ausfalls
Wenn ein großer Anbieter stolpert, stellen IT-Teams immer zuerst die gleiche Frage:
„Liegt es an uns, unserer SASE-Plattform oder an etwas anderem wie dem Internet, Cloudflare oder dem Anwendungsanbieter?“
Da Cato Netzwerk, Sicherheit und digitales Monitoring vereint, konnten unsere Kunden das am 18. November schnell beantworten. In Abbildung 1 ist ein starker Anstieg der HTTP-Fehler bei OpenAI während des Vorfalls zu erkennen, während WAN-Pfade und andere SaaS-Anwendungen einwandfrei funktionieren. Dies deutet eindeutig auf ein Problem bei der vorgelagerten Anwendung/dem vorgelagerten Anbieter hin und nicht auf ein Problem im Netzwerk von Cato oder dem Kunden.
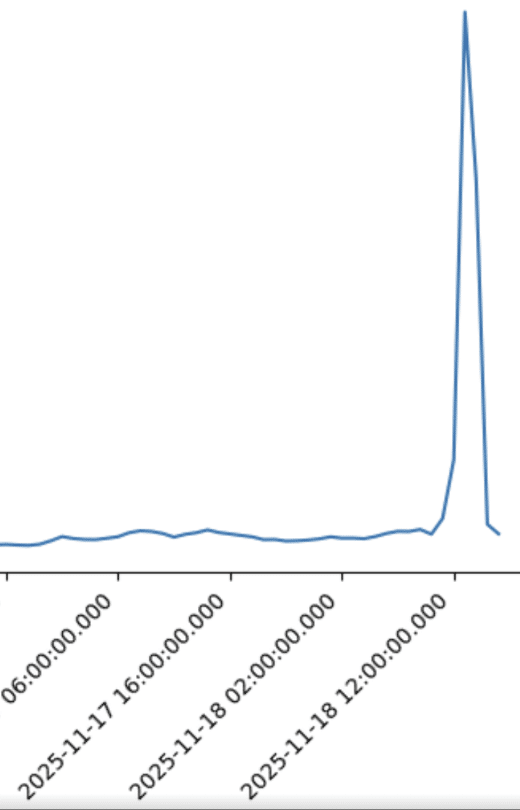
Abbildung 1. HTTP-Fehler, die bei OpenAI während des Vorfalls beobachtet wurden
Die Cato Management Application fügt dann eine Sicht auf das digitale Erlebnis hinzu, die zeigt, wo, wer und wie Benutzer betroffen sind. Die Abbildungen 2 und 3 veranschaulichen dies für ChatGPT und X.com, mit HTTPS-Fehlern und Erfahrungspunkten nach Standort und Benutzergruppe.
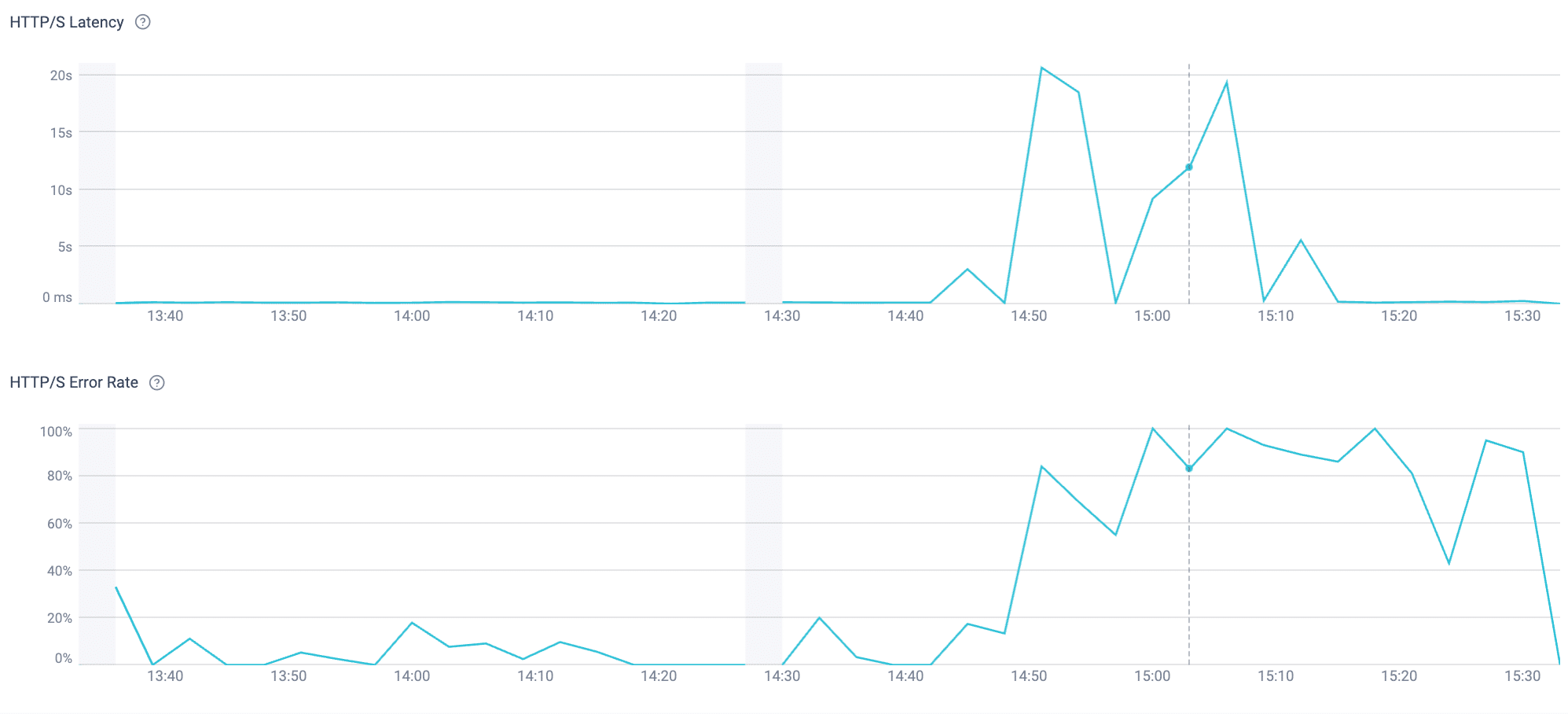
Abbildung 2. HTTPS-Fehlerüberwachung für ChatGPT aus der Cato Management Application

Abbildung 3. Durchschnittlicher Erfahrungspunkt für X.com, der eine Verschlechterung zeigt
Anstatt nur zu hören „ChatGPT ist down“, kann die IT sofort sehen, welche Apps betroffen sind, welche in Ordnung sind und dass dieser spezifische Vorfall mit Cloudflare zusammenhängt und upstream ist, alles unterstützt durch Daten.
Vorfälle passieren, aber Sie können trotzdem die Kontrolle behalten
Der Ausfall von Cloudflare am 18. November ist eine weitere Erinnerung an eine breitere Realität: Die gesamte Branche hängt von einer kleinen Anzahl kritischer Cloud-Anbieter ab, und diese Anbieter verlassen sich auf zentralisierte Konfigurationen und schnell aktualisierte, ML-gesteuerte Artefakte. Wenn ein latenter Fehler in diese Pipeline gelangt, können die Folgen weitreichend sein.
Bei Cato gestalten wir unsere Plattform so, dass ähnliche großflächige Ausfälle in unserem Netzwerk verhindert werden, indem wir Sicherheit und Resilienz in jede Phase des Änderungsmanagements einbauen:
- Allmähliche Bereitstellung, um sicherzustellen, dass kein Update gleichzeitig das gesamte Netzwerk erreicht.
- Überwachungsüberwachung, die es uns ermöglicht, eine schlechte Änderung zu stoppen, bevor sie sich ausbreitet.
- Integrierter Rollback, mit klaren, getesteten Verfahren zur schnellen Wiederherstellung des Dienstes und zur Minimierung von Störungen.
- Vorproduktionsvalidierung und strenge Kontrollen von globalen Artefakten, um die Wahrscheinlichkeit eines Vorfalls zu minimieren.
- Ein resilienter SASE-Backbone und umfassende End-to-End-Sichtbarkeit, damit Sie genau wissen, welche Apps, Benutzer und Standorte betroffen sind.
Und wenn es zu Ausfällen außerhalb unseres Netzwerks kommt, helfen wir Ihnen, deren Auswirkungen zu minimieren und die Kontrolle zu behalten – unabhängig davon, was vorgelagert passiert.
Weitere Artikel
Cato Networks erhält zum ersten Mal 5-Sterne-Bewertung im CRN Partner Program Guide 2025


Lernen Sie Catos MCP-Server kennen: Ein intelligenter Ansatz für die Integration von KI in Ihre IT- und Sicherheitsprozesse