
Cato Resiliency: An Insider’s Look at Overcoming the Interxion Datacenter Outage


|
Listen to post:
Getting your Trinity Audio player ready...
|
The strength of any network is its resiliency—its ability to withstand disruptions that might otherwise cause a failure somewhere in the connectivity. The Cato Cloud service proved its resiliency during the massive hours-long service outage of the LON1 Interxion data center at its central London campus on January 10.
Interxion suffered a catastrophic loss of power beginning just before 18:00 UTC on a Monday evening. The failure cut out multiple power feeds going into the building, and equipment designed to switch to backup generator power also failed. The result was complete loss of power leading to service outages for numerous customers dependent on this particular data center. Hundreds of companies were impacted with the London Metal Exchange, for example becoming unavailable for nearly five hours.
Cato customers were also impacted by this outage – for a few seconds. For the benefit of proximity to the financial and technology hubs near Shoreditch, Cato has a PoP in this Interxion datacenter. That means that Cato’s customers, too, were affected by the sudden unavailability of our PoP. However, most customers suffered few repercussions as their traffic was automatically moved over to another nearby Cato PoP for continued operation. The transfer took place within seconds of the LON1 power failure, and I’d venture a guess that few Cato customers even noticed the switch-over.
To a network operator, this is a true test of both resiliency and scale.
Cato Demo | TLS Inspection in MinutesCato’s Response to the Outage Was Both Immediate and Automatic
On January 10 at 17:58 UTC, we started to receive Severity-1 alerts about our London PoP. The alerts indicated that all our machines in London were down. We were unable to access our hardware with any of our carriers.
Calling Interxion proved impossible. Only later did we learn that the power outage that took down the datacenter also disrupted their communications. The same was true for opening a support ticket; it too elicited no response. Checking Twitter showed different complaints about the same thing. Despite having no word directly from Interxion, we understood there was a catastrophic power failure. We incident to our customer about 10 minutes after it started on our status page — official reports would only be received several hours later.
As for the impact on SASE availability, every Cato customer sending traffic through this London PoP using a Cato Socket (Cato’s Edge SD-WAN device) had already been switched over within seconds of the power outage to a different PoP location. They were humming away as if nothing had happened.
Most customers had their traffic routed to Manchester instead of London. Our PoPs have been designed with surplus capacity precisely for these reasons. You can see from the chart below that our Manchester PoP saw a sudden increase in tunnels coming in, and we were able to accommodate the higher traffic load without a problem. This demonstrates both the resiliency and the scale of Cato’s backbone network.
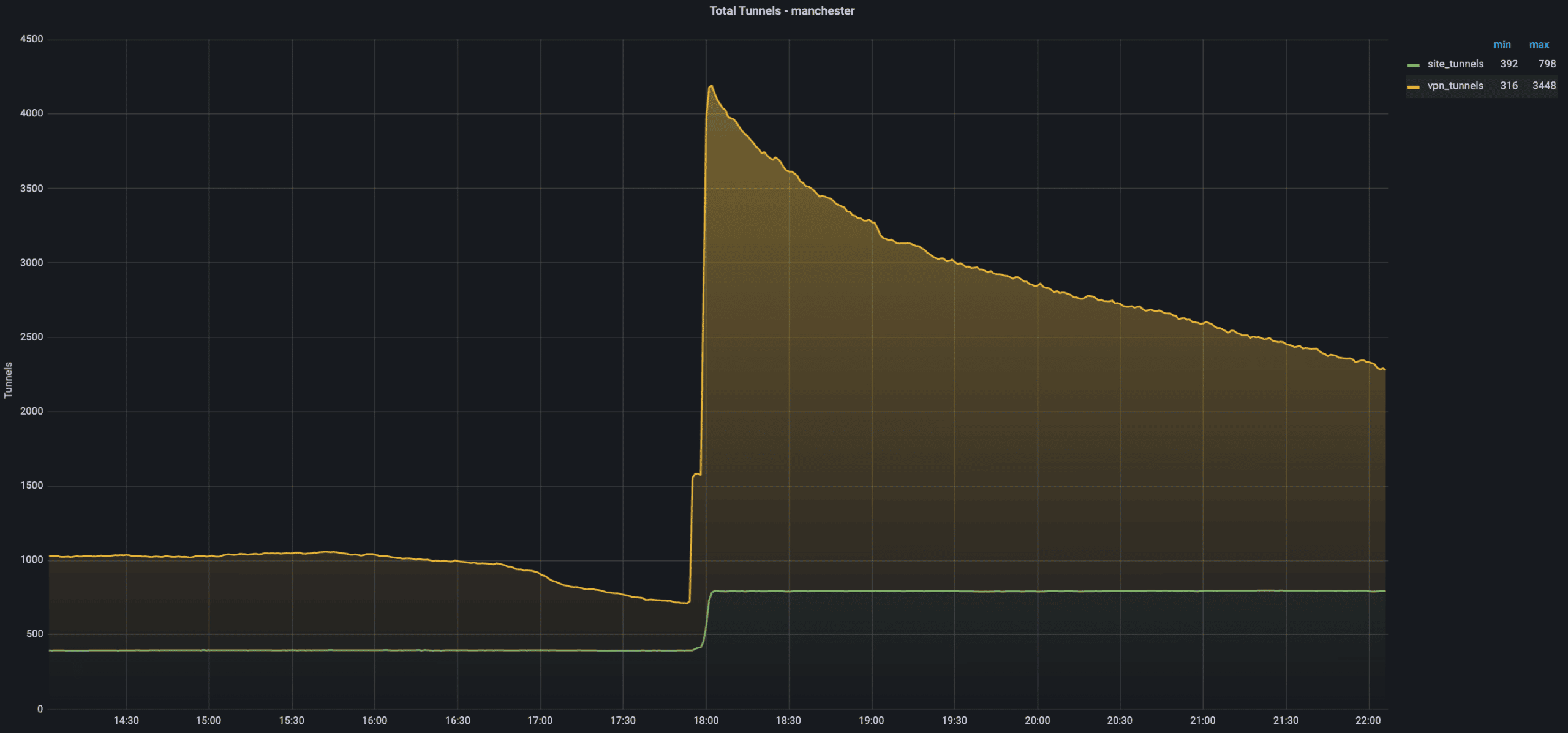
There were a few exceptions to the quick transition from the London PoP to another. Some Cato customers, for whatever reason, choose to use a firewall to route traffic rather than a Cato Socket. In this case, they create a tunnel using IPsec to a specific PoP location. Cato recommends – and certainly best practices dictate – that the customer create two IPsec links, each one going to a different location. In this case, one link operates as a failover alternative to the other.
We had a handful of customers using firewall configurations with two tunnels going only to the London site. When London went down, so did their network connections—both of them. We could see on our dashboard exactly which customers were affected in this way and reached out to them to configure another tunnel to a location such as Manchester or Amsterdam. Here’s a comment from one such customer:
“When dealing with the worst possible situation and outage, you have provided excellent support and communications, and I am grateful.”
Lessons We Took Away from This Incident
At Cato, we view every incident as an opportunity to strengthen our service for the next inevitable event. We think about rare case scenarios that can happen and run retrospective meetings from which we identify the next actions that need to be taken to ensure the resiliency of our solution.
When we built a service with an SLA of five 9’s this is the commitment we made to our customers. When we carry their traffic, we know that every second counts. This requires ongoing investments and thinking about how things could go wrong and what we have to do to ensure that our service will be up. Part of that is what drives our continued investment in opening new PoPs across the globe and often within the existing countries. The density of coverage, not just the number of countries, is important when considering the resiliency of a SASE service.
Who would ever have thought that a major datacenter in the heart of London would lose access to every power source it has? Well, Cato considered such a scenario and prepared for it, and I’m pleased to say that this unexpected test showed our service has the resiliency and scale to continue as our customers expect it to.
Related Articles
What Consistent Leadership Across SSE, SD-WAN, and SASE Signals

Cato Joins OpenAI’s Trusted Access for Cyber (TAC) to Advance AI-Driven Defense

Cato’s ASK AI Assistant: Turning Complex Network Operations Into Simple Conversations





