
Code Review That Learns: Inside Cato R&D’s Self-Evolving PR Review Agent



Table of Contents
- 1. TL;DR
- 2. Why pull request review fits agentic AI
- 3. What we built
- 4. Measuring impact using incident-linked pull requests
- 5. Review Workflow
- 6. Reply Workflow
- 7. Reducing noise using a two-output strategy
- 8. Spec-Driven Development
- 9. Making the system self-evolving
- 10. ROI and why building in-house can be compelling
- 11. PR metadata as a source of truth
- 12. Developer experience and feedback loop
- 13. Continuing to evolve
|
Listen to post:
Getting your Trinity Audio player ready...
|
TL;DR
Agentic AI promises to improve work processes in all domains and industries. R&D is no different. Recently, Cato R&D built an internal self-evolving pull request (PR) review agent that keeps reviewers in flow by commenting only on high-impact, high-confidence issues, validating every change against its spec from the PR and Jira, and learning continuously from developer feedback through long-term, episodic memory. What were the results? In an incident-linked evaluation, the PR review agent flagged 43% of incident-causing PRs. At scale, the agent surfaces about 7,000 high and critical issues each month, with 70 percent approved and resolved by engineers, while driving tooling costs down to about $10 per unique user. The key financial win is predictability and margin removal: By running the workflow in-house, we keep usage measurable and controlled and avoid the extra markup that commercial vendors add on top of underlying model usage. The big outcome was this: An always-on quality gate that gets smarter over time, reducing risk while saving engineering time, and the yearly cost is something you can forecast, not something you learn after it’s already spent.
Why pull request review fits agentic AI
Pull request review has characteristics that align well with an agentic approach:
- The same high-impact issues recur across repositories and services, including validation gaps, boundary handling, authorization assumptions, error paths, concurrency hazards, and backward compatibility.
- Small changes can have large downstream consequences, especially when they affect business flows and system interactions rather than isolated code blocks.
- Review quality depends heavily on context, including repository conventions, architectural patterns, ownership norms, and risk.
Most review assistants fail for a simple reason: they produce too much low-value output. When developers experience repeated noise, they stop paying attention. Our design goal was to keep feedback high-signal and reduce unnecessary interruptions. Practically, the agent comments only when it has high confidence in a high-impact issue, keeping false positives low and trust high.
What we built
We built and deployed an agent that comments on pull requests as code review bot It generates two forms of output, each serving a distinct purpose.
How the agent reviews a pull request
To keep feedback relevant, the agent does more than read a raw diff. It enriches the review context with structural signals, including Abstract Syntax Tree (AST)-based representations, so it can reason about code intent and change impact more reliably.
For larger changes, the diff is split into semantically related chunks using vector similarity and routed to multiple sub-agents. This improves coverage while keeping each sub-agent focused on a coherent part of the change.
In our internal benchmarks, we found that precision improves significantly with a two-stage approach: one model pass is tuned to surface more candidate findings, and a separate critic step filters out weak signals and false positives so only the most important, high-confidence issues become inline comments.
Code review summary
The agent posts an optional summary that helps reviewers quickly understand the change and its potential impact. It typically includes:
- A short, plain-language description of what changed
- The primary components involved
- Affected business flows and integration points
Inline findings
Inline comments are reserved for issues that meet strict criteria:
- High impact, such as production stability risk or security exposure
- High confidence, to reduce false positives and avoid distracting reviewers
This separation is intentional. The summary provides context without disruption. Inline comments are used only when the agent has strong reason to believe there is a meaningful issue. This is the core “trust contract”: summaries help you go faster, inline findings are rare and high-signal.
We built the agent on Claude Code using the latest Claude Sonnet 4.6 release, selected for strong code reasoning capability with practical operational cost for continuous PR review. Implementation-wise, the system is built around the Claude Agent SDK (the SDK for Claude Code), AWS Bedrock AgentCore for agent orchestration and long-term memory, and MongoDB for PR metadata and analytics.
To support review across our stack, the agent includes:
- 25 file-type-aware review skills that are auto-discovered from the files changed in each PR
- Security-aware guidance with severity levels and mappings to CWE and OWASP
- A dedicated judgment step for third-party library changes
- Business-flow-aware analysis for complex PRs
Measuring impact using incident-linked pull requests
We evaluated the system using pull requests that later led to production incidents. For each of these PRs, we checked one simple thing: would the agent have pointed out the problem during code review, before it reached production?
While writing this post, the current catch rate was 43%. We built the evaluation set by taking dozens of merged PRs that resulted in production incidents across varying severities, then measuring whether the agent would have raised a relevant risk signal during review.
This does not mean the agent “prevents 43% of incidents,” because incidents can involve factors beyond the PR itself. It does mean the agent is aligned with real-world failure patterns and can meaningfully improve the odds of catching high-impact issues during review. We treat this number as a baseline, and aim to raise it over time without sacrificing signal-to-noise.
Review Workflow
Our code review agent automatically analyzes pull requests the moment they’re created or updated. It starts by gathering context, pulling in the code changes along with any linked Jira tickets to understand what the developer is trying to accomplish.
The agent then performs a deep analysis using Claude, applying language-specific review patterns that understand the nuances of each programming language. To keep the signal-to-noise ratio high, it filters findings based on severity and confidence levels, ensuring developers only see issues that truly matter.
Finally, it posts structured review comments directly on the PR. But here’s the clever part: the entire analysis session is saved to S3, creating a foundation for intelligent follow-up conversations.

Figure 1. PR Agent Review workflow
Reply Workflow
When developers reply to review comments, the magic of session continuity kicks in. The agent doesn’t start from scratch-it restores the complete context from the original review, understanding exactly what it analyzed and why it flagged each issue.
This enables natural, contextual conversations. If a developer points out a false positive, the agent learns from it, saving that pattern to avoid similar mistakes in the future. It can mark issues as resolved when developers confirm fixes, and maintains a complete conversation history for audit trails and continuous improvement.

Figure 2. PR Agent Reply Workflow
Reducing noise using a two-output strategy
Summary output supports reviewer understanding
The summary is designed to accelerate human review by reconstructing intent and mapping impact. It helps reviewers understand what changed before reading the full diff.
Inline findings protect attention and trust
Inline findings are treated as interruptions. They appear only when the agent detects an issue that is both high impact and high confidence. This design keeps the signal-to-noise ratio high and helps prevent the tool from becoming background clutter. In other words: we optimized for the issues you’d actually want to block before production, not style, not bikeshedding, not “maybe” warnings.
Spec-Driven Development
One of the highest-leverage upgrades we made was moving from “diff-only review” to Spec-Driven Development (SDD).
Instead of treating a PR as just code changes, we gather the spec of the change, starting from the PR description and augmenting it with sources like Jira or internal references. Then we review the implementation against that intent.
This is how the agent catches high-severity logic mismatches that look perfectly “reasonable” in isolation, such as logic inversions, missing edge-case requirements, or changes that violate a business flow contract.
In practice, SDD makes the review less about reading code and more about verifying behavior by asking: “Does the implementation fully match the spec?”
Making the system self-evolving
Many PR review assistants are static. They only improve when someone manually updates prompts, rules, or configuration. We designed our PR review agent to improve through usage by capturing developer feedback and turning it into reusable knowledge.
A big reason “static” assistants struggle is memory. Modern coding agents operate under a limited working context, so they can lose important details over long interactions, repeat the same false positives, or drift when repository conventions differ from what the model expects. Recent Research on self-evolving agents highlights memory as a core component that can be optimized at inference time by deciding what to keep, what to retrieve, and what to discard, rather than retraining the model for every new lesson.
This problem is amplified at Cato’s scale. We’re a large platform with components in multiple programming languages, complex dependencies, and cross-repository business flows. A single PR’s diff, and sometimes even its repository, may not contain enough context to fully validate intent. As a result, a basic assistant may miss key risk signals or generate false positives.
Feedback-driven long-term memory
We treat memory as two layers:
- Short-term memory is the working context of the current PR review. It includes the diff, the immediate discussion, and the reasoning needed to complete this review. It is transient by design.
- Long-term memory persists across PRs. It stores durable knowledge such as repo-specific conventions, known exceptions, and lessons learned from prior reviews, so the agent stays consistent over time.
To make long-term memory useful, it has to be retrievable at the right time. Many agent systems do this by retrieving relevant stored knowledge and injecting it back into the model’s input during the next task, so the agent can apply past lessons when reviewing new code.
In our implementation, we added a handler for developer replies to inline findings. When a developer explains that a finding is incorrect or provides missing context (Figure 4), the agent can:
- Acknowledge the correction
- Extract the durable lesson as a reusable guideline, exception, or convention
- Store it in long-term memory so future reviews improve
We implemented this using AWS Bedrock AgentCore long-term memory (LTM): false-positive feedback is translated into a durable rule/exception and stored so the agent stops repeating the same mistake, without retraining the underlying model.
This turns real PR conversations into a continuous improvement loop. Over time, the agent should produce fewer repeat false positives, adapt better to each codebase’s intent, and stay high-signal even as repositories and practices evolve.
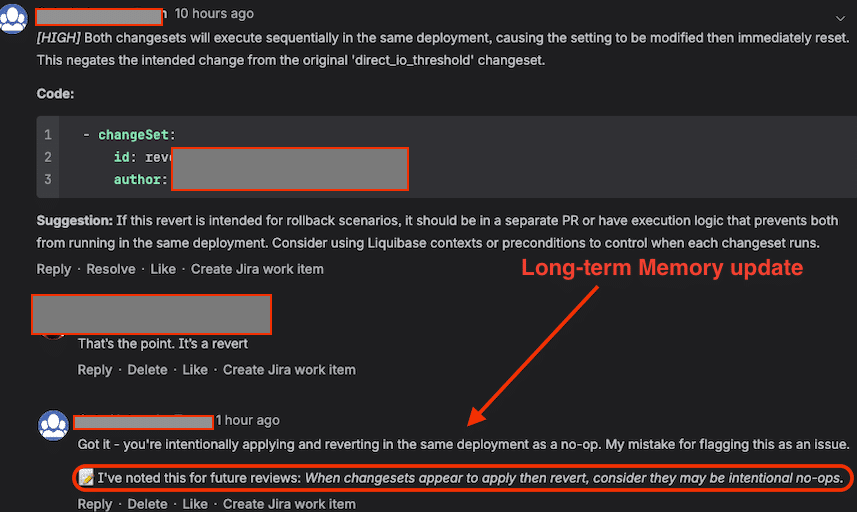
Figure 1. The agent records a correction into long-term memory and applies it in future reviews
ROI and why building in-house can be compelling
Building a pull request review agent in-house can offer strong ROI because it shifts from fixed per-developer licensing to usage-based spend that scales with actual review activity.
Seat-based tools typically scale linearly with headcount, even if review volume does not. A usage-based internal agent often lands in the cents-per-pull-request range for routine reviews, and can be tuned to allocate more compute only to complex or high-risk changes. In our case, we reduced commercial tooling costs down to an effective ~$10 per unique user while keeping continuous PR review coverage.
Beyond cost, the larger ROI often comes from fit and control:
- Enforcing internal coding standards, security requirements, and architectural guardrails
- Integrating internal signals such as ownership, CI outcomes, and operational risk tagging
- Applying governance controls such as redaction, auditability, and routing policies
At scale, the impact becomes measurable: the agent identifies ~7,000 high/critical severity issues each month, and ~70% of those findings are approved and resolved by engineers.
The practical outcome is a more aligned tool that can deliver higher-value feedback with less noise and better operational confidence.
PR metadata as a source of truth
To make the agent operationally useful beyond “comments on a PR,” we store PR metadata in MongoDB and capture structured fields such as affected components, inferred business flows, risk tags, and review outcomes.
This turns PRs into a queryable change-management dataset. You can trace what changed, why it changed based on the spec, which flows were impacted, and how the change correlates with incidents.
It also improves incident response and RCA by helping teams quickly connect production behavior back to the exact code changes and the system’s review signals, using the code and its PR context as the source of truth.
Developer experience and feedback loop
This system is new, and it will not be perfect on every pull request. Early on, the goal is not only to catch issues, but to improve the agent quickly through real developer interaction while keeping trust high and noise low.
In Cato R&D, we instruct developers to treat the agent as a review accelerator: start with the summary to quickly understand intent and impact, treat inline findings as high-signal warnings rather than style feedback, and respond directly in the PR thread when something looks wrong or missing. Those corrections become valuable learning signals for the agent’s long-term memory, helping it reduce repeat false positives and better adapt to repository-specific conventions over time. That feedback loop is how we scale the system across many repos, languages, and dependency graphs without drowning developers in noise.
Continuing to evolve
This is a practical example of agentic AI embedded in everyday R&D workflows, and can be served as a model for the evolution of self-evolving agents. The differentiator is not only the underlying model, but the system design: confidence gating to protect signal-to-noise, incident-linked evaluation to measure real impact, and a feedback loop that enables long-term improvement. It’s also a showcase of modern building blocks, Claude Agent SDK, AWS Bedrock AgentCore, and MongoDB, combined into an engineering system that improves with real usage.
As adoption grows, our focus remains consistent: reduce review friction, improve review quality, and surface the issues that matter before they reach production. The long-term goal is a review system that becomes increasingly aligned with Cato’s engineering standards, repository conventions, and real-world operational lessons, without increasing noise for developers.
Related Articles
One Click to Zero Trust: How Cato’s Agentless Microsegmentation Blocks Lateral Movement and Simplifies Network Security
Introducing Cato’s API Assistant: Your New Copilot for GraphQL
AIOps in the Cato SASE Platform: Using Predictive AI Networking to Shift from Reactive to Proactive IT




