
Shrinking a Machine Learning Pipeline for AWS Lambda

|
Listen to post:
Getting your Trinity Audio player ready...
|
Using AWS Lambda for deploying machine learning algorithms is on the rise. You may ask yourself, “What is the benefit of using Lambda over deploying the model to an AWS EC2 server?” The answer: enabling higher throughput of queries. This scale-up may challenge an EC2 server, but not Lambda. It enables up to 2,000 parallel queries.
However, troubles begin when it comes to the Lambda deployment package. The code, dependencies and artifacts needed for the application comprising the nearly 500MB deployment package must sum up to no more than 256MB (unzipped).
SPACE: The Key to Unlocking the True Value of SASE (eBook)From 500MB to 256MB, that’s a significant difference.
Let me show you how our team approached this challenge, which ended with deploying a complex machine learning (ML) model to AWS Lambda.
The Problem: The Size of the Deployment Package
We wanted to deploy a tree-based classification model for detecting malicious Domains and IPs. This detection is based on multiple internal and external threat intelligence sources that are transformed into a feature vector. This feature vector is fed into the classification model and the model in turn, outputs a risk score. The pipeline includes the data pre-processing and feature extraction phases.
Our classification tree-based model required installing Python XGBoost 1.2.1 that requires 417MB. The data pre-processing phase requires installing Pandas 1.1.4 that requires 41.9MB and Numpy 1.19.4 that costs an additional 23.2MB. Moreover, the trained pickled XGBoost model weighs 16.3MB. All of which totals 498.4MB.
So how do we shrink all of that with our code, to meet the 256MB deployment package limitation?
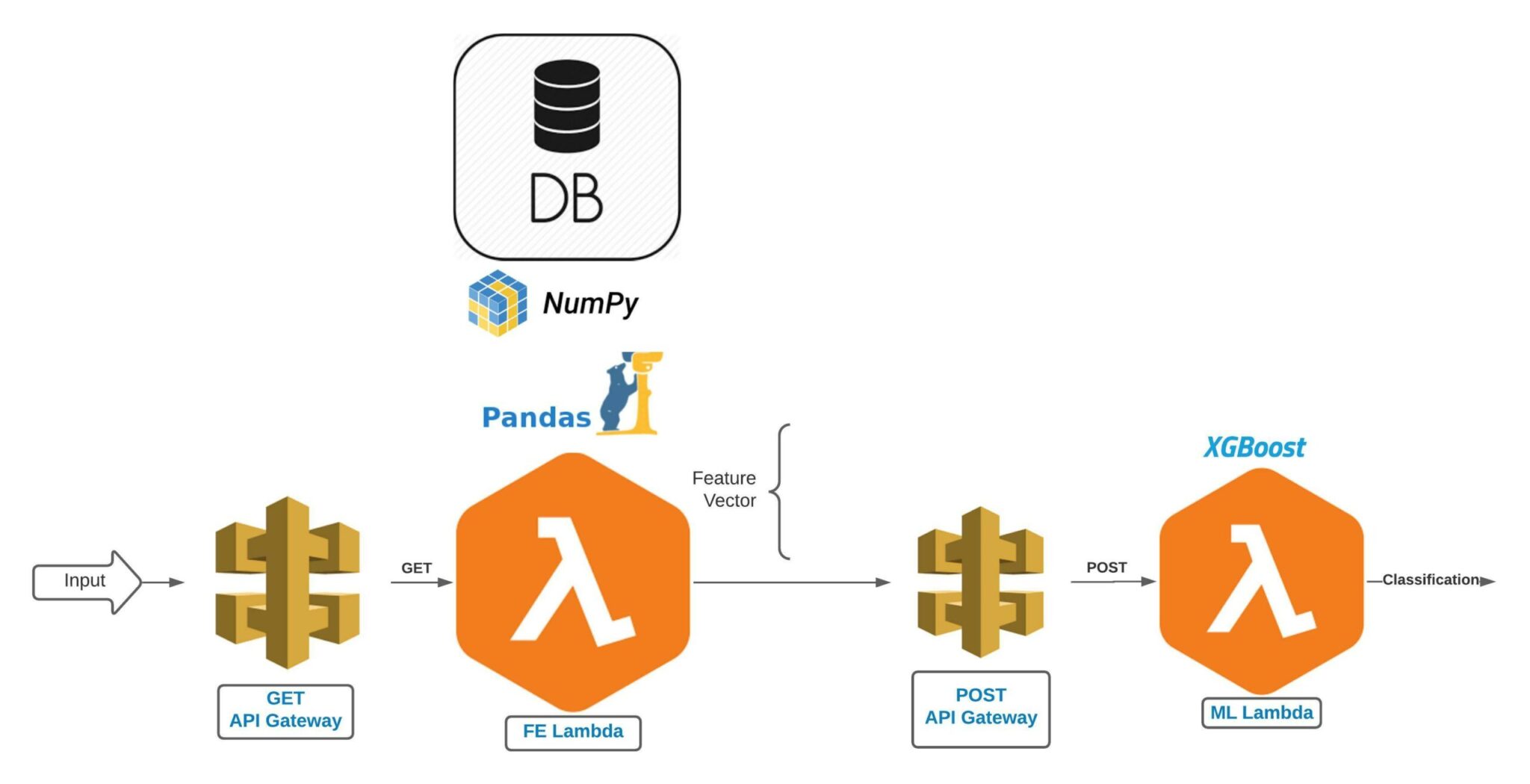
ML Lambda
The first step is to shrink the XGBoost package and its dependencies, do we really need all the 417MB of that package?
Removing distribution Info directories (*.egg-info and *.dist_info) and testing directories together with stripping the .so files will reduce the XGBoost package space usage to 147MB. Summing up the packages with joblib, numpy and scipy results in 254.2MB, which is suitable for a Lambda layer.
This shrunken Lambda layer is going to serve as our first Lambda function which mainly queries the ML model with a feature vector and returns a classification scoring. The feature vector is generated from multiple internal and external threat intelligence data sources. The data is pre-processed and transformed into decimal values vector, and then fed to our classification model, generating a risk score. But who is responsible for generating this feature vector?
Feature Extraction Lambda
To generate the feature vector, you need to build a feature extraction pipeline. Since we’re out of space in the first Lambda function, we’ll create another Lambda function for it. Feature Extraction (FE) Lambda gets an entity as an input, queries the relevant sources, then weighs and transforms this data to a feature vector. This feature vector is the input for the first Lambda function, which in turn – returns the classification result.
The FE Lambda function imports some third-party packages for the data retrieval. Also, since we’ve gathered some information from various databases, we’ll need Pymysql and Pymongo. Finally, for the data cleaning and feature extraction we’ll need Pandas and Numpy.
All this sums up to 111MB, which is clearly suitable for the 256MB per Lambda deployment package limitation.
But you may ask yourself, where is the model? Don’t you add it to the deployment package? Actually, it’s not needed. Since the model is trained once and then executed on each function call, we can store the Pickled- trained model on S3 and download it using boto3 on each function call. That way we separate the model from the business logic, and we can swap between models easily without changing the deployment package.
Lambda Functions Inter-communication
Another concern is the two Lambda functions’ inter-communication process. We’ve used the REST API in the API Gateway service, using GET for the FE Lambda – since its input is just a single string entity. For the ML Lambda we’ve created a REST API using POST – since this Lambda input is a long feature vector.
That way, the FE Lambda gets an entity as an input and it queries third-party data sources. After the data retrieval is finished, it cleans the data and extracts the feature vector, which in turn is sent to the ML Lambda for prediction.
Modularity
Another positive side effect of splitting the process into two Lambda functions, is modularity. This split enables you to integrate additional ML models to work in parallel to the original ML model.
Let’s assume we decide to transform our single ML model pipeline into an ensemble of ML models, which output a result based on the aggregation of their stand-alone result. It becomes much easier when the FE pipeline is totally excluded from the ML pipeline, and that modularity can save much effort in the future.
Wrapping up
So, we have two main conclusions. The first step of moving a ML pipeline to a serverless application is understanding the hardware limitations of the platform.
The second conclusion is that these limitations may require ML model adaptations and must be considered as early as possible.
I hope you find the story of our struggles useful when moving your ML to a serverless application, the efforts needed for such a transition will pay off.
Related Articles
Cato CTRL™ Threat Research: New Vulnerabilities in NVIDIA NeMo and Meta PyTorch Enable Full System Compromise


WebPromptTrap – New Indirect Prompt Injection Vulnerability in BrowserOS


Securing the AI Browser Revolution: How Cato Helps Mitigate Risks in OpenAI Atlas




