
Cato CTRL™ Threat Research: New Vulnerabilities in NVIDIA NeMo and Meta PyTorch Enable Full System Compromise


Table of Contents
|
Listen to post:
Getting your Trinity Audio player ready...
|
Executive Summary
Cato CTRL has discovered high-severity vulnerabilities in NVIDIA NeMo (CVE-2025-33236 with a CVSS score of 7.8) and Meta PyTorch that turns AI model files into remote code execution (RCE) vectors. The NeMo vulnerability allows RCE by importing a malicious AI model. The NeMo framework silently executes threat actor-controlled code with no warning. The PyTorch vulnerability bypasses weights_only=True, the ecosystem’s recommended safety mechanism, enabling heap buffer overflow even when users follow best practices. Together, these vulnerabilities expose the AI model pipeline as an unmonitored software supply chain.
Every company adopting AI is downloading AI models from public repositories into systems that touch customer data, cloud credentials, and production infrastructure. Most security teams treat these AI models as harmless data files. They’re not. The vulnerabilities we found mean that simply loading an AI model file can give a threat actor full access to the system running it.
- NVIDIA NeMo – The Framework Removes the Safety Check: NeMo hardcodes trust_remote_code=True across multiple AI model importers, silently executing threat actor-controlled Python code during any HuggingFace model import.
- Meta PyTorch – The Safety Check Is Broken: PyTorch’s weights_only=True is the universally recommended defense against malicious model files. Our research shows it can be bypassed through a storage size mismatch that triggers heap buffer overflow, even with weights_only=True enabled.
Both vulnerabilities lead to RCE, data exfiltration, and full system compromise. The systems running these frameworks are not developer laptops. They are GPU clusters and ML pipelines with IAM roles, cloud credentials, and direct access to data lakes. A single malicious model load can give a threat actor a privileged foothold deep inside production infrastructure.
Timeline & Disclosure
- NVIDIA NeMo:
- September 10, 2025: Vulnerability discovered and reported to NVIDIA via bug bounty program.
- September 12, 2025: Vulnerability reproduced and forwarded to NVIDIA team.
- September 15, 2025: NVIDIA PSIRT opened tracking number.
- February 5, 2026: Vulnerability accepted by NVIDIA.
- February 17, 2026: Public disclosure and CVE assigned.
- Meta PyTorch:
- December 22, 2025: Vulnerability discovered.
- December 23, 2025: Reported to Meta PyTorch security team.
- January 29, 2026: Report closed by vendor as out of scope.
Technical Overview
The AI Supply Chain Problem
Supply chain attacks have defined the last half-decade of cybersecurity. SolarWinds showed that a trusted software update could deliver nation-state malware to thousands of organizations. The xz-utils backdoor demonstrated that even a small open-source utility could be subverted to compromise secure shell protocol (SSH) authentication across the Linux ecosystem. Log4Shell proved that a single vulnerable dependency could cascade across millions of applications overnight.
These incidents reshaped how the industry thinks about trust. Software Bill of Materials (SBOM), dependency scanning, package signing, and provenance verification became standard practice. The lesson was clear: anything you pull from a public repository and run in your environment is part of your attack surface.
Then came the AI boom. And the industry forgot everything it learned.
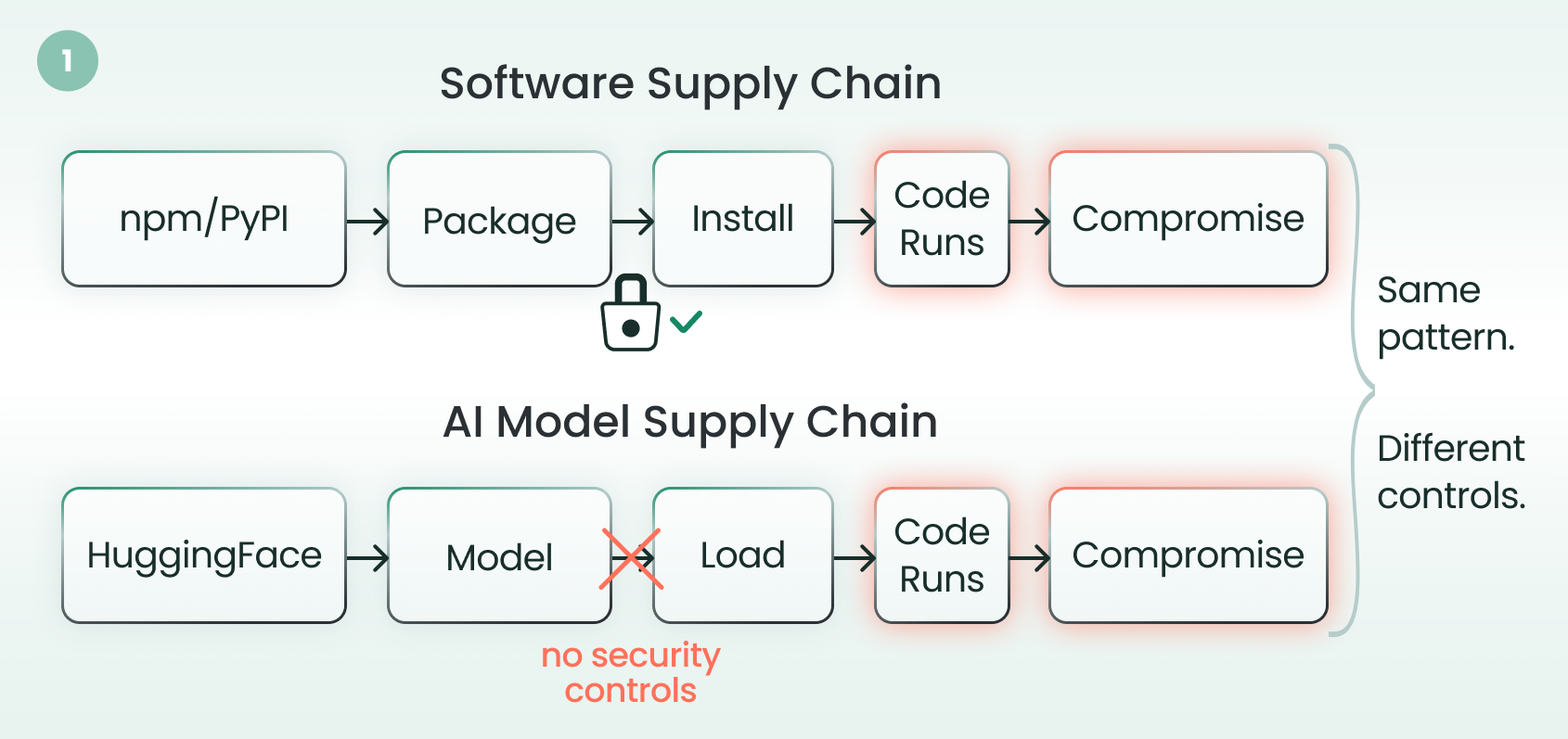
Figure 1. The AI model supply chain mirrors the traditional software supply chain — but without security controls; both paths lead from a public repository to code execution, yet only one is monitored
Today, organizations download AI models from HuggingFace and other public repositories at massive scale. They load them into GPU clusters with access to cloud credentials, customer data, and production infrastructure with almost none of the supply chain security controls they’d apply to a Node.js package or Docker image.
The assumption is that AI models are data. That assumption is wrong. AI models can carry executable code, and the frameworks that load them have dangerous defaults that silently enable that code to run.
Our research uncovered two independent vulnerabilities that illustrate how broken the AI model supply chain is. One where the framework silently removes a safety check. Another where the safety check itself is broken. Both lead to the same outcome: RCE from loading an AI model file.
Vulnerability #1: NVIDIA NeMo – Hardcoded Trust
NVIDIA NeMo is a widely used framework for building and fine-tuning large language models (LLMs) in enterprise environments.
When loading models from HuggingFace, a parameter called trust_remote_code controls whether Python code bundled inside an AI model repository gets executed during import. When set to True, the framework downloads and runs arbitrary Python files from the repo, effectively turning an AI model import into a code import. By default, this parameter is set to False.
The NeMo Framework hardcoded it to True across multiple AI model importers. Every model imported from HuggingFace through NeMo automatically executes any bundled Python code.
The Attack
A threat actor creates a HuggingFace repository that looks like a legitimate AI model, plus Python files containing a hidden payload. On import, NeMo executes the file and the threat actor can silently exfiltrate environment variables, cloud credentials, API keys, secrets.

Figure 2. A typosquatting attack on HuggingFace, where the threat actor registers meta-1lama (digit “1”) instead of the legitimate meta-llama (lowercase “l”)
Getting a victim to import is easier than it sounds.
- Typosquatting: Registering meta-1lama instead of meta-llama (digit 1 replacing lowercase l).
- Social engineering: Sharing an “enhanced” model on Reddit or Discord.
- Compromised accounts: Hijacking a legitimate researcher’s repo and pushing malicious code to an already-trusted repository.
Vulnerability #2: Meta PyTorch – The Broken Safety Net
Meta PyTorch is the dominant machine learning (ML) framework for AI model training, powering AI development across millions of organizations worldwide.
It saves AI models using Python’s pickle format, which can embed executable code inside data files. The risks of pickle deserialization are well-documented. The ecosystem’s answer was weights_only=True, a parameter that restricts which Python classes can be deserialized during loading. It is the ecosystem’s widely recommended defense against malicious AI model files.
Our research found that this defense can be bypassed.
weights_only=True restricts pickle classes but does not validate tensor sizes against actual file data. A threat actor can craft a .pt file where the pickle metadata claims a large tensor size while the actual data file is tiny. PyTorch trusts the claimed size, allocates a small buffer, but exposes a tensor that can read and write far beyond its boundaries. This is a classic heap buffer overflow.
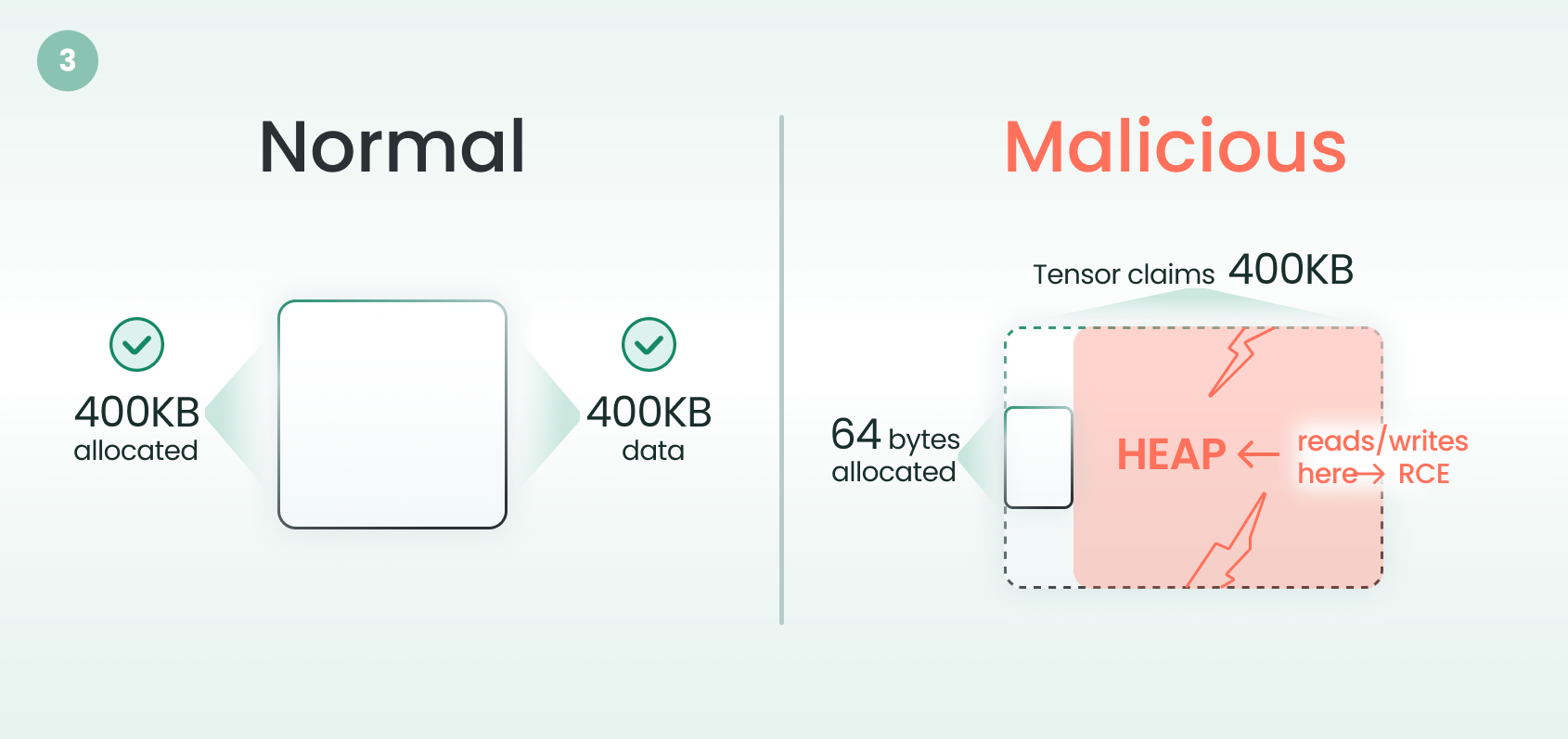
Figure 3. PyTorch weights_only=True bypass, where the storage size mismatch triggers heap buffer overflow
The critical point: organizations that follow every best practice: verifying checksums, auditing sources, and enabling weights_only=True remain vulnerable. The safety net has a hole in it.
Conclusion
The vulnerabilities in NVIDIA NeMo and Meta PyTorch represent two sides of the same systemic failure. One framework in NeMo silently disables a safety check that was intentionally put in place. The other safety check in PyTorch doesn’t cover the full attack surface. Different root causes, same outcome: RCE from loading a malicious AI model file.
As model sharing accelerates and AI pipelines become critical infrastructure, this attack surface will only grow. The industry needs the same rigor it has built for traditional software supply chains; signing, verification, provenance, sandboxing, and above all, secure-by-default configurations. AI framework developers should never silently remove safety mechanisms on the user’s behalf.
Protections
- Ensure all AI/ML frameworks are updated to the latest vendor-patched versions.
- Avoid using trust_remote_code=True.
- Don’t assume weights_only=True is sufficient. Monitor for upstream patches and apply them immediately.
- Prefer Safetensors over pickle-based formats.
- Load AI models in sandboxed environments. Never load untrusted AI models on systems with production credentials.
Related Articles

Cato CTRL™ Threat Brief: “ToolShell” Exploit Targeting Microsoft SharePoint Vulnerabilities






