




Building a Resilient City: How Cato Rolls Out PoP Changes Safely



|
Listen to post:
Getting your Trinity Audio player ready...
|
Imagine a new city that promises cheap housing and ultra-modern infrastructure. People move in, only to discover that the roads are constantly jammed, power cuts happen every evening, water pressure drops without warning, and there are no cameras or sensors to detect where things are breaking. There is no central control room to test changes safely before the next “improvement” hits the streets. It does not matter how attractive the city looked on paper. With unreliable infrastructure and no easy way to maintain it, people will not stay.
Your global SASE deployment is that city. Users, sites and applications depend on it every day, and they feel every “pothole” instantly.
In our earlier blog, “Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations,” we explored how a single change in a global platform can ripple into a broad incident. In this blog, we go one level deeper and focus on operations. We look behind the scenes at how Cato rolls out changes to its PoPs: gradual, phased deployments instead of one-step upgrades across the entire cloud, pre-deployment staging, post-deployment verification,and deep monitoring that ties every phase to clear signals. The goal is simple: continuous innovation with built-in resiliency and controlled risk, so your traffic does not become the experiment.
Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations | Read the BlogWhy rollout strategy matters
Recent high profile outages at large cloud and edge providers have shown how dangerous a single, global change can be. A configuration update or new software build that goes everywhere at once can turn into a global incident in minutes, long before operators have time to react. In our analysis of the Cloudflare outage, we showed how a single configuration refresh, propagated globally and quickly, can undermine even a mature network when there are insufficient guardrails around rollout and monitoring.
This is exactly why Cato SASE uses gradual, phased rollouts with robust monitoring and verification at each step. Instead of pushing a new version to all PoPs in one shot, we introduce changes in phases and waves:
- Each phase is a mix of PoPs that includes different regions, for example, APAC, EMEA, Americas, Israel, and Japan.
- The rollout is spread across multiple weeks, not hours. The early phases are intentionally small and include all the main flavors of our services and infrastructure, serving as a safety net to help detect specific issues that might not be apparent in testing.
- Within a phase, we can split further into sub phases to avoid restarting too many PoPs at the same time.
We do not rebuild the whole “city” at once. We modernize district by district, with clear criteria to move forward or pause.
Governance before deployment
Change governance is the first layer of resiliency. New PoP software versions are produced regularly, but there is a clear separation between “a build exists” and “it can carry live traffic.”Every new branch or patch goes through:
- Version selection that includes both manual testing and automated validation before it is approved for production.
- A formal handoff to network operations.
- Internal approval in our change management systems is required before it can reach production PoPs.
- Real-time permission grant for the actual execution
When a patch is needed to address an issue seen in the field, we treat it with the same discipline. We may choose to redeploy early phases, or to move forward only in later phases, depending on risk and urgency. In all cases, there is an explicit approval step before a new revision is allowed into the rollout plan.
For customers, the important part is this: only vetted, approved versions are allowed to serve your traffic.
Staging before activation
Once a version is approved, it still does not go directly into a restart. We separate the deployment into two main steps.
- Staging (warm up): The new software is delivered to the target PoPs over management channels ahead of time.
- No user impact.
- No restarts.
- Can be done outside maintenance windows.
By the time we reach the deployment window, PoPs already have the new bits locally. This shortens the actual maintenance activity and reduces risk.
- Deployment in maintenance windows: The actual rollout for a phase is executed during planned maintenance windows. This step restarts the relevant PoP services and re establishes tunnels.
- Can run per phase or per sub phase, to control how many PoPs update at once.
- Includes a controlled failover so that the new version is exercised as the active one and the previous version remains as the backup.
This separation between “delivery” and “activation” is a key resiliency pattern. It gives us much more control over when users feel a change, and how many PoPs are affected at any given moment. In Figure 1, we show an example of a high-level view of a deployment phase that lists all PoPs in that phase, each colored by the software revision they are currently running. Cato’s Network Operators can instantly see whether all PoPs reached the target version, whether any PoP is still on an older revision, and whether any PoP failed to report back after the deployment.
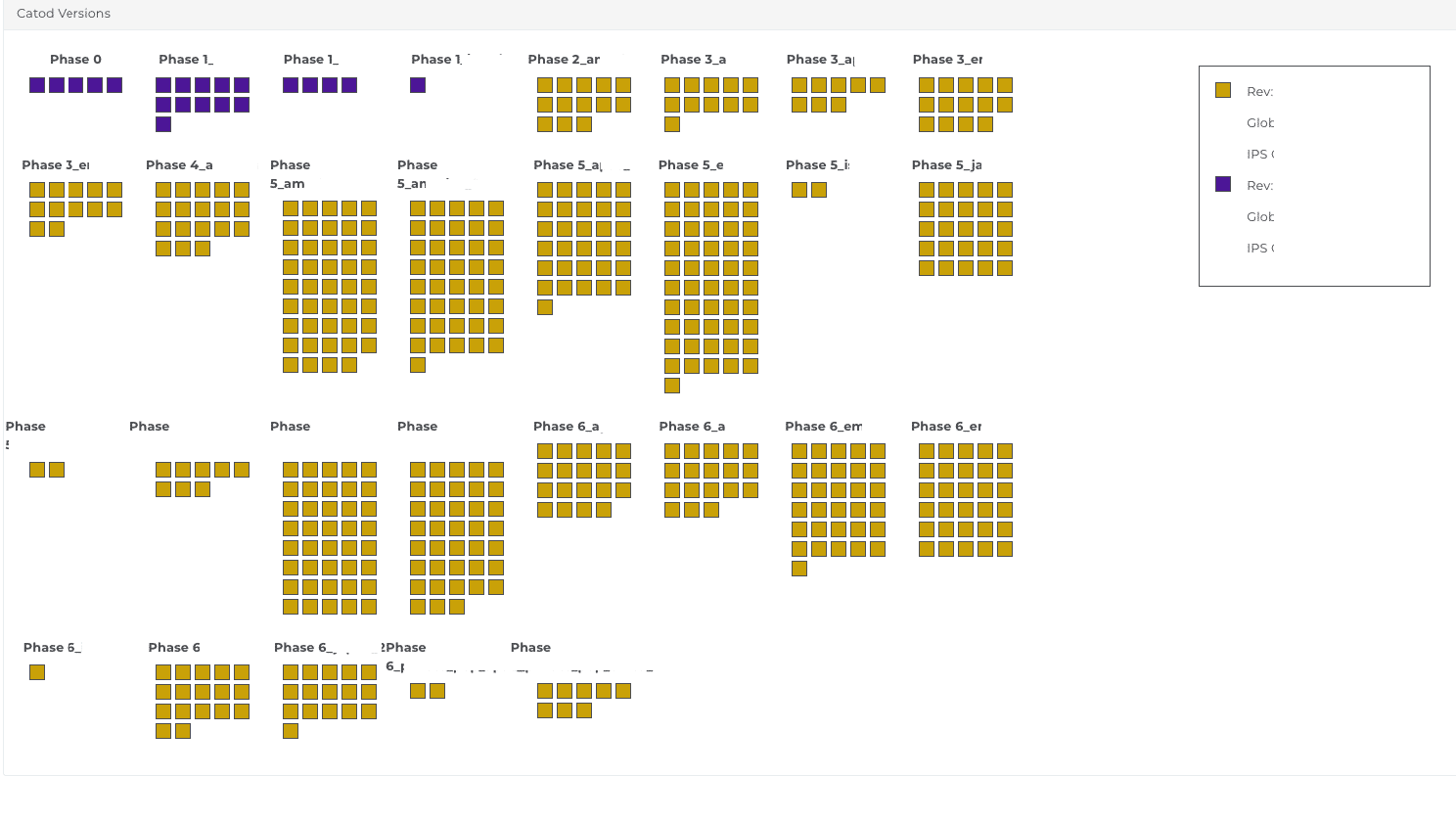
Figure 1. Example of phased rollout verification view
Treating each phase as a small experiment
Every phase is treated as a small, controlled experiment with a clear before and after.
Before deployment for a phase or sub-phase, we:
- Capture the current number of PoPs in the phase.
- Check existing service statuses and alerts for those PoPs.
- Identify any PoPs that are already in maintenance for other changes, and decide whether to skip them temporarily.
This snapshot becomes our reference point.
After deployment, we verify that:
- All targeted PoPs are running the desired software revision.
- The number of PoPs in the phase has not decreased, which would indicate a PoP that failed to come back correctly.
- No new service issues appeared that were not present in the pre deployment snapshot.
To support this, we rely on both dashboards and targeted alerting.
In figure 2 we show our PoP health and post deployment monitoring dashboard. A snapshot of the PoP monitoring dashboard highlighting key health indicators such as uptime, tunnel stability, latency and service statuses. This view helps Cato’s NOC validate the health of a phase after deployment and quickly identify any PoP that behaves differently from the rest of its group.
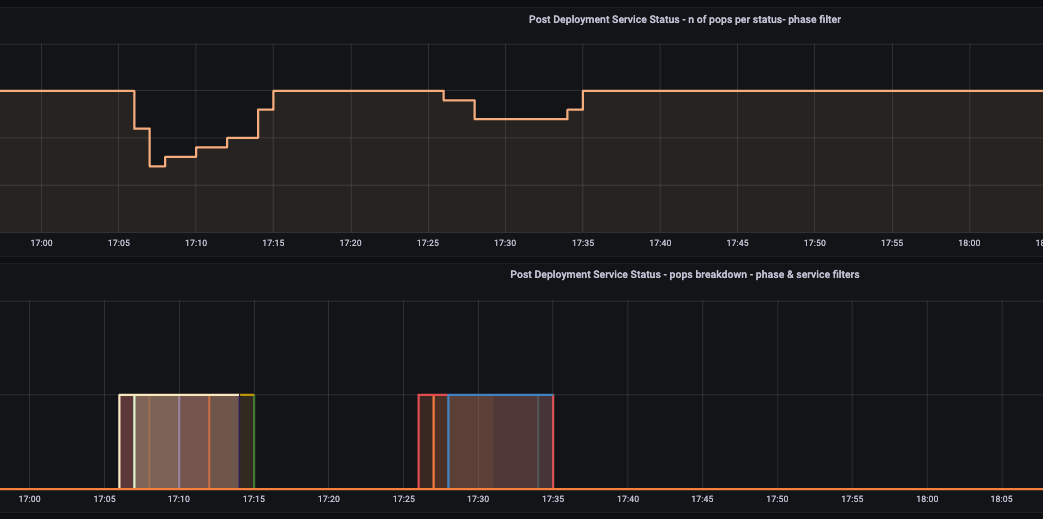
Figure 2. PoP health and monitoring dashboard
Humans can miss things, especially when changes are frequent. To reduce that risk, dedicated monitoring that specifically examines the time window immediately following a deployment. If a new service status or anomaly appears on a PoP shortly after a phased update, an alert is triggered and tied to that deployment context. This makes it easier to answer the critical question: “Did the new code introduce this, or was it already there?” If there is any doubt, the next phases can be paused while the team investigates.
Built-in resiliency tools
Gradual rollout and monitoring are only part of the story. Resiliency also depends on what you can do when something does go wrong.
Here are some of the mechanisms we use behind the scenes:
- Standby upgrade for fault scenarios: In some cases, we can pre-position an alternative, validated revision on PoPs without activating it. If a PoP encounters a predicted fault condition or a soft lockup issue, it can automatically switch to that standby revision. If no such issue occurs before the next regular deployment, the standby package is simply cleared. This provides another tool to protect stability in dynamic situations.
- Quick mitigation and rollback options: If a single PoP behaves oddly compared to others in the same location, operators can perform a focused service restart on that PoP to restore normal behavior while root cause is investigated. For more severe issues or if a new revision causes repeated failures, we can roll back a PoP to a previously known good snapshot that includes both software and critical configuration. Hard fault issues that cause availability problems on a machine are also monitored and automatically handled, with escalation to engineering when necessary.
The goal is not to pretend that software will never have faults. The goal is to have clear, proven ways to contain issues, recover quickly, and keep the rest of the network safe.
Aligned with security and compliance frameworks
Although this blog focuses on resiliency and customer experience, the same practices are also expected by modern security and compliance frameworks for operators of critical infrastructure.
- PCI DSS: The way we approve versions before production, use controlled maintenance windows, and validate behavior after each phase is consistent with PCI DSS expectations around documented change control, testing changes before they go live, and continuous monitoring of in-scope systems. In our dedicated blog about achieving PCI DSS v4.0.1 certification, we describe the control framework behind Cato SASE in detail. The gradual rollout and monitoring practices in this post are the operational side of that story. They are part of how we turn written requirements about change management and monitoring into day-to-day behavior in our PoPs.
- SOC 2 (Security and Availability): SOC 2 emphasizes formal change management, separation of duties, and ongoing monitoring to protect service availability. Our staging, phased rollout, and post-deployment monitoring reflect exactly this type of operational discipline behind a cloud service.
- ISO/IEC 27001: ISO 27001 requires that changes to information systems are managed in a controlled way and that systems are monitored for anomalies. The multi-step process described here, from approvals and phased rollout to verification and rollback, is how Cato implements these principles in a global SASE cloud.
- NIST style best practices: NIST guidance around secure operations and configuration management stresses minimizing blast radius, maintaining rollback options, and observing systems closely after changes. Our gradual, monitored, and reversible deployment strategy is designed with that mindset.
For customers, this means that the operational practices behind Cato SASE are not only about comfort and uptime. They follow patterns that auditors and security teams already recognize as good practice.
What this means for you
Putting it all together, here is what you gain from this approach:
- Reduced blast radius: No single change is introduced everywhere at once. Phases and sub-phases limit the impact of any unexpected issue.
- Predictable change windows: Deployments occur during planned maintenance windows, with staging completed ahead of time to minimize the duration of those windows.
- Deep operational visibility: Dashboards and focused alerts make it clear what happened before, during and after each deployment phase.
- Fast, controlled recovery options: Patch deployments, standby upgrades, service restarts and rollbacks provide multiple ways to restore stability if needed.
- Continuous innovation without constant risk: Cato can keep improving the platform while keeping your SASE environment stable, observable and aligned with modern regulatory expectations.
In other words, the “city” behind your SASE platform is not just growing fast. It is planned, instrumented, and monitored so that when we build a new road, your traffic keeps moving.
Related Articles
SASE as a Journey: Why Single-Vendor Doesn’t Mean Single Project

Say Goodbye to SaaS Security Gaps with Cato CASB

The Partner Advantage: Turn Customer M&A Chaos Into Opportunity

