Inside Cato: How a Data Driven Approach Improves Client Identification in Enterprise Networks


|
Listen to post:
Getting your Trinity Audio player ready...
|
Identification of OS-level client types over IP networks has become crucial for network security vendors. With this information, security administrators can gain greater visibility into their networks, differentiate between legitimate human activity and suspicious bot activity, and identify potentially unwanted software. The process of identifying clients by their network traces is, however, very challenging. Most of the common methods being applied today require a great deal of manual work, advanced domain expertise, and are prone to misclassification. Using a data-driven approach based on machine learning, Cato recently developed a new technology that addresses these problems, enabling accurate and scalable identification of network clients.
Going “old school” with manual fingerprinting
One of the most common methods to passively identify network clients, without requiring access to either endpoint, is fingerprinting. Imagine you are a police investigator arriving at a crime scene for forensics. Lucky for you, the suspect left an intact fingerprint. Since he is a well-known criminal with previous offenses, his fingerprints are already in the police database, and you can use the one you found to trace back to him. Like humans, network clients also leave unique traces that can be used to identify them. In your network, combinations of attributes such as HTTP headers order, user-agents, and TLS cipher suites, are unique to certain clients.
Ransomware Chokepoints: Disrupt the Attack | Watch WebinarIn recent years, fingerprints relying solely on unsecured network traffic attributes (e.g., the HTTP user-agent value) have become obsolete, since they are easy to spoof, and are not applicable when using secured connections. TLS fingerprints, that rely on attributes from the Client Hello message of the TLS handshake, on the other hand, do not suffer from these drawbacks and are slowly gaining larger adaptation from security vendors.
Below is an example of a TLS fingerprint that identifies a OneDrive client.

Caption: TLS header fingerprint of a One Drive client (source)
However, manually mapping network clients to unique identifiers is not a simple task; It requires in-depth domain knowledge and expertise. Without them, the method is prone to misclassifications. In a shared community effort to address this issue, some open-source projects (e.g. sslhaf and JA3) were created, but they provide low coverage and are not updated frequently.
An even greater issue with manual fingerprinting is scalability. Accurately classifying client types requires manually analyzing traffic captures, a labor-intensive process that does not scale for enterprise networks.
Taking such an approach at Cato wasn’t feasible. Each day the Cato SASE Cloud must inspect millions of unique TLS handshake values. The large number of values is due not only to the number of network clients connected to Cato SASE Cloud but also to the number of different versioning and updates that alter the TLS behavior of each client. Clearly, we needed a better solution.
Clustering – An automated and robust approach
With great amounts of data, comes great amounts of capabilities. With the use of machine learning clustering algorithms, we’ve managed to reduce millions of unique TLS handshake values to a subset of a few hundred clusters, representing unique network clients that share similar values. After creating the clusters, a single fingerprint can be generated for each one, using the longest common substring (LCS) from the Client Hello message of all the samples in the cluster. Finding the common denominator of several samples makes the approach more robust to small variations in the message values.
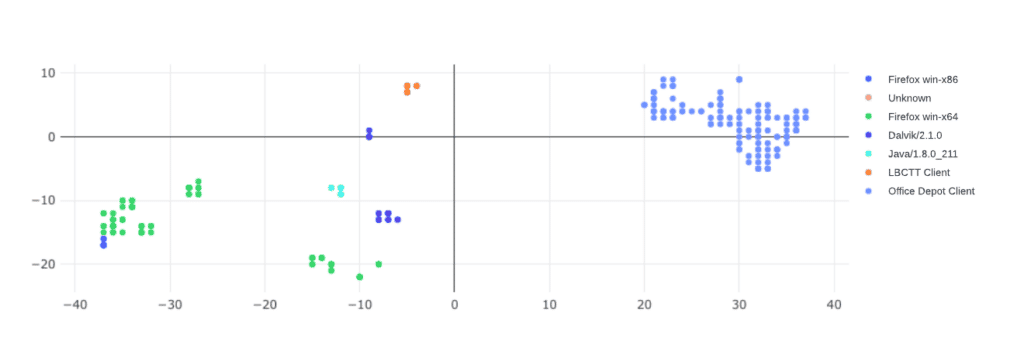
Caption: Similar values from the TLS Client Hello message are clustered together and the LCS is used to generate a fingerprint. Each colored cluster represents a different client.
The next step of the process is to identify and label the client of the fingerprint. To do so, we search for the fingerprint in our data lake, containing terabytes of daily network flows generated from different clients, and look for common attributes such as domains or applications contacted, and HTTP user-agent (visible from TLS traffic interception and inspection).
For example, in the plot above, a group of TLS network flows, containing similar Client Hello messages, were clustered together by the algorithm (see the 3-point “Java/1.8.0_211” cluster colored in light blue). The resulting TLS fingerprint matched a group of inspected TLS flows in our data lake, with visible HTTP headers; all of which had a common user-agent that belongs to the Java Standard Library; a library used to perform HTTP requests.
Wrapping up
Accurately identifying client types has become crucial for network security vendors. With this new data-driven approach, we’ve managed to develop a fully automated and continuous pipeline that generates TLS fingerprints. The new method scales to large enterprise networks and is more robust to variation in the client’s network activity.
Related Articles
Mythos and Beyond: Cato Addresses the Generational Shift in Cyber Threats with Agentic Security Researchers


How Cato Turns Identity Noise Into High-Confidence Detections


Legacy Partnerships Are Costing You Customers: Power Up with Cato's Private PoP