
Reducing Time-to-Protect with Cato’s Self-Evolving Vulnerability Protection Agent





|
Listen to post:
Getting your Trinity Audio player ready...
|
TL;DR: In the age of frontier AI models, vulnerability discovery and exploit development are scaling faster than human defenders can manually respond. Security teams already face growing CVE volumes, shorter exploitation windows, and manual workflows for researching vulnerabilities, creating protections, validating them, and preparing them for deployment. As attackers weaponize vulnerabilities faster than organizations can patch them, time-to-protect is becoming a critical security metric.
At Cato, we built the Multi-Modal Vulnerability Protection Self-Evolving Agent to accelerate the path from CVE disclosure to customer protection. Across two pilot phases, the agent generated usable protections across multiple vulnerability classes with consistent results. In the first phase, multiple generated protections matched or exceeded protections already deployed in production. After workflow improvements, the second phase produced usable signatures for all six evaluated CVEs, with the fastest completed in 45 minutes. In this blog, we share the methodology, results, and key insights from evaluating a model-agnostic agentic workflow that improves through validation feedback, audit logs, and researcher review.
CVE Protection Agent Workflow
The goal of the workflow is to transform a newly disclosed vulnerability into a validated protection as quickly as possible while keeping security researchers in control of final decisions.
At a high level, the workflow consists of five stages and including learning and refining loop:
- Vulnerability intelligence collection
- Exploit analysis
- Protection generation
- Validation
- Researcher review
The workflow combines multiple AI models with the ability to analyze different types of security artifacts, including vendor advisories, CVE records, reputable private and public repositories, screenshots, and technical diagrams. This allows the agent to build a broader understanding of the vulnerability before generating and validating a protection. Figure 1 presents a high-level view of the agentic CVE protection workflow, from vulnerability analysis through validation and researcher review.
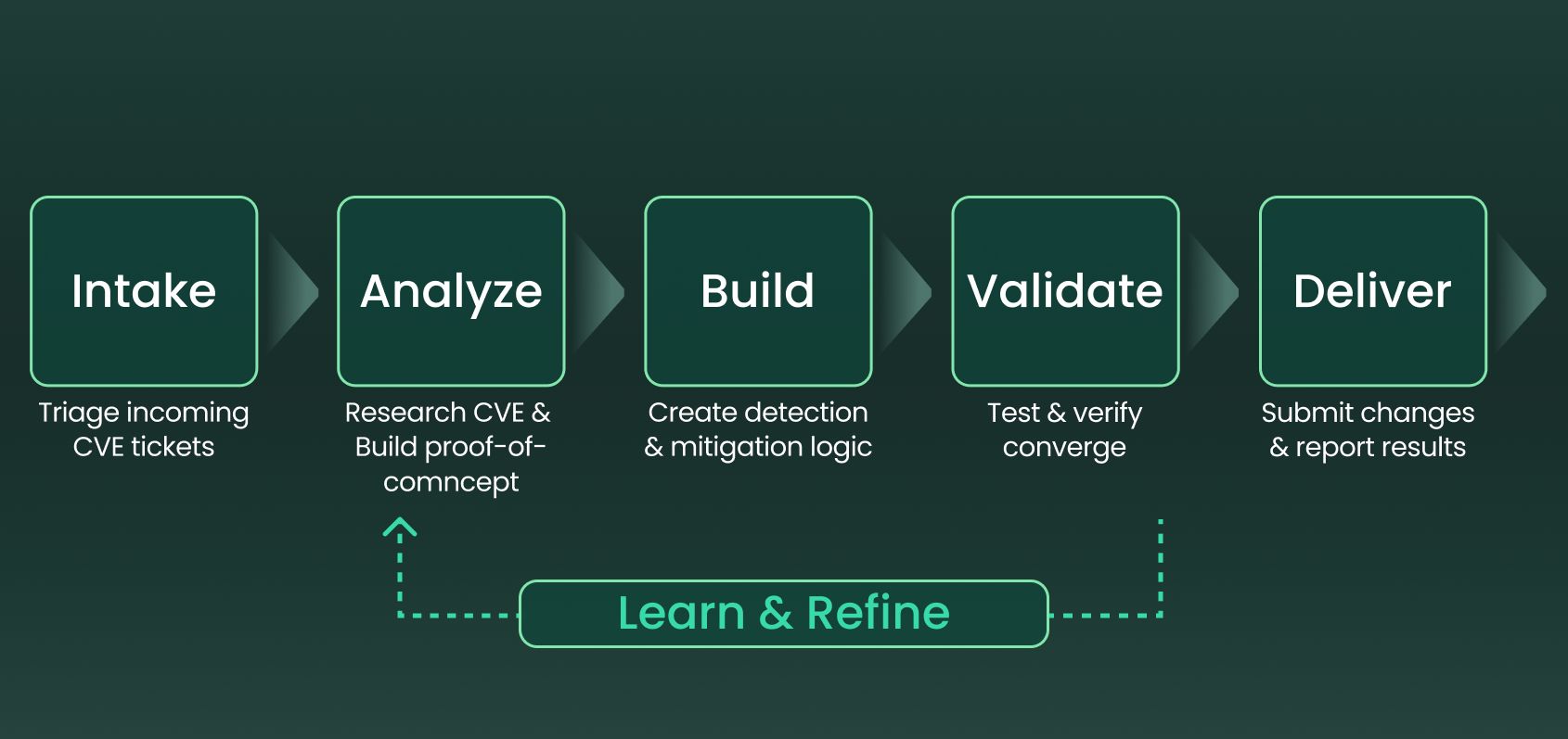
Figure 1. The Multi-Modal CVE Protection high-level Agent Workflow
Multi-Model and Multi-Modal Design
The workflow is both multi-model and multi-modal. It is multi-model because it can use different AI models depending on task complexity, and multi-modal because it can analyze different types of security artifacts, including advisories, source code, screenshots, technical diagrams, and proof-of-concept exploits.
One of the key design goals was flexibility. Different stages of vulnerability research require different reasoning capabilities, making it inefficient to use the same model for every task. During our evaluation, we primarily used Claude Sonnet 4.6 and Claude Opus 4.7, while also beginning evaluations with Claude Opus 4.8 and OpenAI GPT-5.5-Cyber shortly after their release.
Tasks such as metadata extraction, advisory parsing, and workflow orchestration can be handled efficiently by lower-cost models. More complex activities, such as exploit analysis, signature generation, and validation refinement, benefit from stronger reasoning models. The architecture is intentionally model-agnostic, allowing improvements in foundation models to benefit the workflow without redesigning the underlying system.
Behind the scenes, the agent is managed by an orchestration layer that coordinates 16 steps and sub-agents across the end-to-end workflow. Each sub-agent can also trigger additional sub-agents in parallel to improve efficiency. Integrity gates validate whether each step was completed as expected, and if a step does not meet the required criteria, it is automatically re-initiated until it passes validation.
Signature generation is not performed by a generic model alone. The workflow uses specialized agents trained on Cato’s accumulated security research knowledge, detection logic, IPS signature patterns, evasion techniques, and validation experience. Each agent is designed to specialize in a specific vulnerability class, such as remote code execution, authentication bypass, path traversal, denial of service, information disclosure, or generic exploitation. This class-specific specialization helps the workflow produce stronger protections for each vulnerability type instead of relying on a one-size-fits-all approach.
The workflow is also designed to analyze information from multiple sources and formats, including CVE advisories, vendor disclosures, security research blogs, reputable private and public repositories, technical diagrams, images, and screenshots. Combining these inputs allows the agent to build a richer understanding of vulnerability behavior before generating candidate protections.
Validation is a core part of the workflow, not an afterthought. Generated protections are tested for both false positives and false negatives against recent real-world traffic data from Cato’s data warehouse. This helps verify that protections detect relevant attack permutations without blocking legitimate traffic.
Finally, the workflow improves through feedback loops generated from validation outcomes, researcher reviews, execution traces, and audit logs. These insights are used to refine prompts, skills, workflow logic, specialized agents, and model routing decisions over time.
Self-Evolving Through Operational Feedback
A key design principle of the Multi-Modal CVE Protection Agent is continuous improvement. Each time the agent completes an end-to-end workflow and generates a pull request, security researchers review the proposed protection and provide feedback when refinements are needed. Corrections can be applied manually by researchers or automatically through supporting agents.
The feedback process does not end with a single pull request. On a recurring basis, an automated learning workflow analyzes completed pull requests, reviewer comments, and resolved issues. By comparing the original agent-generated protection with the final approved version, the system identifies recurring mistakes, missing logic, and improvement opportunities. These insights are then used to update the skills, workflows, validation logic, and knowledge used by the agent, helping reduce similar errors in future runs.
As a result, the agent does not remain static. Each review cycle becomes an opportunity to improve protection quality, accelerate future investigations, and continuously refine the end-to-end vulnerability research process.
Research Method
To evaluate the effectiveness of the Multi-Modal CVE Protection Agent, we conducted a pilot study across multiple vulnerability categories. The evaluation included 20 real-world vulnerabilities spanning six major attack classes. In the first phase, we evaluated 14 real-world vulnerabilities spanning six major attack classes, using CVEs for which protections already existed. This allowed us to compare the agent-generated protections against existing production protections. In the second phase, after improving the workflow based on the first phase, we evaluated six additional CVEs without existing protections in our environment. These second-phase CVEs came from some of the same vulnerability classes, including RCE, authentication bypass, and path traversal, but were not intended to cover every class one-by-one.
Table 1 summarizes the vulnerability categories included in the pilot and the number of CVEs tested in each category.
Table 1. Vulnerability Categories Included in the Pilot Evaluation
Evaluation Process
For each vulnerability, the agent analyzed the available vulnerability information, generated candidate protections, and validated the results against available telemetry and testing workflows.
The evaluation differed slightly between the two pilot phases. In the first phase, existing protections were removed from the testing environment, allowing us to compare the agent-generated protections against protections already available in production. In the second phase, the workflow was tested against vulnerabilities without pre-existing protections, allowing us to evaluate the improved workflow under fresh, real-world conditions.
Across both phases, the evaluation measured time-to-protect, protection quality, and the level of researcher intervention required.
Results
Figure 2 summarizes the first phase of the pilot evaluation, covering 14 vulnerabilities across multiple attack classes. The figure highlights execution time, lowest time per CVE, protection quality, and workflow success rates.

Figure 2. First Phase Agentic CVE Pipeline Pilot Results
The pilot results show that the agentic workflow was able to generate protections across a diverse CVE dataset with consistent time, and quality characteristics.
Table 2 summarizes the key pilot evaluation metrics of the first phase.
Table 2: First phase Pilot Evaluation Summary
Second Pilot Results
After refining the workflow based on the first pilot phase, we evaluated the agent on six vulnerabilities without pre-existing protections.
Figure 3 summarize the results: In the second round 6-CVE pilot, our CVE agent produced usable vulnerability signatures for every case and the lowest time per CVE was 45 min.
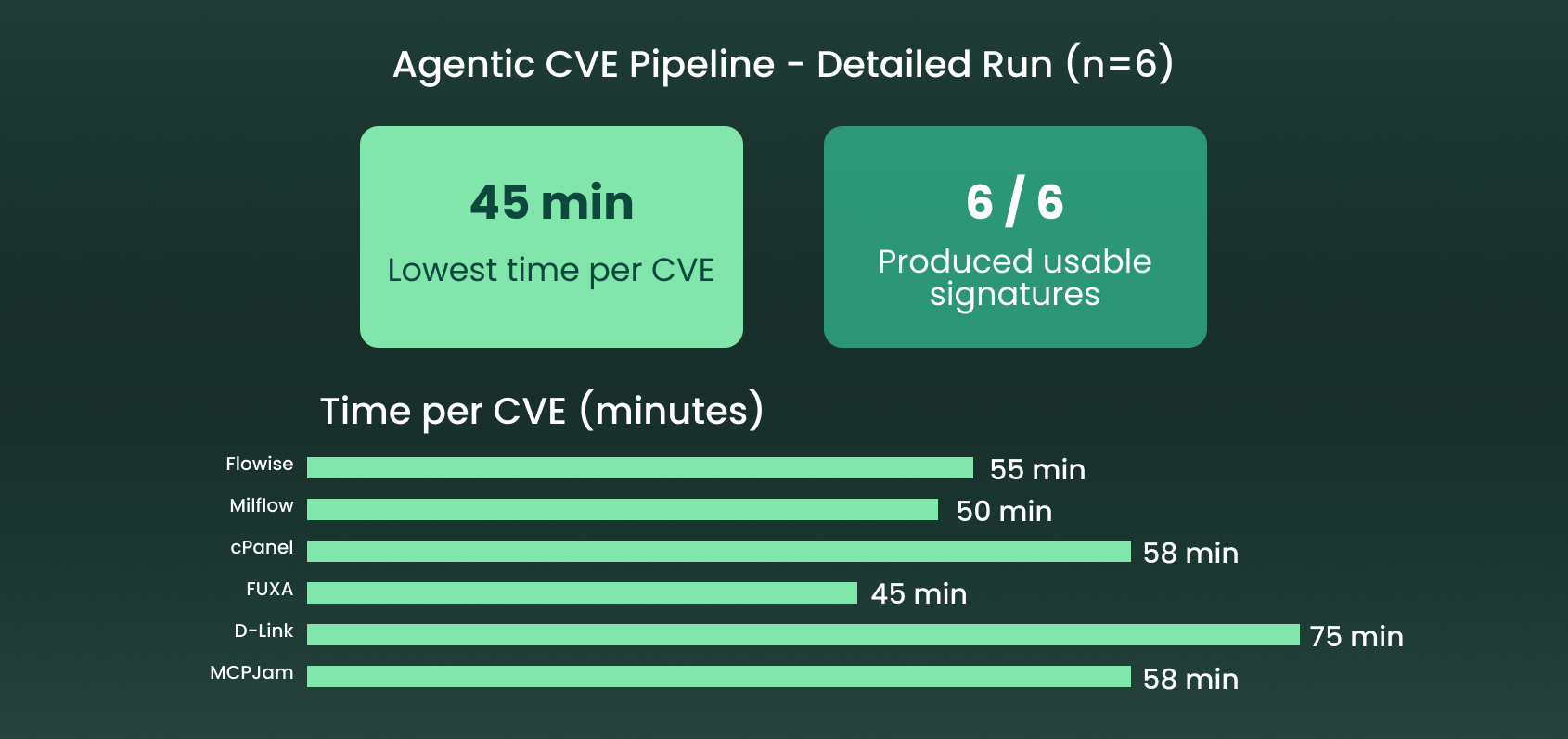
Figure 3. Second phase Agentic CVE Pipeline results
Key Findings
Fast and Efficient
Across both pilot phases, the workflow generated protections in hours rather than days. This is significant because manual protection creation typically requires hours of expert security researcher time, including vulnerability analysis, detection logic design, validation, review, and refinement. In the first phase, the fastest time-to-protect was 45min. After workflow improvements, the second phase produced usable signatures for all six evaluated CVEs, with multiple protections generated in under an hour and the fastest completed was 45 minutes as well.
High Success Rate
The workflow successfully generated usable protections for nearly all evaluated vulnerabilities. In the first phase, multiple generated protections matched or exceeded protections already deployed in production. In the second phase, the agent produced usable vulnerability signatures for all six newly disclosed CVEs.
Consistent and Predictable
Results across both phases showed repeatable behavior across multiple vulnerability classes, with execution time remaining within practical ranges rather than depending on isolated successful runs.
Safety Controls Functioned as Intended
In one case, the workflow correctly halted progress because sufficient public exploit information was unavailable. This demonstrated the importance of policy enforcement and guardrails within autonomous security workflows.
Table 3 presents the full pilot evaluation dataset and results.
Table 3: First Phase Pilot Evaluation Dataset and Results
Table 4 summarizes the results from the second pilot phase.
Table 4: Second Phase Results Using the Improved Workflow
Protection Quality Analysis
Beyond speed, the evaluation focused on whether the generated protections were precise, efficient, and suitable for researcher review. Across the pilot, multiple generated protections reached production-quality levels, with some requiring only limited refinement before approval.
The agent was able to account for important detection considerations such as attack variations, encoding differences, signature specificity, and false-positive reduction. This helped ensure that the generated protections were not only fast to produce, but also practical for real-world enforcement.
These findings suggest that agentic vulnerability research can contribute to faster and more efficient protection engineering while keeping researchers in control of final validation and approval.
Early Evaluation of Claude Opus 4.8
One of the advantages of a model-agnostic architecture is the ability to rapidly adopt new foundation models as they become available.
Shortly after Claude Opus 4.8 became available on May 28, 2026, we evaluated it using CVE-2026-41940, a cPanel vulnerability we previously discussed. Table 5 shows the results of this early Claude Opus 4.8 evaluation.
Table 5: Early Evaluation of Claude Opus 4.8
The workflow generated a high-quality protection on the first run in less than an hour.
Why the Platform Matters
The effectiveness of agentic vulnerability protection is not determined solely by the underlying AI model. A model can help analyze a vulnerability or generate a candidate protection, but the real value comes from the architecture around it, orchestration, validation, feedback loops, and the ability to deliver protections quickly and safely at scale.
Cato’s cloud-native architecture enables the Multi-Modal CVE Protection Agent to move from vulnerability analysis to customer protection without requiring customer action. New protections can be validated against real-world traffic data, deployed across Cato’s global PoP network, and delivered through a unified security platform without maintenance windows, appliance updates, or manual intervention. This reinforces a broader principle we discussed in The Mythos Moment: long-term AI value comes not only from the foundation model, but from the architecture, orchestration, and feedback loops built around it.
The Mythos Moment | Read the blogDiscussion and Conclusion
The pilot and follow-up research demonstrated that agentic vulnerability research can meaningfully reduce time-to-protect across multiple vulnerability classes. The Multi-Modal CVE Protection Agent consistently generated protections with predictable execution times, reasonable costs, and strong quality outcomes. Just as important, the research showed that the bottleneck is shifting: generating protections is no longer the hardest part, validating and operationalizing them safely at scale is where platform architecture, real-world telemetry, and researcher oversight become critical.
This is no longer only a pilot. Cato researchers are already using this workflow to help deliver faster and stronger protections to customers. Human expertise remains central to the process, researchers review outcomes, validate complex cases, and make final detection decisions when needed, while the agent automates repetitive research and engineering tasks at machine scale. As foundation models continue to evolve, model-agnostic architectures like this provide a practical path for translating AI advances into faster customer protection.
Related Articles
Cato CTRL™ Threat Research: Threat Actors Abuse Simplified AI to Steal Microsoft 365 Credentials

Cato CTRL™ Threat Research: When OpenClaw, Your AI Personal Assistant, Becomes the Backdoor





