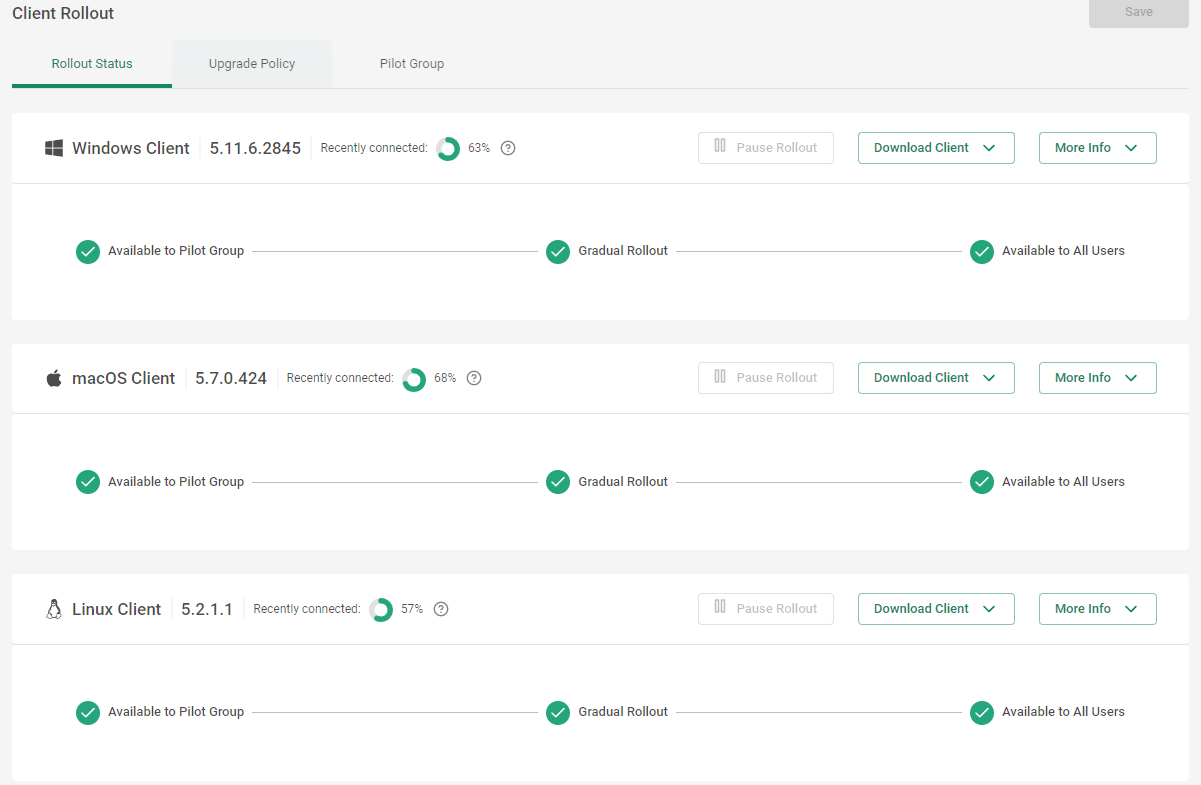
Vadim Freger
Vadim Freger, Director of Service Evangelism, Strategist, Cato Networks. Member of Cato Ctrl. Vadim serves as Cato's Director of Service Evangelism, where he is dedicated to advocating Cato's reputation as a leading SASE and cyber security company. With over seven years of experience at Cato, Vadim previously held the role of Director of DevOps and SRE, playing a pivotal role in shaping and advancing Cato's expansive global cloud services and operations.
Before joining Cato, Vadim held various management positions at Imperva, having over 15 years of combined experience in the fields of networking and cyber security.