
How Cato Uses Large Language Models to Improve Data Loss Prevention


Table of Contents
|
Listen to post:
Getting your Trinity Audio player ready...
|
Cato Networks has recently released a new data loss prevention (DLP) capability, enabling customers to detect and block documents being transferred over the network, based on sensitive categories, such as tax forms, financial transactions, patent filings, medical records, job applications, and more. Many modern DLP solutions rely heavily on pattern-based matching to detect sensitive information. However, they don’t enable full control over sensitive data loss. Take for example a legal document such as an NDA, it may contain certain patterns that a legacy DLP engine could detect, but what likely concerns the company’s DLP policy is the actual contents of the document and possible sensitive information contained in it.
Unfortunately, pattern-based methods fall short when trying to detect the document category. Many sensitive documents don’t have specific keywords or patterns that distinguish them from others, and therefore, require full-text analysis. In this case, the best approach is to apply data-driven methods and tools from the domain of natural language processing (NLP), specifically, large language models (LLM).
LLMs for Document Similarity
LLMs are artificial neural networks, that were trained on massive amounts of text, commonly crawled from the web, to model natural language. In recent years, we’ve seen far-reaching advancements in their application to our modern-day lives and business use cases. These applications include language translation, chatbots (e.g. ChatGPT), text summarization, and more.
In the context of document classification, we can use a specialized LLM to analyze large amounts of text and create a compact numeric representation that captures semantic relationships and contextual information, formally known as text embeddings. An example of a LLM suited for text embeddings is Sentence-Bert. Sentence-BERT uses the well-known transformer-encoder architecture of BERT, and fine-tunes it to detect sentence similarity using a technique called contrastive learning.
In contrastive learning, the objective of the model is to learn an embedding for the text such that similar sentences are close together in the embedding space, while dissimilar sentences are far apart. This task can be achieved during the learning phase using triplet loss.
In simpler terms, it involves sets of three samples:
- An “anchor” (A) – a reference item
- A “positive” (P) – a similar item to the anchor
- A “negative” (N) – a dissimilar item.
The goal is to train a model to minimize the distance between the anchor and positive samples while maximizing the distance between the anchor and negative samples.
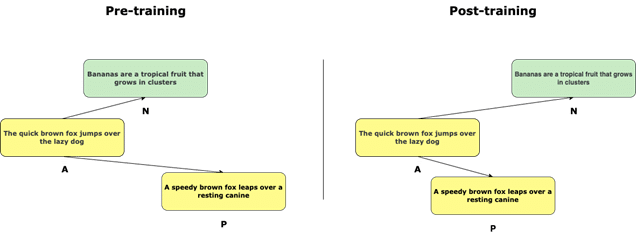
Contrastive Learning with triplet loss for sentence similarity.
To illustrate the usage of Sentence-BERT for creating text embeddings, let’s take an example with 3 IRS tax forms. An empty W-9 form, a filled W-9 form, and an empty 1040 form. Feeding the LLM with the extracted and tokenized text of the documents produces 3 vectors with n numeric values. n being the embedding size, depending on the LLM architecture. While each document contains unique and distinguishable text, their embeddings remain similar. More formally, the cosine similarity measured between each pair of embeddings is close to the maximum value.
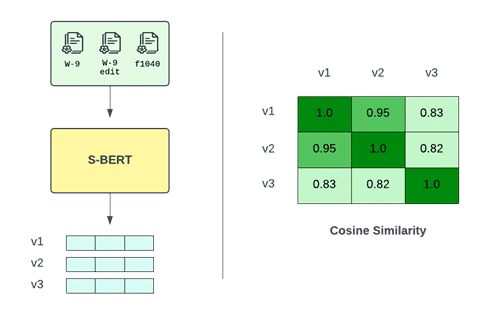
Creating text embeddings from tax documents using Sentence-BERT.
Now that we have a numeric representation of each document and a similarity metric to compare them, we can proceed to classify them. To do that, we will first require a set of several labeled documents per category, that we refer to as the “support set”. Then, for each new document sample, the class with the highest similarity from the support set will be inferred as the class label by our model.
There are several methods to measure the class with the highest similarity from a support set. In our case, we will apply a variation of the k-nearest neighbors algorithm that implements the classification based on the neighbors within a fixed radius.
In the illustration below, we see a new sample document, in the vector space given by the LLM’s text embedding. There are a total of 4 documents from the support set that are located in its neighborhood, defined by a radius R.
Formally, a text embedding y from the support set will be located in the neighborhood of a new sample document’s text embedding x , if
R ≥ 1 - similarity(x, y)
similarity being the cosine similarity function. Once all the neighbors are found, we can classify the new document based on the majority class.
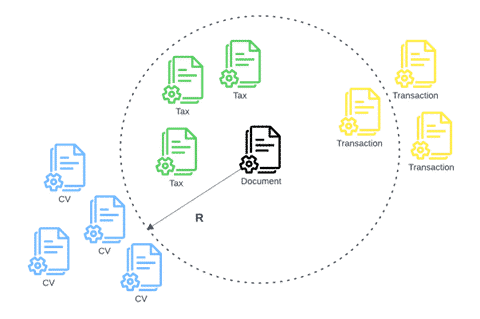
Classifying a new document as a tax form based on the support set documents in its neighborhood.
Protect Your Sensitive Data and Ensure Regulatory Compliance with Cato’s DLP | Get It NowCreating Advanced DLP Policies
Sensitive data is more than just personal information. ML solutions, specifically NLP and LLMs, can go beyond pattern-based matching, by analyzing large amounts of text to extract context and meaning. To create advanced data protection systems that are adaptable to the challenges of keeping all kinds of information safe, it’s crucial to incorporate this technology as well.
Cato’s newly released DLP enhancements which leverage our ML model include detection capabilities for a dozen different sensitive file categories, including financial, legal, HR, immigration, and medical documents. The new datatypes can be used alongside the previous custom regex and keyword-based datatypes, to create advanced and powerful DLP policies, as in the example below.
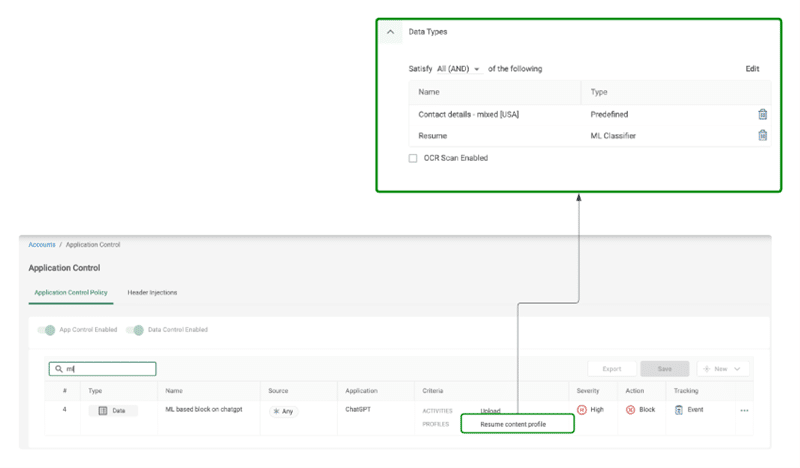
A DLP rule to prevent internal job applicant resumes with contact details from being uploaded to 3rd party AI assistants.
While we’ve explored LLMs for text analysis, the realm of document understanding remains a dynamic area of ongoing research. Recent advancements have seen the integration of large vision models (LVM), which not only aid in analyzing text but also help understand the spatial layout of documents, offering promising avenues for enhancing DLP engines even further.
For further reading on DLP and how Cato customers can use the new features:
Related Articles


Cato CTRL™ Threat Research: Analyzing LAMEHUG – First Known LLM-Powered Malware with Links to APT28 (Fancy Bear)


Highlights from the 2026 Cato CTRL™ Threat Report





