
Security Testing Shows How SASE Hones Threat Intelligence Feeds, Eliminates False Positives


|
Listen to post:
Getting your Trinity Audio player ready...
|
Threat Intelligence (TI) feeds provide critical information about attacker behavior for adapting an enterprise’s defenses to the threat landscape. Without these feeds, your security tools, and those used by your security provider would lack the raw intelligence needed to defend cyber operations and assets.
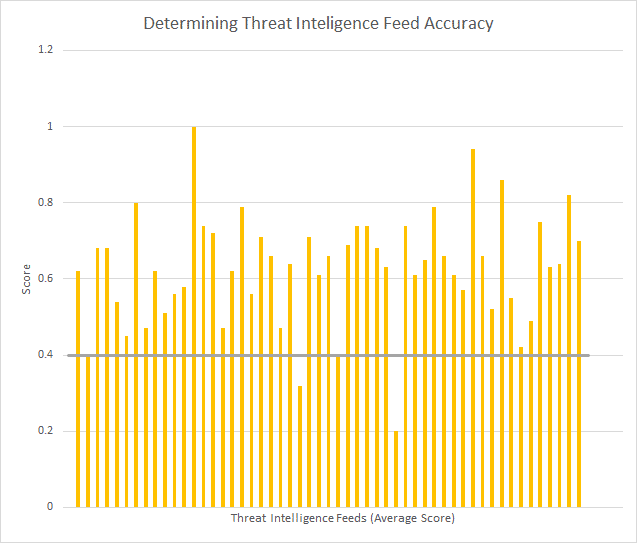
But coming from open-source, shared communities, and commercial providers, TI feeds vary greatly in quality. They don’t encompass every known threat and often contain false positives, leading to the blocking of legitimate network traffic, negatively impacting the business. Our security team found that even after applying industry best practice, 30 percent of TI feeds will contain false positives or miss malicious Indicators of Compromise (IoCs).
To address this challenge, Cato developed a purpose-built reputation assessment system. Statistically, it eliminates all false positives by using machine learning models and AI to correlate readily available networking and security information. Here’s what we did, and while you might not have the time and resources to build such a system yourself, here’s the process for how you can do something similar in your network.
TI Feeds: Key to Accurate Detection
The biggest challenge facing any security team is identifying and stopping threats with minimal disruption to the business process. The sheer scope and rate of innovation of attackers put the average enterprise on the defensive. IT teams often lack the necessary skills and tools to stop threats. Even when they do have those raw ingredients, enterprises only see a small part of the overall threat landscape.
Threat intelligence services claim to fill this gap, providing the information needed to detect and stop threats. TI feeds consist of lists of IoCs, such as potentially malicious IP addresses, URLs, and domains. Many will also include the severity and frequency of threats.
To date, the market has hundreds of paid and unpaid TI feeds. Determining feed quality is difficult without knowing the complete scope of the threat landscape. Accuracy is particularly important to ensure minimum false positives. Too many false positives result in unnecessary alerts that overwhelm security teams, preventing them from spotting legitimate threats. False positives also disrupt the business, preventing users from accessing legitimate resources.
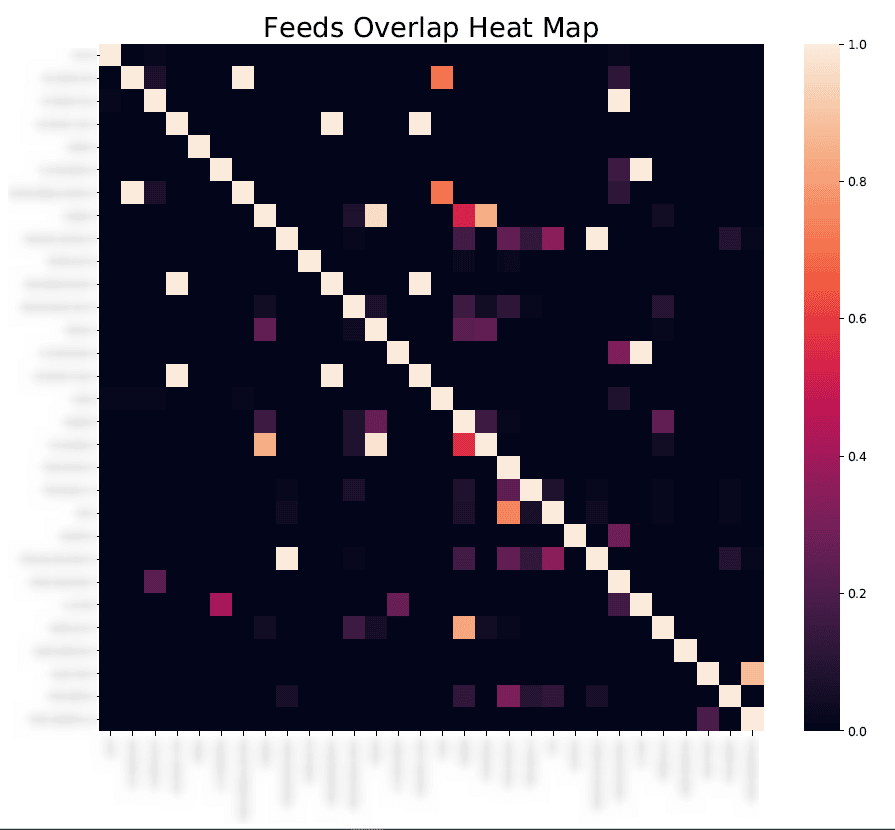
Security analysts have tried to prevent false positives by looking at the IoCs common among multiple feeds. Feeds with more shared IoCs have been thought to be more authoritative. However, using this approach with 30 TI feeds, Cato’s security team still found that 78 percent of the feeds that would be considered accurate, continued to include many false positives.
Networking Data Helps Isolate False Positives
To further refine security feeds, we found augmenting our security data with network flow data can dramatically improve feed accuracy. In the past, taking advantage of networking flow data would have been impractical for many organizations. Significant investment would have been required to extract event data from security and networking appliances, normalize the data, store the data, and then have the necessary query tools to interrogate that datastore.
The shift to Secure Access Service Edge (SASE) solutions, however, converges networking and security together. Security analysts will now be able to leverage previously unavailable networking event data to enrich their security analysis. Particularly helpful in this area is the popularity of a given IoC among real users.
In our experience, legitimate traffic overwhelmingly terminates at domains or IP addresses frequently visited by users. We intuitively understand this. The sites frequented by users have typically been operational for some time. (Unless you’re dealing with research environments, which frequently instantiate new servers.) By contrast, attackers will often instantiate new servers and domains to avoid being categorized as malicious – and hence being blocked – by URL filters.
As such, by determining the frequency of which real users visit IoC targets – what we call the popularity score – security analysts can identify IoC targets that are likely to be false positives. The less user traffic destined for an IoC target, the lower the popularity score, and the greater the probability that the target is likely to be malicious.
At Cato, we derive popularity scoring by running machine learning algorithms against a data warehouse, which is built from the metadata of every flow from all our customers’ users. You could do something similar by pulling in networking information from various logs and equipment on your network.
Popularity and Overlap Scores to Improve Feed Effectiveness
To isolate the false positives found in TI feeds, we scored the feeds in two ways: “Overlap Score” that indicates the number of overlapping IoCs between feeds, and “Popularity Score.” Ideally, we’d like TI feeds to have a high Overlap Score and a low Popularity Score. Truly malicious IoCs tend to be identified by multiple threat intelligence services and, as noted, are infrequently accessed by actual users.
However, what we found was just the opposite. Many TI feeds (30 percent) had IoCs with low Overlap Scores and high Popularity Scores. Blocking the IoCs in these TI feeds would lead to unnecessary security alerts and frustrating users.
The TI Feeds Are Finely Tuned – Now What?
Using networking information, we could eliminate most false positives, which alone is beneficial to the organization. Results are further improved, though, by feeding this insight back into the security process. Once an asset is known to be compromised, external threat intelligence can be enriched automatically with every communication the host creates, generating novel intelligence. The domains and IPs the infected host contacted, and files downloaded, can be automatically marked as malicious and added to the IoCs going into security devices for even greater protection.
Related Articles
Clustering-as-a-Tool: Leveraging Machine Learning for Device Data Insights and Signature Creation


Cato CTRL™ Insights: Governing Hermes Agent, Security for AI That Learns, Remembers, and Acts




