




When Sensitive Data Becomes a Picture: Introducing ML-Powered Image Classification for DLP




|
Listen to post:
Getting your Trinity Audio player ready...
|
Dr. Carter finishes a long shift at the hospital, exports a patient X-ray as a regular image file, and drags it into an AI assistant to double-check a diagnosis. The image included the patient’s name and ID. Across town, Jason, a travel agent, scans a stack of passports and uploads the images to an AI tool to automatically fill bookings. In a support center, Sarah snaps a quick photo of a credit card and sends it to an AI service to avoid retyping the number. None of them thought they were causing a data breach. They were just trying to get work done faster, while quietly leaking protected health information (PHI), payment data, and identity documents to external AI tools that sit completely outside their organizations’ control. These characters are fictional, but the situations are already part of everyday life in the era of AI-driven workflows and “helpful” assistants for routine processes.
To close this gap, we recently introduced ML-powered image classification as part of Cato DLP. The Cato platform can detect sensitive visual content such as medical scans, credit cards, and passport images and, based on policy, block these images from being uploaded to AI apps and other cloud services, not just inspect sensitive text. To show what this looks like in practice, we include a demo video that shows how we block the upload of a medical scan to ChatGPT in real time, helping prevent a potential HIPAA violation before it happens, in the same way we help avoid violations of other regulations such as GDPR and PCI DSS.
Why OCR-Only DLP Isn’t Enough
Traditional DLP tries to handle images by using Optical Character Recognition (OCR) to extract readable text and then examining that text with pattern-based detectors and ML/NLP-based DLP engines for content resembling credit card numbers, IDs, or PHI.
That fails in two main ways:
- Unreliable OCR: Blurry photos, low contrast, odd angles, handwriting, and visual overlays often lead to partial or broken text extraction. When the text is not extracted correctly, the DLP engine does not detect a match and no alert is generated.
- Non-textual sensitive content: Medical scans, network diagrams, whiteboard photos, and many forms of intellectual property (IP) don’t rely on text. As such, OCR can never identify these items in an image.
The result: false negatives and a big blind spot around image-based data leaks.
Transformer Models: The Engine Behind Cato’s Image DLP
At the core of our new image, DLP capabilities are transformer-based vision–language models. Instead of asking “What text can I OCR from this screenshot?” we use models that learn to understand what an image is about.
We build on a CLIP-style multimodal model, originally introduced by OpenAI in CLIP. CLIP or Contrastive Language–Image Pre-training is trained on hundreds of millions of image–text pairs and learns to connect pictures with natural language concepts. Rather than relying on pixel patterns or hard-coded rules, CLIP learns high-level ideas like “MRI scan,” “passport photo,” or “credit card on a table.”
Technically, CLIP uses two encoders:
- An image encoder that converts an image into a vector (an embedding)
- A text encoder that converts a short phrase (e.g., “government ID card”, “MRI scan”) into a vector in the same space
Because both encoders produce embeddings in a shared latent space, we can measure how well an image matches a description simply by comparing their vectors. If the embeddings are close, the image likely represents that concept as illustrated in Figure 1.
Inside Cato’s Image Classifier
On top of this CLIP embedding space, we built an image classifier that is tuned specifically for DLP and regulated data.
We start with a curated support set of sensitive categories that matter to our customers, such as:
- Medical imagery (MRI, CT, X-ray)
- Payment cards
- Passports, national IDs, and employee badges
- Architecture diagrams and whiteboard sketches
Each category is represented by:
- Several example images
- A short text description
When a new image is inspected, our pipeline:
- Generates an image embedding for the visual content using the image encoder.
- Compares it to both the image embeddings and text embeddings from the support set.
- Uses cosine similarity to evaluate how close the new image is to each sensitive category.
To turn similarity into a decision, we apply a variation of k-nearest neighbors with a fixed radius (also known as a fixed-radius near neighbors approach). In practice, that means we only consider neighbors that are “close enough” in the embedding space, and we classify the image as sensitive only if there is strong local agreement around a specific category.
This fixed-radius approach helps us avoid noisy matches and overconfident guesses, giving us a robust Image ML classifier that can reliably recognize sensitive content even when OCR fails or when there is no text at all as illustrated in Figure 1.
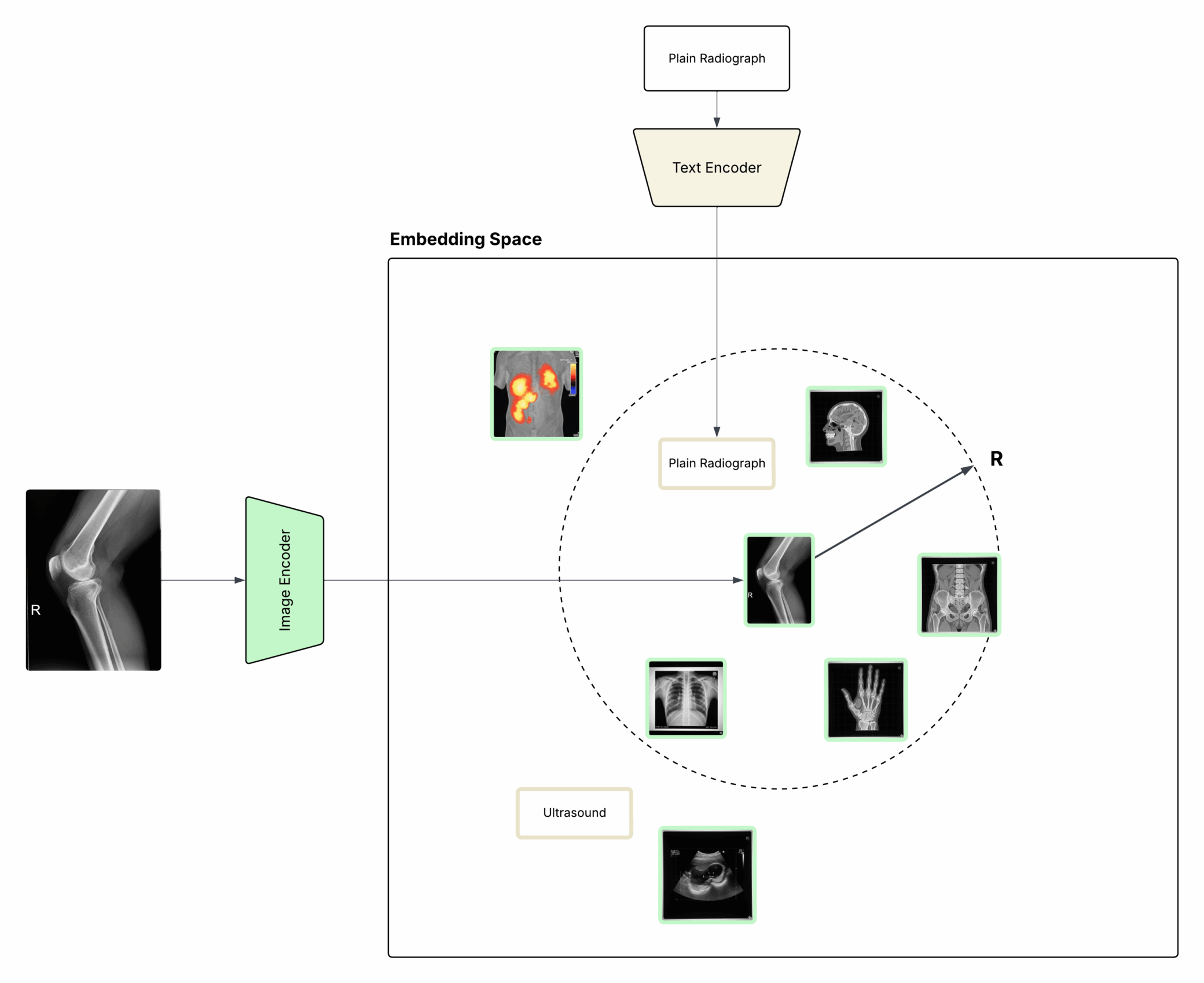
Figure 1. Images and text are embedded into the same space to enable semantic matching
Turning ML Detection Into Enforceable Policy
As shown in Figure 2, a user can easily upload a patient X-ray image to an AI app for analysis, unintentionally sending PHI to a third-party service that is outside the organization’s control.
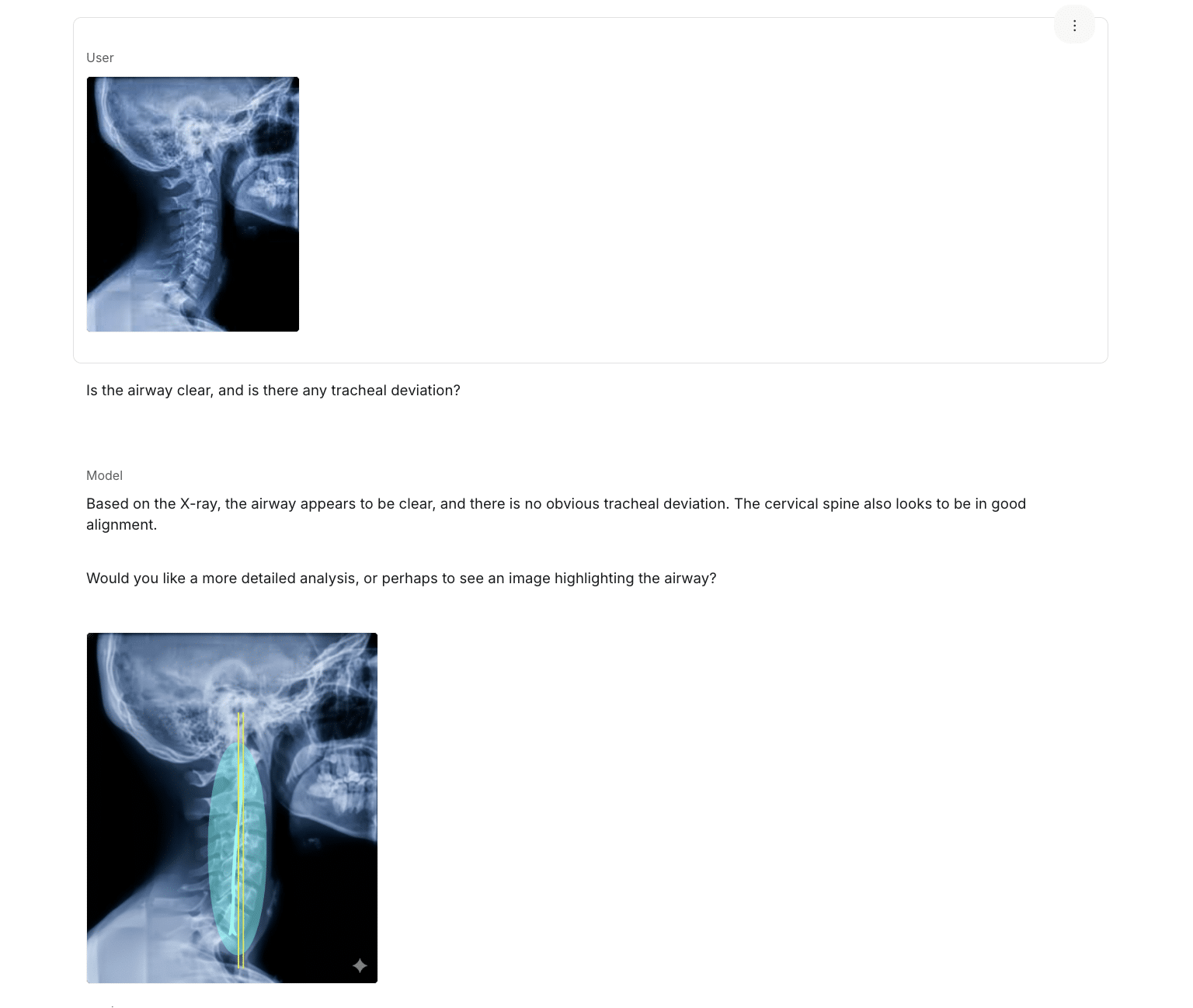
Figure 2. Uploading a patient X-ray image to an AI app for analysis.
Because our Image ML classifier is embedded into the Cato SASE platform, we can turn this kind of detection into network-level policy instead of just an alert. In Figure 3, an admin configures Image ML classifiers for medical imagery such as MRI, CT, and X-ray scans and groups them into a reusable data profile.
ֿFor example, an admin can:
- Create a data profile for medical scans (MRI/CT/X-ray) using the Image ML classifiers (Figure 3).
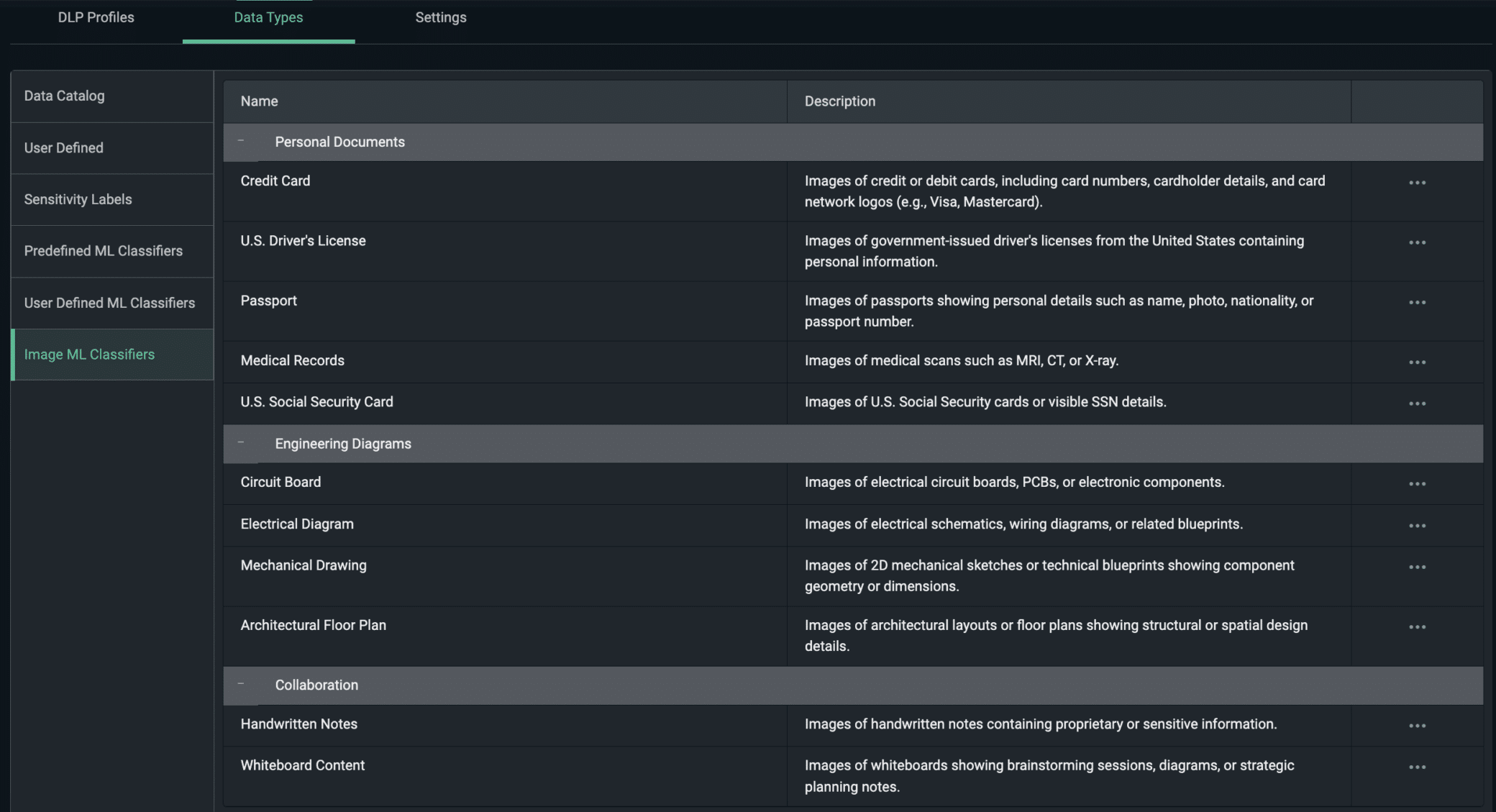
Figure 3. Configuring Image ML classifiers for medical scans in the Cato management console
2. Attach that profile to a DLP rule, such as “Block uploads of medical images to AI conversational apps” (Figure 4).

Figure 3. Defining a DLP policy that blocks medical images from being uploaded to ChatGPT.
3. Apply the rule to destinations like ChatGPT and other AI tools.
In the demo videos below, we show this enforcement in action. In the first video, a radiologist tries to attach a patient X-ray to an email to send it outside the organization. The image is identified as a medical scan, the attachment is blocked in real time, and the event is logged in the Cato Management Application (CMA), helping to prevent a potential HIPAA incident. In the second video, an engineer attempts to email a sensitive architecture diagram, and Cato classifies the image and blocks the attachment in the same way, with the corresponding security events recorded in CMA.
The same mechanism can be applied to other regulated content such as payment cards, passports, and ID documents by assigning the relevant Image ML categories to dedicated DLP profiles. With these profiles in place, organizations can also prevent users from uploading sensitive images to ChatGPT or other AI applications.
Beyond HIPAA: PCI, GDPR, and Identity Documents
The image blind spot isn’t just a healthcare problem. The same ML engine that detects PHI in scans can also protect:
- Payment cards: Support PCI DSS by detecting credit card images and blocking uploads to AI tools or unsanctioned SaaS, even if card numbers aren’t perfectly OCR-readable.
- Passports and IDs: Support GDPR and other privacy regulations by preventing uncontrolled uploads of passports, driver’s licenses, and ID badges to third-party AI services or cloud apps.
Example policies:
- “Block uploads of images that look like payment cards to AI assistants and personal cloud storage.”
- “Alert when passport or ID images are sent to apps outside our approved KYC stack.”
This turns image classification into a horizontal control spanning HIPAA, PCI, GDPR, and broader data protection frameworks.
Wrapping Up: DLP for the Way People Work Now
Modern work is increasingly visual: screenshots, scans, phone photos, whiteboard captures, and diagrams. If your DLP only understands text, it will miss a growing portion of your real risk, especially as employees experiment with AI tools that accept images.
Cato’s ML-powered image classification for DLP:
- Understands what’s in the image, not just what can be OCR’d
- Detects medical scans, payment cards, and identity documents
- Enforces policy at the network level, including for AI apps
- Helps organizations support HIPAA, PCI DSS, GDPR, and internal AI governance policies
This is how you close the image blind spot and bring visual data into the same protection model you already expect for documents, emails, and chat.
Related Articles
Spain and Portugal Power Outages: Real-Time Observations and Service Continuity Through Cato SASE Cloud Platform

A Leader Once Again: Cato Networks Recognized in 2025 Gartner® Magic Quadrant™ for SASE Platforms


When the Cloud Goes Dark: Why Owning Your Infrastructure Matters for Critical Services

