Surging Without Slowing: How We Mastered Japan’s Golden Week Traffic Spike




|
Listen to post:
Getting your Trinity Audio player ready...
|
Introduction
Japan’s Golden Week is one of the most anticipated holiday seasons in the region, but for IT and network operations teams it’s a well-known pressure test. As businesses reopen after a full shutdown, millions of workers log in simultaneously at 9:00 AM local time, creating an intense and rapid traffic surge.
At Cato Networks, we’ve come to anticipate this moment each year. But this time, our goal wasn’t just to ‘handle it’. We set out to deliver a flawless experience to every user, even as traffic more than doubled during peak moments.
We live by the principle that says, ‘train hard, fight easy.’ That means preparing our infrastructure for conditions far harsher than what production systems are likely to face. We are also our own toughest critics, constantly stress-testing and challenging our assumptions to ensure that when the real-world challenge arrives, we’re not just ready. We’re confident.
This post shares the behind-the-scenes engineering and operational story of how we prepared for and managed one of the most demanding real-world scenarios in our global network, and we did so without compromise.
Understanding the Golden Week Surge
Unlike post-holiday patterns in the U.S., where workforce reactivation is spread across multiple time zones and states, Japan’s return to work is highly synchronized and geographically dense. A large concentration of employees resume operations simultaneously, often from central metropolitan locations, which places sharp demand on the closest regional PoPs, particularly Tokyo and Osaka.
We’ve observed that within the first 30 minutes of the workday restart, traffic volume can surge by more than 2.5x compared to regular peak hours. This spike isn’t just user logins. It includes device-wide sync operations, software updates, and collaboration platform refreshes. In fact, our traffic analytics during the surge revealed that applications like Microsoft OneDrive, Windows Update, Office 365, Adobe, SharePoint, and Microsoft Exchange made up nearly 70% of all traffic.
These dynamics not only test bandwidth and throughput, they also challenge every layer of our architecture, from encryption processing to real-time routing decisions.
The Challenge
This year, we anticipated a significant surge following Golden Week, and our projections proved accurate. We experienced a sharp increase in simultaneous user connections alongside a major spike in bandwidth consumption, largely driven by SaaS application updates. The demand was widespread across our environment. Our branch users reauthenticated, downloaded Windows updates, and synced files. Mobile and remote users reconnected through VPN tunnels. Cloud workloads resumed activity and synchronized with SaaS platforms. Real-time traffic required active prioritization, shaping, and rerouting to maintain performance. Our architecture had to deliver not only scale, but also precision under pressure.
Cato’s Architecture: Built for Peak Load and Resiliency
We designed our platform with these extreme conditions in mind, combining a cloud-native, multi-core architecture with deep observability and automated defenses.
Multi-Core & Isolation for Extreme Sites
To ensure we could meet surge demands, we relied on several key architectural capabilities:
- Distributed multi-core architecture with load sharing across multiple CPUs enables support for socket sites with bandwidths of up to 10 Gbps.
- Resource reservation ensures consistent performance for high-bandwidth sites, even under extreme load.
- Unique offload architecture manages large-scale encryption and decryption tasks independently, freeing CPU resources and improving overall bandwidth efficiency.
DTLS Optimization and Termination at the Core
All encrypted tunnels terminating in our PoPs rely on DTLS, which requires efficient, secure, and high-throughput decryption. Our infrastructure is optimized to perform this at scale, using offloaded hardware-accelerated crypto modules and dynamic services cores allocation.
Resiliency Readiness During the Surge
Regardless the surge caused by the return from the holiday, and in parallel with legitimate traffic, we continuously monitor for DDoS attempts and login brute-force patterns. Our inline detection engines, trained on regional baselines can filter any malicious traffic in real time.
We have also recently deployed our fourth high-capacity router in Tokyo and successfully load balanced traffic across all PoP locations in the region, enhancing both redundancy and performance under peak demand.
Our monitoring capabilities efforts to maintain resiliency during the surge included the following activities:
- At any time, we were able to detect and mitigate volumetric floods without affecting the end-user experience.
- We monitored DPDK miss rates and port utilization, ensuring our NICs and packet processors performed within the expected thresholds.
- We correlated router synchronization anomalies with traffic patterns to proactively catch subtle failures before they could escalate into user-impacting issues.
This was more than just scaling. It was resilience in the face of both legitimate demand and potential hostile conditions.
Japan-Specific Infrastructure Readiness
Before the first packet hit our network post-holiday, we had been preparing our Japan infrastructure to absorb this unique load scenario. Here’s what we did:
PoP Expansion & Redundancy
We added a new PoP in Japan and upgraded existing infrastructure to ensure greater geographical distribution and resiliency, This included the following activities:
- We upgraded our router hardware to support significantly higher physical throughput, expanding both port density and interface capacity. This allowed each router to handle dramatically more concurrent traffic, aligning with the expected surge in demand from our Japan PoPs.
- We expanded the internal data paths within our PoPs, linking customer-facing services to core processing components, to support increased east-west traffic under load.
- Adding more CPU cores to scale compute-intensive functions like packet inspection, tunneling, and encryption.
Leveraging Monitoring Capabilities
We leveraged our monitoring capabilities to identify stress points and pressure points, allowing us to proactively avoid issues and fine-tune performance across multiple layers. For example:
- Real-time monitoring of router traffic, VPN tunnel counts, and tunnel throughput at each PoP.
- Visibility into port utilization, level packet drops, and synchronization failures across components.
- Custom dashboards for each Japan PoP to track both health and performance during the first hour of workday resumption.
This gave our engineers a precise view of every element in the system, ensuring that user experience would not be impacted.
In Figure 1, we show that total router traffic at the Tokyo PoP doubled in bandwidth from April 29 (a single-day holiday) to May 7 (the first workday following Golden Week). In Figure 2 (displayed in UTC), we highlight a router traffic peak at one of our Japan PoPs occurring exactly at 9:00 AM JST (midnight UTC). Figure 3 shows a corresponding jump in VPN tunnel count at 9:00 AM, while Figure 4 illustrates the increase in VPN tunnel throughput, including both DTLS and IPSec connections, at the same time. Figures 5 and 6 demonstrate how ZTNA user connections and throughput surged to more than twice the volume of regular days.
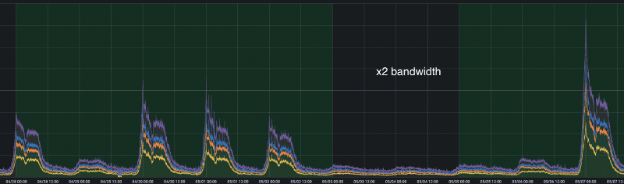
Figure 1: Tokyo PoP – Total Router Traffic Doubled in Bandwidth from April 29 (Single-Day Holiday) to May 7 (First Workday After Golden Week)
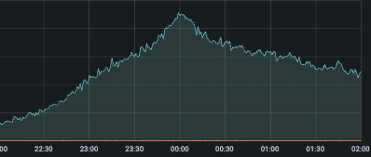
Figure 2: Tokyo PoP – Total Router Traffic Volume
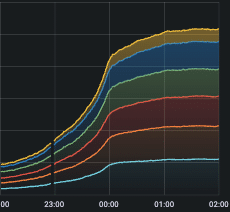
Figure 3: Tokyo PoP – Total VPN Tunnels (including DTLS and IPSec connections)
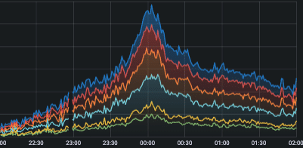
Figure 4: VPN Tunnel (including DTLS and IPSec connections) Throughput Over Time
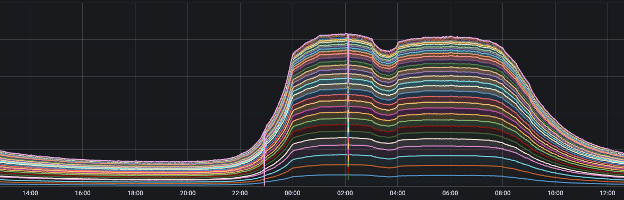
Figure 5: Total ZTNA User Connections in Japan
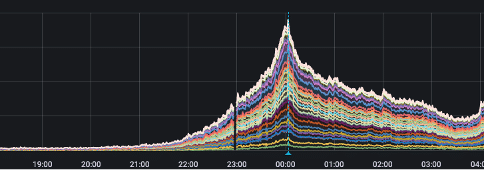
Figure 6: Total Japan ZTNA User Throughput
Diving Into Application Usage During the Post-Holiday Surge
In Figure 7, we show the most significant applications in terms of bandwidth consumption. Windows Update, Microsoft Office365, and Adobe were the leading contributors to network traffic across Japan PoPs following the Golden Week holiday, reflecting a combination of system updates and a return to productivity. OneDrive, SharePoint, Outlook, and Microsoft General services also registered meaningful usage, indicating sustained collaboration and communication within Microsoft’s ecosystem. This distribution highlights the dominant role of Microsoft services in post-holiday activity and underscores the need for infrastructure that can reliably support cloud-driven collaboration at scale.
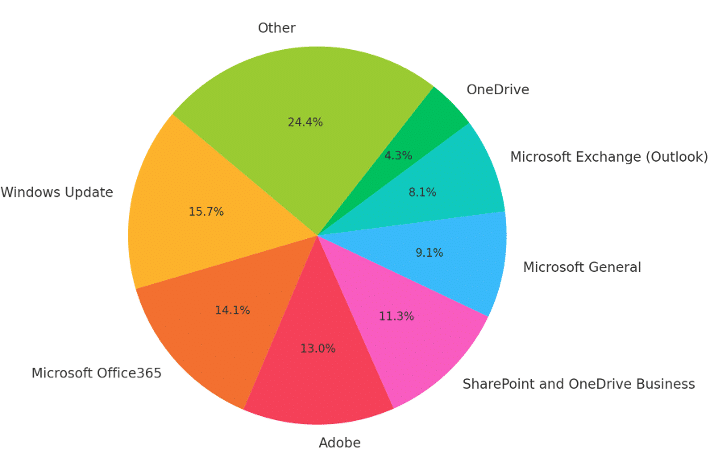
Figure 7: Top Application Usage Across Japan PoPs
Operational Execution
The foundation was built and now came the moment of truth. Our NOC teams were fully staffed and on active standby, especially during the 9:00 to 10:00 AM JST window where we projected the surge.
Automated + Manual Observability
We combined automated anomaly detection with manual engineering oversight. Key capabilities included:
- Weekly analysis of load points in customer configurations (e.g., misconfigured egress IPs causing unnecessary hops) allowed us to tune policies in advance.
- Real-time monitoring of services cores per site, ensuring no CPU cores were nearing saturation.
- We monitored internal PoP paths and external peer connections to our internet providers and were prepared to respond to any anomalies using our automated tools.
Outcome: Optimal Experience at Peak Demand
The result: strong and consistent performance across our infrastructure, even under record-breaking load. Key highlights included:
- Peak VPN tunnel count and throughput exceeded previous years by over 2x, absorbed without latency spikes.
- Router traffic volume hit all-time highs, yet packet drop rates remained negligible.
Through proactive scaling, disciplined operations, and an architecture designed for resiliency, we delivered exactly what our customers needed. A network that simply worked, no matter the volume or complexity behind the scenes.
Related Articles
When Quantum Turns Encryption Into a Time Problem

Gradual by Design: What the Cloudflare Outage Reveals About Robust SASE Architecture and Operations
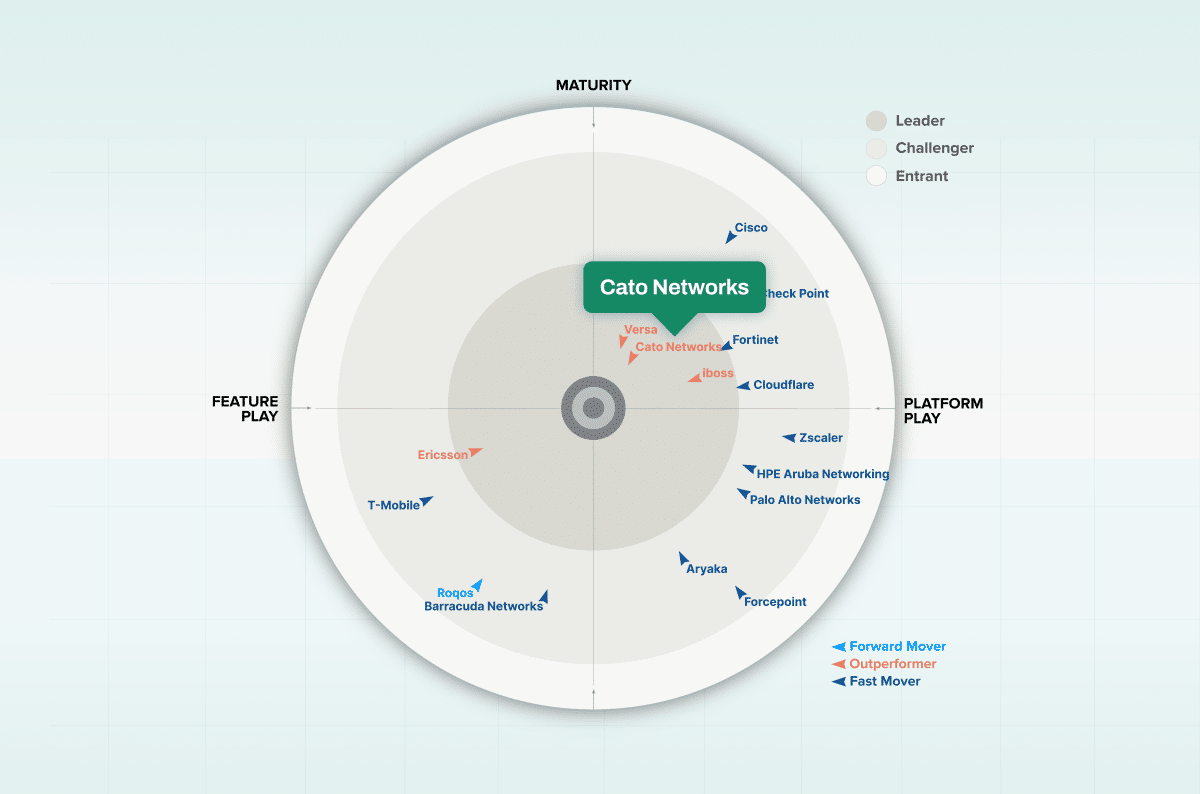
Cato Networks Named a SASE Industry Leader and Outperformer for the THIRD Consecutive Year