
Lessons I’ve Learned While Scaling Up a Data Warehouse

|
Listen to post:
Getting your Trinity Audio player ready...
|
Building and maintaining a data warehouse is not an easy task, many questions need to be answered to choose which technology you’re going to use. For example:
- What are your use cases? These may change over time, for instance involving on-demand aggregations, ease of search, and data retention.
- What type of business-critical questions will you need to answer?
- How many users are going to use it?
In this post, we will cover the main scale obstacles you might face when using a data warehouse. We’ll also cover what you can do to overcome these challenges in terms of technological tools and whether it pays to build these tools in-house or to use a managed service. Addressing these challenges could be very important for a young startup, whose data is just starting to pile up and questions from different stakeholders are popping up, or for an existing data warehouse that has reached its infrastructure limit.
Migrating your Datacenter Firewall to the Cloud | WhitepaperComparing ELK vs Parquet, S3, Athena and EMR in AWS
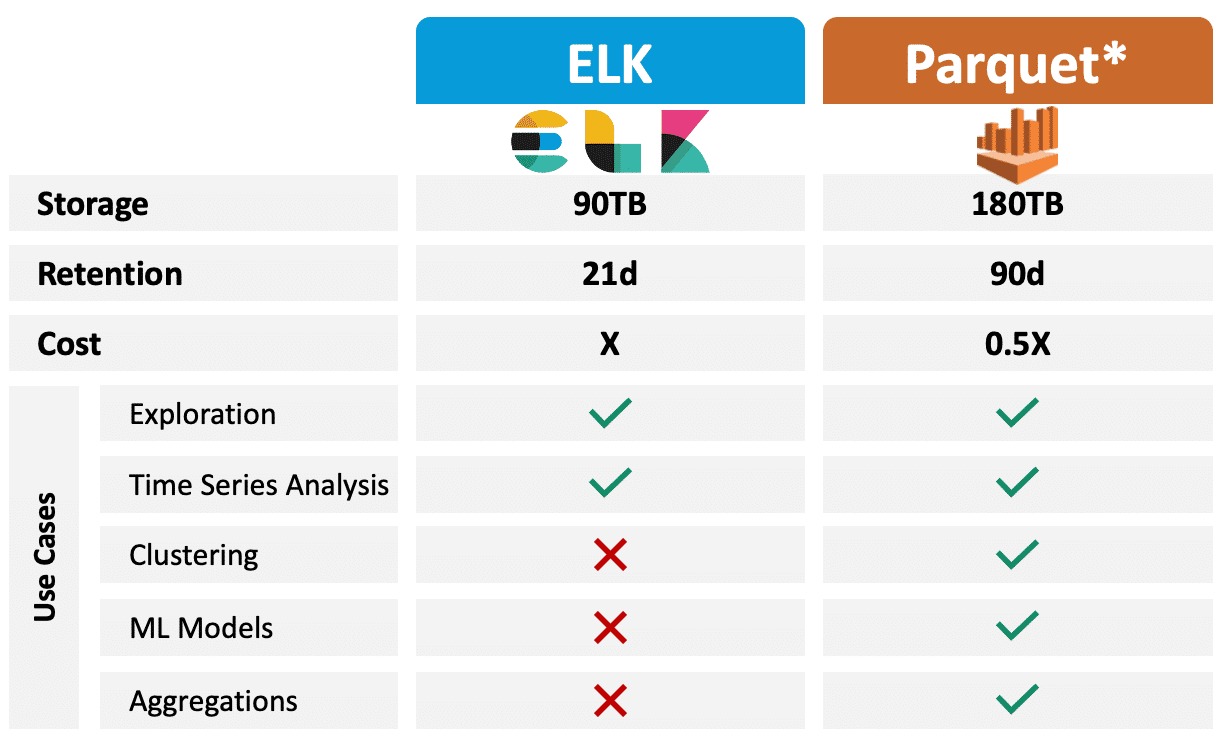
Just to set the scene, while using ELK we got to the point of having a 90TB cluster of multiple data nodes, master, and coordinator. These 90TB represented 21 days of data. Aggregations took a long time to run and most of the time failed completely. ELK’s disks were the best, yet most expensive AWS had to offer.
Moving to Parquet, S3, Athena and EMR allowed us to save more than double, in terms of timeframe, for the same storage volume, while dramatically reducing costs and extending our abilities. I will explain more about the differences between these technologies and why you should consider choosing one and not another.
Self-Managed ELK – The Classic Choice
Many will choose ELK as their data warehouse technology. The initial setup in this case is fairly easy, as well as data ingestion. Using Kibana can help you explore the data, its different data types and values, and create informative aggregate dashboards to present ideas and stats. But when it comes to scale, using this technology can become challenging and create a great deal of overhead and frustration.
Scale Problems
The problem with ELK starts with aggregations. As data volumes grow, aggregations can become heavy tasks. This is because Elasticsearch calculates aggregations on a single node, making it harder for ELK to deal with large amounts of data. This means that if you need aggregate tables over time, you must aggregate during processing.
Overhead of managing a cluster on your own
As data volumes grow, managing a cluster on your own can become a very big headache. It requires manual work from your SRE team and sometimes can lead to the worst – downtime. Managing a cluster on your own may include the following:
- Managing the disks and their volume types
- Adding capacity requires additional nodes be added to your ELK cluster
- In accordance with your original partitioning methods, data can become skewed. This means more data will reach a specific node as opposed to another and it means you will have to manually configure data balancing between different data shards
Using a managed service, and not a self-managed one, can be considered expensive, but it can also save you these efforts and their price (financial or mental).
The Alternative: Parquet and Why It’s So Important
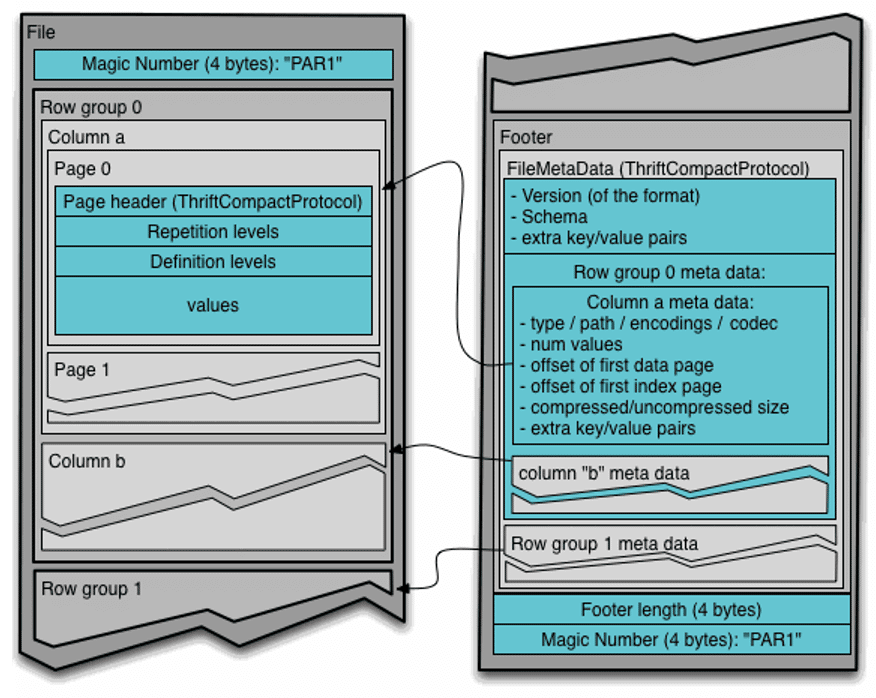
When it comes to scale, Parquet file format can save the day. It is a columnar file format, so you can read every column on its own instead of having to read the entire file. Reading just a column allows the search engine to invest fewer resources when scanning less data.
Parquet is also compressed, meaning you can get to as low as 10% of a normal JSON file, which is very important when it comes to storage. Scanning a Parquet file by the query engine does not mean the query engine has to uncompress the entire file in advance – compression is done on every column on its own. Your storage can stay with compressed Parquet files, and the query engine will handle it in accordance with the selected columns.
For us at Cato Networks, moving to Parquet meant that we could use the same storage volume and store up to three times more data in terms of timeframe than we could when using ELK, reducing our costs by 50%.
Many distributed query engines now support Parquet. For instance, you can find Presto and Druid applicable for Parquet usage.
Our Approach: S3, Athena, and EMR
We gave up our self-managed ELK for a combination of S3 with Athena and EMR in AWS. We converted our data from JSON files that were headed towards ELK to Parquet and uploaded them to S3. AWS then offers a few methods on how to access the data.
Athena
Athena is a managed query service offered by AWS. It uses Presto as an underlying engine, and lets you query files you store on S3. Athena can also work with many file formats like CSV or JSON, but these can lead to a serialization overhead.
Using Athena along with Parquet means you can expect optimal query results. Every query you execute will get the computing power resources it needs. The data will be automatically distributed among nodes behind the scenes, so you don’t have to worry about configuring anything manually.
EMR
EMR is another managed service offered by AWS that lets you instantly create clusters to execute Spark applications, without any configuration overhead. Since your data is on S3, it even saves you the overhead of configuring and managing HDFS storage.
Using EMR is a great method if you’ve ever considered Spark but couldn’t or wouldn’t invest the resources required to bring up such a heavy cluster.
Being able to use Spark is a great addition to a data warehouse, however it is relatively hard or even impossible while having your data saved in Elasticsearch storage.
Utilization
Athena and EMR can sometimes be used for the same use cases, but they have many differences. When you are using EMR data persistence is available on disk or in memory, to save reading the data more than once. This is not an option in Athena, so multiple queries will result in recurring API calls for the same Parquet files.
Another difference between the two, in terms of usability, is that while using Athena can be done using SQL syntax only, using Spark and EMR requires writing code. It can be either Python, JAVA, or Scala, but all those require a wider context than SQL.
Additionally, Spark requires some configuration in terms of nodes, executors, memory, etc. These configurations, if not selected correctly, can lead to OOM. Athena queries can also end with an “exhaustion” message, but this only means you need to scan less data – there is nothing else you can do about it.
Wrapping Up
While using all of the above, we faced many scaling problems, extended our research and data mining capabilities, and saved many hours of manual work thanks to a fully working managed service.
We can store our data for longer periods, use old data only when needed and do practically whatever we want with the newest data at all times.
Moving to a new technology and neglecting old code and infrastructure can be considered challenging. It puts in question the actual reason manual work was done in the first place. Although challenging, it is an effort worth finding resources for. The technology you use should evolve together with the scale of your data.
Related Articles
Beyond Patch SLAs: Continuous Protection in the Frontier AI Era

OpenClaw: Cato Governance Controls and Sector Exposure Insights from the Cato SASE Platform


Global Campaign Discovered with Modbus PLCs Targeted and China-Geolocated Infrastructure Observed




