Cato XDR Storyteller – Integrating Generative AI with XDR to Explain Complex Security Incidents



Table of Contents
|
Listen to post:
Getting your Trinity Audio player ready...
|
Generative AI (à la OpenAI’s GPT and the likes) is a powerful tool for summarizing information, transformations of text, transformation of code, all while doing so using its highly specialized ability to “speak” in a natural human language.
While working with GPT APIs on several engineering projects an interesting idea came up in brainstorming, how well would it work when asked to describe information provided in raw JSON into natural language?
The data in question were stories from our XDR engine, which provide a full timeline of security incidents along with all the observed information that ties to the incident such as traffic flows, events, source/target addresses and more.
When inputted into the GPT mode, even very early results (i.e. before prompt engineering) were promising and we saw a very high potential to create a method to summarize entire security incidents into natural language and providing SOC teams that use our XDR platform a useful tool for investigation of incidents.

Thus, the “XDR Story Summary” project, aka “XDR Storyteller” came into being, which is integrating GenAI directly into the XDR detection & response platform in the Cato Management Application (CMA).
The summaries are presented in natural language and provide a concise presentation of all the different data points and the full timeline of an incident.
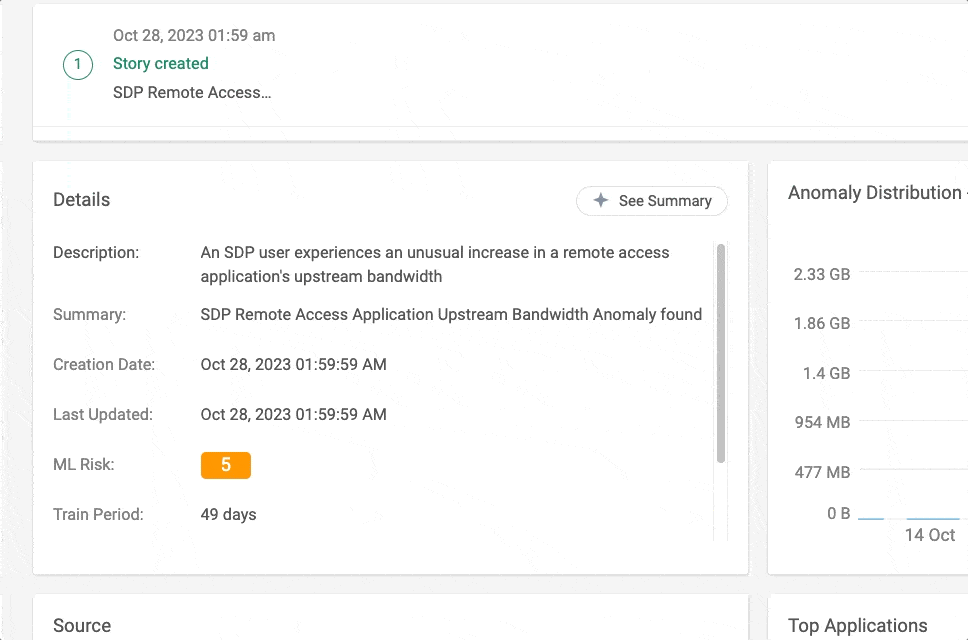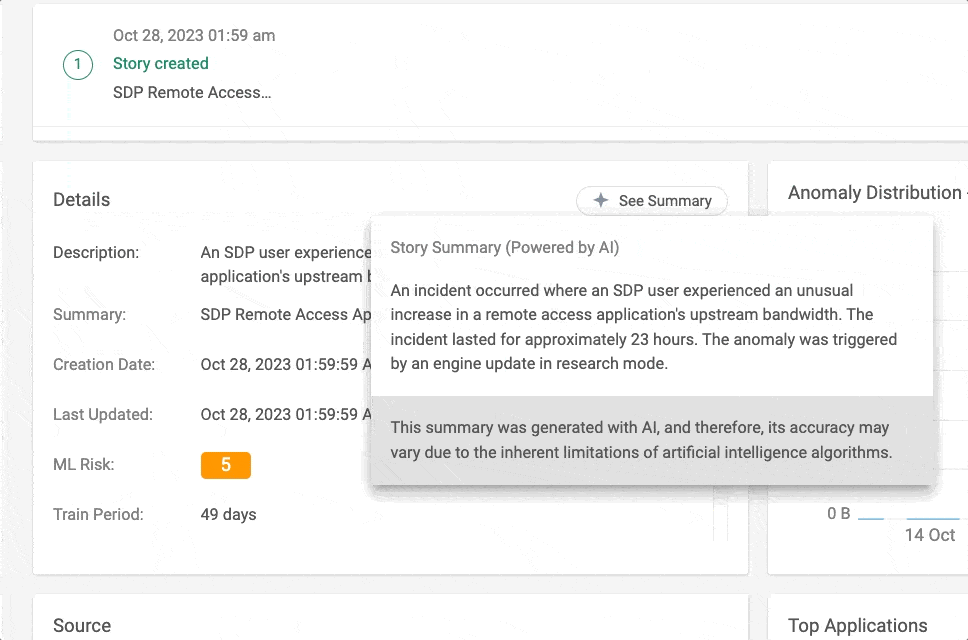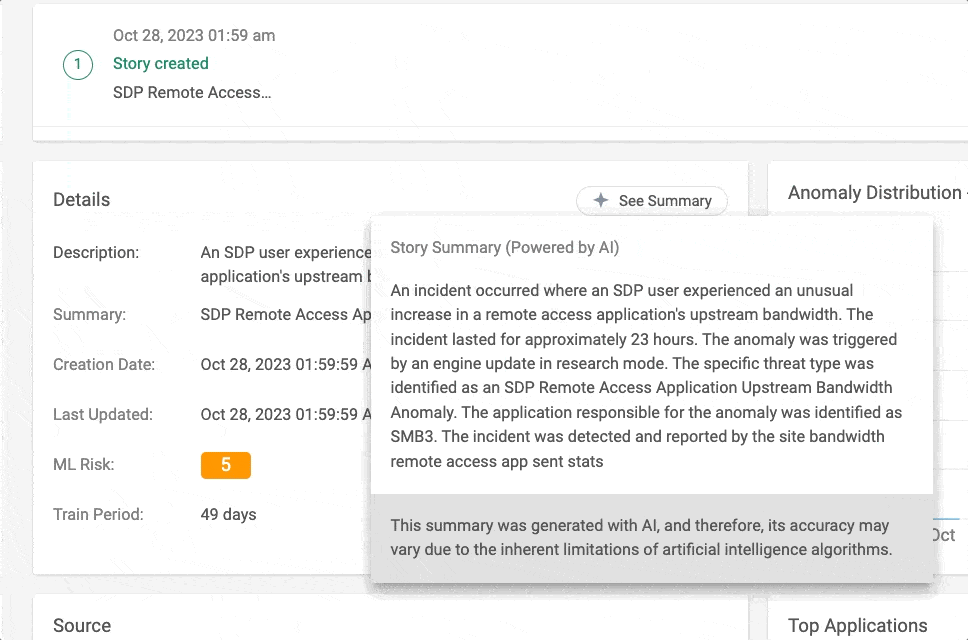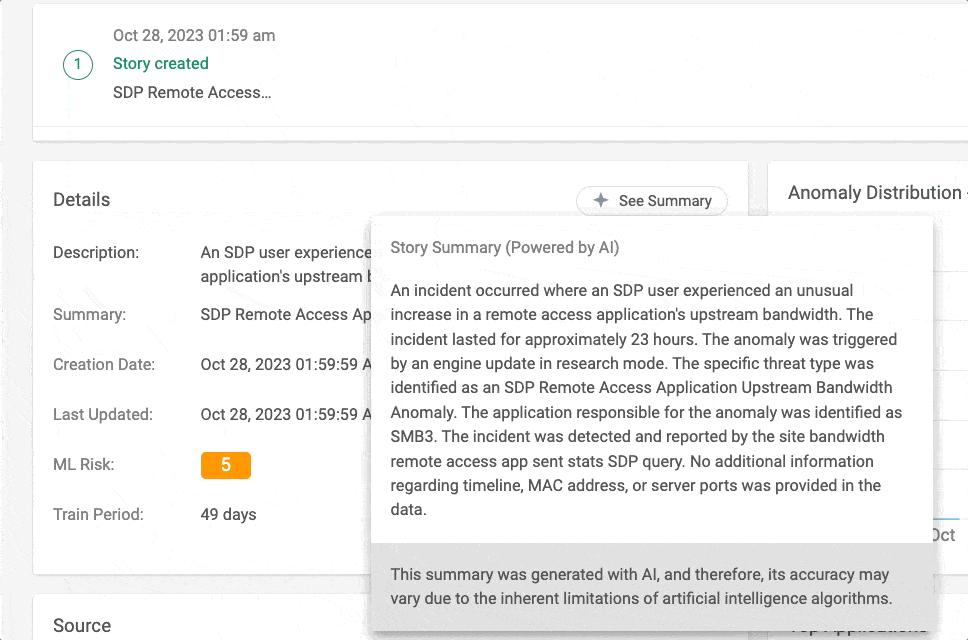
Figure 1 – Story Summary in action in Cato Management Application (CMA)
These are just two examples of the many different scenarios we POCed prior to starting development:
Example use-case #1 – deeper insight into the details of an incident.
GPT was able to add details into the AI summary which were not easily understood from the UI of the story, since it is comprised of multiple events.
GPT could infer from a Suspicious Activity Monitoring (SAM) event, that in addition to the user trying to download a malicious script, he attempted to disable the McAfee and Defender services running on the endpoint.
The GPT representation is built from reading a raw JSON of an XDR story, and while it is entirely textual which puts it in contrast to the visual UI representation it is able to combine data from multiple contexts into a single summary giving insights into aspects that can be complex to grasp from the UI alone.
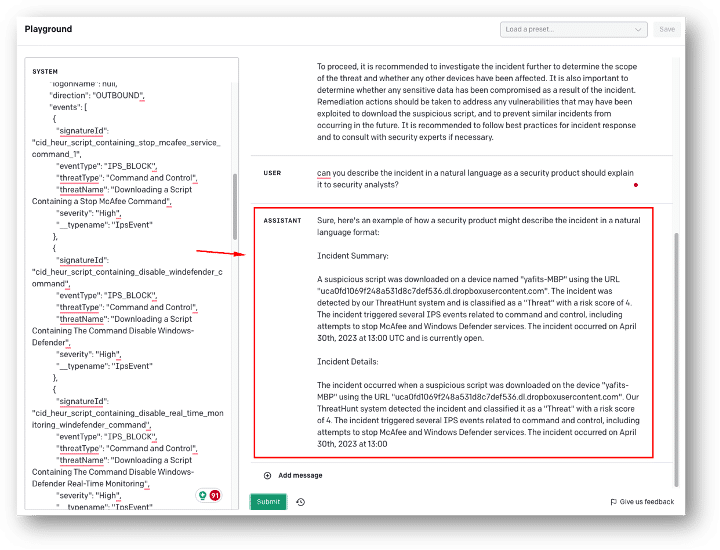
Figure 2 – Example of a summary of a raw JSON, from the OpenAI Playground
Example use-case #2 – Using supporting playbooks to add remediation recommendations on top of the summary.
By giving GPT an additional source of data via a playbook used by our Support teams, he was able to not only summarize a network event but also provide a concise Cato-specific recommended actions to take to resolve/investigate the incident.
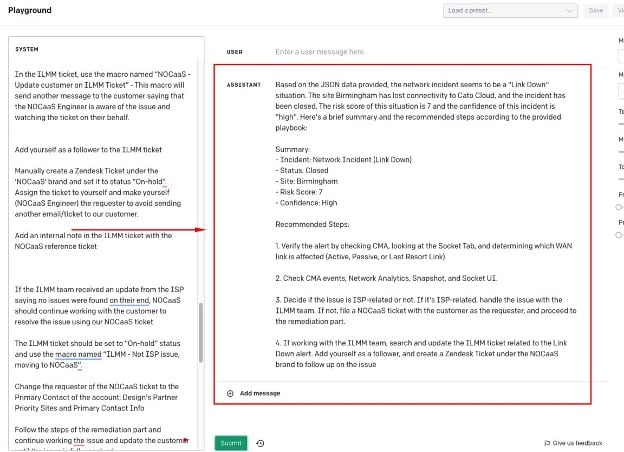
Figure 3 – Example of providing GPT with additional sources of data, from the OpenAI Playground
Picking a GenAI model
There are multiple aspects to consider when integrating a 3rd-party AI service (or any service handling your data for that matter), some are engineering oriented such as how to get the best results from the input and others are legal aspects pertaining to handling of our and our customer’s data.
Before defining the challenges of working with a GenAI model, you actually need to pick the tool you’ll be integrating, while GPT-4 (OpenAI) might seem like the go-to choice due to its popularity and impressive feature set it is far from being the only option, examples being PaLM(Google), LLaMA (Meta), Claude-2 (Anthropic) and multiple others.
We opted for a proof-of-concept (POC) between OpenAI’s GPT and Amazon’s Bedrock which is more of an AI platform allowing to decide which model to use (Foundation Model – FM) from a list of several supported FMs.
The Industry’s First SASE-based XDR Has Arrived | Download the eBookWithout going too much into the details of the POC in this specific post, we’ll jump to the result which is that we ended up integrating our solution with GPT. Both solutions showed good results, and going the Amazon Bedrock route had an inherent advantage in the legal and privacy aspects of moving customer data outside, due to:
- Amazon being an existing sub-processor since we widely use AWS across our platform.
- It is possible to link your own VPC to Bedrock avoiding moving traffic across the internet.
Even so due to other engineering considerations we opted for GPT, solving the privacy hurdle in another way which we’ll go into below.
Another worthy mention, a positive effect of running the POC is that it allowed us to build a model-agnostic design leaving the option to add additional AI sources in the future for reliability and better redundancy purposes.
Challenges and solutions
Let’s look at the challenges and solutions when building the “Storyteller” feature:
Prompt engineering & context – for any task given to an AI to perform it is important to frame it correctly and give the AI context for an optimal result.
For example, asking ChatGPT “Explain thermonuclear energy” and “Explain thermonuclear energy for a physics PHD” will yield very different results, and the same applies for cybersecurity. Since the desired output is aimed at security and operations personnel, we should therefore give the AI the right context, e.g. “You are an MDR analyst, provide a comprehensive summary where the recipient is the customer”.
For better context, other than then source JSON to analyze, we add source material that GPT should use for the reply. In this case to better understand
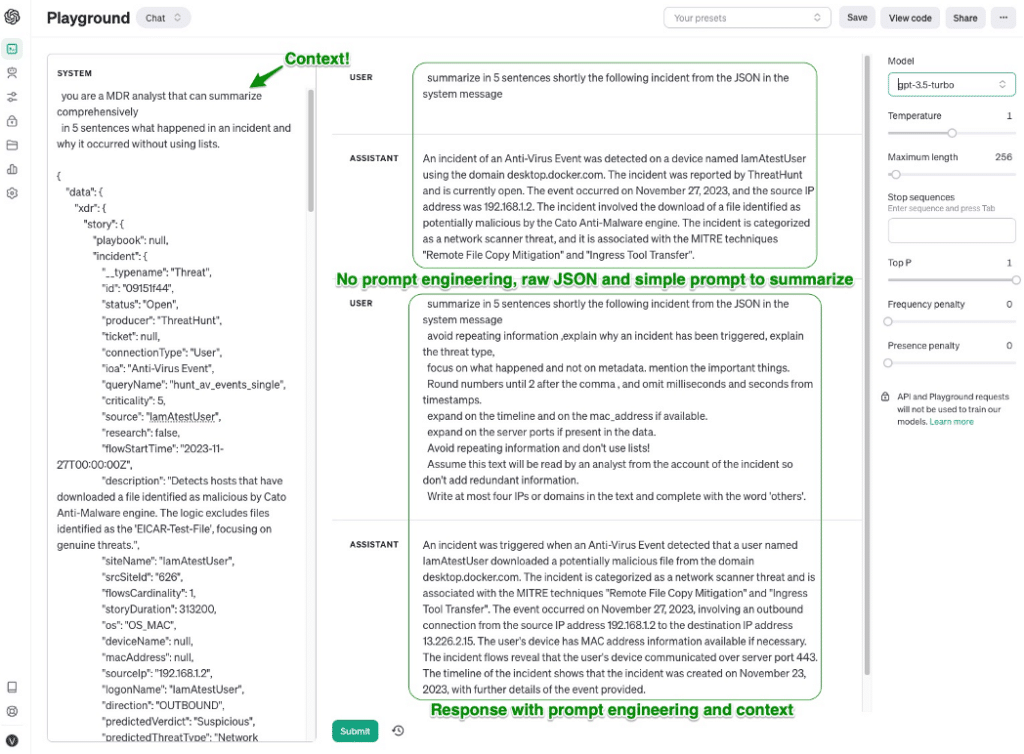
Figure 4 – Example of prompt engineering research from the OpenAI Playground
Additional prompt statements can help control the output formatting and verbosity. A known trait of GenAI’s is that they do like to babble and can return excessively long replies, often with repetitive information. But since they are obedient (for now…) we can shape the replies by adding instructions such as “avoid repeating information” or “interpret the information, do not just describe it” to the prompts.
Other prompt engineering statements can control the formatting itself of the reply, so self-explanatory instructions like “do not use lists”, “round numbers if they are too long” or “use ISO-8601 date format” can help shape the end result.
Data privacy – a critical aspect when working with a 3rd party to which customer data which also contains PII is sent, and said data is of course also governed by the rigid compliance certifications Cato complies with such as SOC2, GDPR, etc.
As mentioned above in certain circumstances such as when using AWS this can be solved by keeping everything in your own VPC, but when using OpenAI’s API a different approach was necessary.
It’s worth noting that when using OpenAI’s Enterprise tier then indeed they guarantee that your prompts and data are NOT used for training their model, and other privacy related aspects like data retention control are available as well but nonetheless we wanted to address this on our side and not send Personal Identifiable Information (PII) at all.
The solution was to encrypt by tokenization any fields that contain PII information before sending them. PII information in this context is anything revealing of the user or his specific activity, e.g. source IP, domains, URLs, geolocation, etc.
In testing we’ve seen that not sending this data has no detrimental effect on the quality of the summary, so essentially before compiling the raw output to send for summarization we perform preprocessing on the data. Based on a predetermined list of fields which can or cannot be sent as-is we sanitize the raw data. Keeping a mapping of all obfuscated values, and once getting the response replacing again the obfuscated values with the sensitive fields for a complete and readable summary, without having any sensitive customer data ever leave our own cloud.
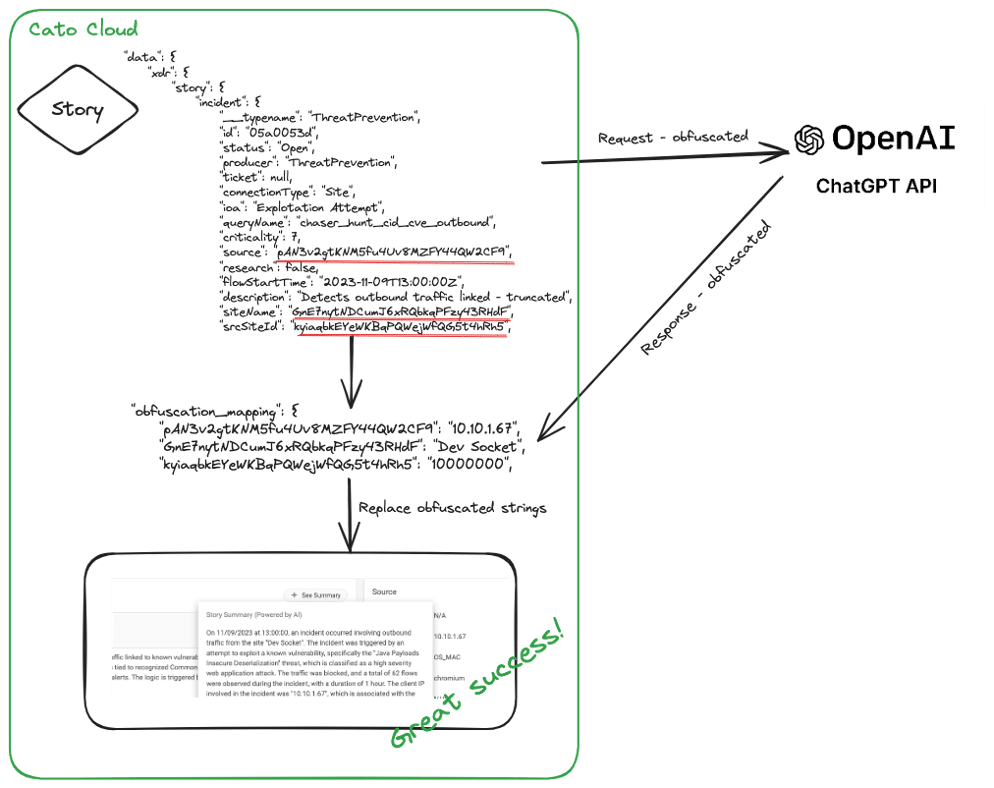
Figure 5 – High level flow of PII obfuscation
Rate limiting – like most cloud APIs, OpenAI is no different and applies various rate limits on requests to protect their own infrastructure from over-utilization. OpenAI specifically does this by assigning users a tier-based limit calculation based on their overall usage, this is an excellent practice overall and when designing a system that consumes such an API, certain aspects need to be taken into consideration:
- Code should be optimized (shouldn’t it always? 😉) so as not to “expend” the limited resources – number of requests per minute/day or request tokens.
- Measuring the rate and remaining tokens, with OpenAI this can be done by adding specific HTTP request headers (e.g., “x-ratelimit-remaining-tokens”) and looking at remaining limits in the response.
- Error handling in case a limit is reached, using backoff algorithms or simply retrying the request after a short period of time.
Part of something bigger
Much like the entire field of AI itself, the shaping and application of which we are now living through, the various applications in cybersecurity are still being researched and expanded on, and at Cato Networks we continue to invest heavily into AI & ML based technologies across our entire SASE platform.
Including and not limited to the integration of many Machine Learning models into our cloud, for inline and out-of-band protection and detection (we’ll cover this in upcoming blog posts) and of course features like XDR Storyteller detailed in this post which harnesses GenAI for a simplified and more thorough analysis of security incidents.
Related Articles



Cato CTRL™ Threat Research: PoC Attack Targeting Atlassian’s Model Context Protocol (MCP) Introduces New “Living Off AI” Risk