Una mirada al interior del nuevo asistente de IA de Cato


En línea con nuestra filosofía de ofrecer una experiencia excepcional al cliente, Cato Networks ha añadido un asistente de IA basado en una base de conocimientos como parte de la Cato SASE Cloud Platform. El asistente de IA proporciona respuestas precisas y relevantes a preguntas sobre el uso de las numerosas funciones de Cato, con instrucciones detalladas paso a paso que se adaptan de forma única a la situación y las circunstancias del usuario.
Este es solo el último ejemplo de nuestro trabajo en IA aquí en Cato. Recientemente anunciamos nuestro uso de Amazon Bedrock como base de nuestras funcionalidades de IA generativa (GenAI). Amazon Bedrock impulsa nuestro asistente de IA y también la búsqueda en lenguaje natural (NLS, por sus siglas en inglés), que permite convertir entradas de texto libre en filtros de búsqueda técnicos en nuestra plataforma SASE. La página de IA y ML de Cato proporciona ejemplos adicionales de cómo utilizamos tecnologías de IA/ML, como para inteligencia de amenazas, prevención de amenazas y clasificación de clientes, dispositivos y aplicaciones.
¿Por qué un asistente de IA con recuperación de la información?
Cato ha ofrecido durante mucho tiempo funcionalidades de búsqueda robustas dentro de su base de conocimientos (KB), pero para hacer que la recuperación de información sea más eficiente, integramos un modelo de lenguaje grande (LLM) de última generación con búsqueda dirigida. Esto permite a los usuarios obtener respuestas precisas y contextualizadas sin tener que leer artículos completos. La meta es mostrar la información adecuada en el momento adecuado con el mínimo esfuerzo. En lugar de recibir docenas de artículos de 2000 palabras para revisar, los usuarios reciben una breve lista con viñetas que responde a sus preguntas. Los resultados también son mejores, ya que podemos utilizar todo el contexto del historial de chat, en lugar de una sola consulta. Por último, toda la experiencia es más rápida e intuitiva que buscar en una base de conocimientos.

El asistente de IA: Cómo funciona
A alto nivel, el asistente de IA comienza con dos entradas: la solicitud del usuario en un chat y el historial del chat. El resultado es la respuesta del asistente de IA y las fuentes que ha utilizado para darla. En su interior, el canal consta de tres componentes principales:
- Un sistema de protección que protege al asistente de IA contra avisos maliciosos de usuarios y evita el tratamiento de información sensible y personalmente identificable (PII).
- Un sistema de búsqueda de contexto que recupera contexto textual con el fin de responder a la solicitud del usuario a partir de una base de datos de contexto preparada con antelación.
- Un LLM, el cerebro del asistente de IA, que procesa el aviso del usuario, el historial de chat y el contexto proporcionado.
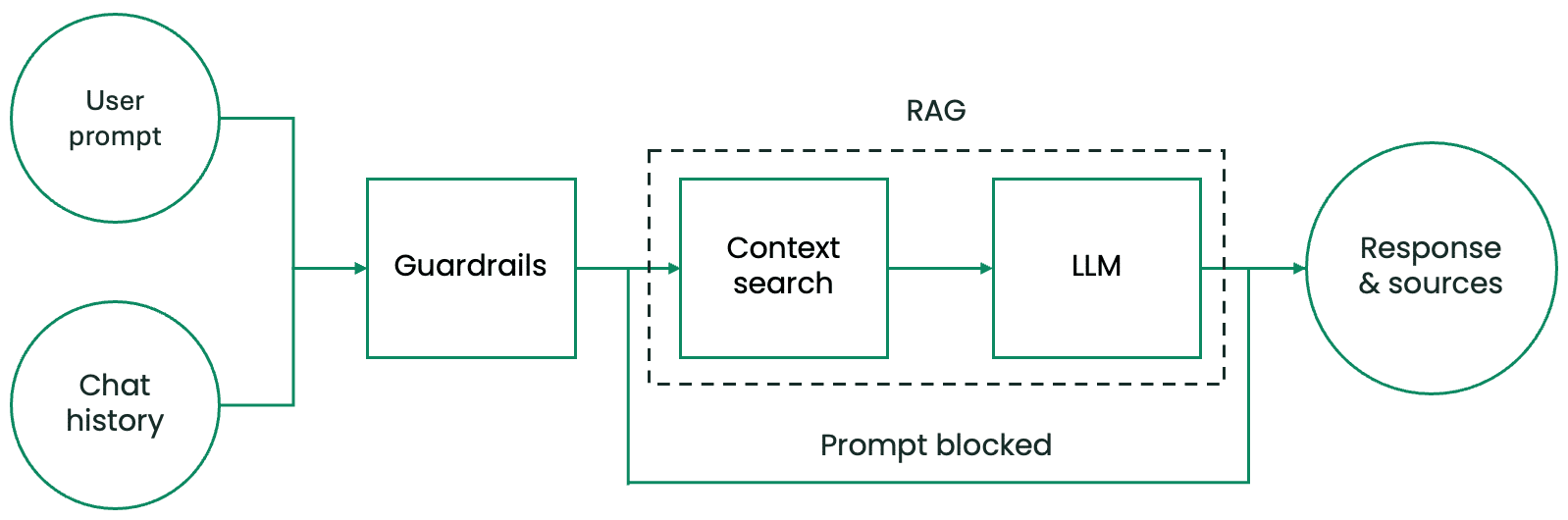
Figura 1. Componentes del canal del asistente de IA
Parte del poder del asistente de IA es su capacidad para recuperar recursos que pueden estar relacionados con la consulta de un usuario, pero que no contienen las palabras clave exactas. En lugar de una base de datos de palabras clave, nuestra base de datos contextual contiene el significado semántico del texto de la base de conocimientos. Aunque las palabras no coincidan perfectamente, pueden recuperarse como parte de la respuesta a la consulta. Y dado que, como veremos, Cato no está indexando texto, el asistente de IA es inherentemente multilingüe, permitiendo a cualquier usuario formular consultas en casi cualquier idioma.
Periódicamente, extraemos informacion de nuestra base de conocimientos, dividiendo los artículos en fragmentos muy detallados y almacenando el significado semántico de esos fragmentos de texto en una base de datos Amazon OpenSearch como vectores numéricos llamados «incrustaciones». Representar fragmentos de texto más pequeños nos permite ser más precisos a la hora de representarlos como incrustaciones y determinar su similitud con otros conceptos. Cada fragmento incrustado se almacena con metadatos sobre la fuente original y su texto (véase la figura 2). A continuación, se pueden definir incrustaciones similares mediante la distancia entre ellas utilizando diversas métricas, como la métrica de similitud del coseno (el coseno del ángulo entre los vectores).
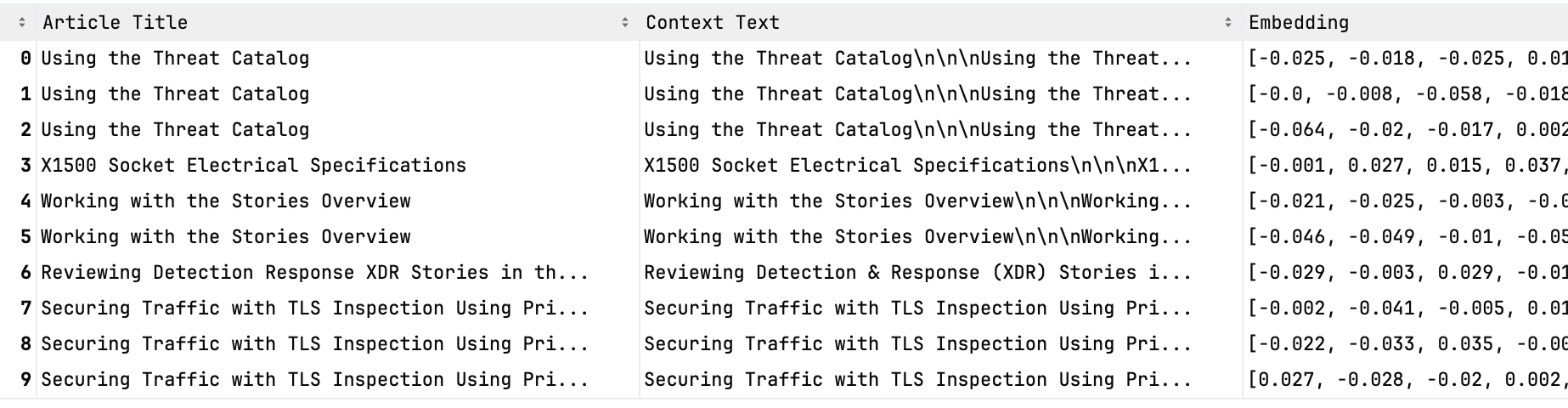
Figura 2. Ejemplo de cómo se representa el texto en nuestra base de datos de contexto
La generación aumentada por recuperación (RAG) mejora la respuesta del asistente de IA. Los LLM tradicionales generan respuestas basándose únicamente en sus datos de entrenamiento, que permanecen estáticos una vez que el modelo ha sido entrenado. Sin aportaciones externas, dependen de los conocimientos preexistentes, lo que limita la precisión y la relevancia en campos que cambian rápidamente.
RAG mejora este proceso al incorporar un componente dinámico de recuperación de información. Cuando un usuario envía una consulta, buscamos en la base de datos de contexto y recuperamos los textos más semánticamente similares para responder al aviso. A continuación, elevamos la consulta con texto relevante de la base de conocimientos. Por último, la consulta elevada se envía a un modelo generativo, que ahora dispone de fuentes en las que basar su respuesta.
Por ejemplo, considere la pregunta: «¿Cómo configuro una regla de red para bloquear el tráfico saliente hacia OpenAI?». Una búsqueda por palabra clave arrojaría 516 artículos de la base de conocimientos, siendo el primero de ellos de más de 2000 palabras. En su lugar, nuestro enfoque ofrece una breve lista con viñetas que detalla los pasos a seguir en menos de 200 palabras (véase la demostración).
Con nuestro enfoque (véase la figura 3), el sistema RAG devuelve varias incrustaciones (en azul) cuyo significado es el más cercano a la consulta (en rojo). Esas incrustaciones corresponden a tres artículos: Configuración de reglas de la red (superior izquierda), Seguridad del tráfico de aplicaciones de IA (inferior), y Políticas de cortafuegos de Internet y WAN: mejores prácticas (superior derecha).

Figura 3. Incrustaciones bidimensionales de fragmentos de artículos de la base de conocimientos y la consulta del usuario.
Conclusión
El asistente de IA ahorra a los usuarios una gran cantidad de tiempo a la hora de encontrar información relevante en la amplia base de conocimientos de Cato. El canal toma como entrada el mensaje del usuario y el historial de chat. Genera una respuesta junto con fuentes relevantes, basándose en un sistema de barreras de seguridad, un sistema de búsqueda contextual para recuperar conocimientos relevantes y un LLM para generar respuestas. El sistema utiliza RAG, donde las indicaciones de los usuarios se incorporan a representaciones vectoriales, se buscan en una base de datos contextual de fragmentos de conocimiento preprocesados y se combinan con las fuentes recuperadas para generar respuestas fundamentadas.